ในยุคที่เทคโนโลยีปัญญาประดิษฐ์ (AI) กำลังพัฒนาอย่างรวดเร็ว โมเดลภาษาขนาดใหญ่ (Large Language Model – LLM) ได้กลายเป็นเครื่องมือสำคัญในการประมวลผลภาษาธรรมชาติ (Natural Language Processing – NLP) ซึ่งมีความสามารถในการสร้างข้อความที่ใกล้เคียงกับภาษามนุษย์ เช่น การเขียนบทความ การตอบคำถาม หรือการแปลภาษา การพัฒนา LLM ไม่ได้มุ่งเน้นเพียงการสร้างโมเดลที่ทำงานได้ดีบนข้อมูลที่มีอยู่เท่านั้น แต่ยังต้องให้ความสำคัญกับการประเมินความสามารถของโมเดลด้วยการวัดประสิทธิภาพ (Evaluation Metrics) เพื่อให้ผู้พัฒนาสามารถปรับปรุงโมเดลให้มีประสิทธิภาพที่ดียิ่งขึ้นในอนาคต
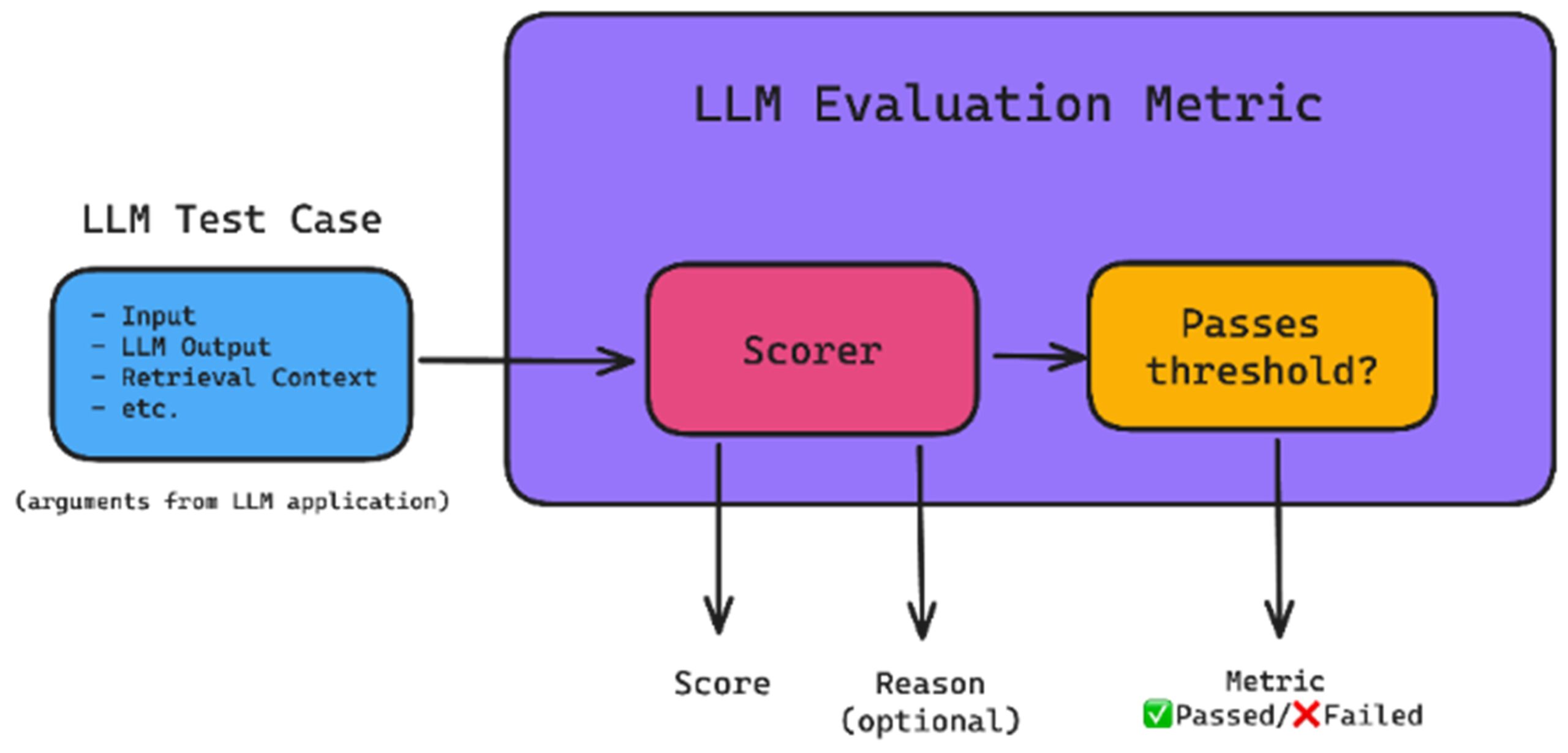
รูปที่ 1 ภาพรวมระบบการวัดประสิทธิภาพโมเดลภาษาขนาดใหญ่ [1]
ในบทความนี้ จะเริ่มด้วยการเล่าถึงความสำคัญของการวัดประสิทธิภาพ LLM ประเภทของการคำนวณค่าการวัดประสิทธิภาพ LLM และการนำไปประยุกต์ใช้งานจริงและข้อควรระวัง
ความสำคัญของการวัดประสิทธิภาพ LLM
การวัดประสิทธิภาพของโมเดลภาษาขนาดใหญ่เป็นสิ่งสำคัญด้วยเหตุผลหลายประการ เช่น
- การปรับปรุงโมเดล: การวัดประสิทธิภาพช่วยระบุจุดอ่อนของโมเดลอย่างชัดเจน ทำให้ผู้พัฒนาสามารถปรับปรุงและแก้ไขโมเดลให้ดียิ่งขึ้น
- การสร้างความมั่นใจให้ผู้ใช้: การประเมินที่แม่นยำทำให้มั่นใจได้ว่าโมเดลให้ข้อมูลที่ถูกต้องและน่าเชื่อถือ
- การลดความเสี่ยง: ช่วยป้องกันการใช้โมเดลที่อาจสร้างข้อมูลที่ไม่ถูกต้องหรือมีอคติ ซึ่งอาจก่อให้เกิดผลกระทบที่ไม่พึงประสงค์
หากการวัดประสิทธิภาพไม่ถูกต้อง อาจนำไปสู่การตัดสินใจที่ผิดพลาดได้ เช่น
- การให้ข้อมูลที่ไม่ถูกต้อง: ซึ่งอาจทำให้ผู้ใช้สูญเสียความเชื่อมั่นในระบบ
- การสร้างเนื้อหาที่ไม่เหมาะสม: ซึ่งอาจทำให้เกิดปัญหาทางจริยธรรมและกฎหมาย
- การขาดประสิทธิภาพ: ทำให้โมเดลไม่สามารถตอบสนองต่อความต้องการของผู้ใช้ได้อย่างเต็มที่
ประเภทของการคำนวณค่าการวัดประสิทธิภาพ LLM
การประเมินผลของ LLM สามารถแบ่งออกเป็น 3 ประเภทหลัก ได้แก่
1 การวัดเชิงสถิติ (Statistical Scorers)
การวัดเชิงสถิติเป็นการใช้วิธีการทางสถิติเพื่อประเมินความคล้ายคลึงกันของข้อความที่โมเดลสร้างขึ้นกับข้อความที่มนุษย์สร้าง ข้อดีของวิธีนี้คือ เข้าใจง่าย ใช้กันแพร่หลาย ใช้ทรัพยากรน้อย และประเมินผลได้รวดเร็ว แต่ข้อเสียคือไม่คำนึงถึงความหมายเชิงบริบทหรือความเข้าใจที่ลึกซึ้ง เช่น
- BLEU (Bilingual Evaluation Understudy): เป็นเครื่องมือที่ใช้ในการประเมินการแปลภาษา โดยวัดความคล้ายคลึงระหว่างประโยคที่โมเดลสร้างขึ้นกับประโยคที่มนุษย์สร้าง โดยการนับการเกิดของ n-gram (กลุ่มของ n คำที่ต่อเนื่องกัน) ในการวัดความคล้ายคลึงกัน ยิ่งคำตรงกันมาก BLEU ยิ่งสูง
- ROUGE (Recall-Oriented Understudy for Gisting Evaluation): ใช้ในการประเมินผลการสรุปข้อความ (summarization) โดยวัดการครอบคลุม (recall) ของ n-gram ระหว่างข้อความที่โมเดลสร้างและข้อความสรุปของมนุษย์ ช่วยให้เข้าใจว่าข้อความที่โมเดลสร้างมีความคล้ายคลึงกับการสรุปของมนุษย์มากน้อยเพียงใด ยิ่งโมเดลสรุปข้อความได้ดีมาก ROUGE ยิ่งสูง
- Levenshtein Distance: วัดความคล้ายคลึงระหว่างสองข้อความ โดยอิงจากจำนวนการแก้ไขที่ต้องทำเพื่อเปลี่ยนข้อความหนึ่งไปเป็นอีกข้อความหนึ่ง เช่น การเพิ่ม ลบ หรือแทนที่อักขระ Levenshtein Distance จะบ่งบอกถึงจำนวนการกระทำที่ต้องทำเพื่อแปลงข้อความหนึ่งไปเป็นอีกข้อความหนึ่ง ถ้ามีค่าน้อย หมายความว่าข้อความสองชุดนั้นคล้ายคลึงกันมาก
2 การวัดด้วยโมเดล (Model-Based Scorers)
การวัดด้วยโมเดลใช้ LLM เองในการประเมินผล ซึ่งสามารถให้ผลที่แม่นยำและใกล้เคียงความจริงมากกว่า แต่มีความซับซ้อนและต้องการการประมวลผลมากขึ้น เช่น
- GPTScore: ใช้ความน่าจะเป็นในการสร้างข้อความเป้าหมายเป็นตัวชี้วัด โดยวัดความน่าจะเป็นที่โมเดลจะสร้างข้อความที่ต้องการ คำนวณโดยอิงจากค่าความน่าจะเป็นของข้อความที่โมเดลสร้าง ถ้ามีค่า GPTScore สูง แสดงว่าโมเดลสามารถสร้างข้อความที่มีความใกล้เคียงกับข้อความเป้าหมายได้อย่างแม่นยำ
- G-Eval: ใช้กระบวนการที่เรียกว่า “chain of thoughts” เพื่อสร้างขั้นตอนการประเมินผล โดยให้โมเดลสร้างชุดของขั้นตอนการประเมินก่อนที่จะใช้ขั้นตอนเหล่านั้นในการกำหนดคะแนนสุดท้าย การประเมินความสอดคล้องของผลลัพธ์จะถูกกำหนดโดยการสร้างคำถามที่มีเกณฑ์การประเมินและข้อความที่ต้องการประเมิน ผลลัพธ์จะอิงจากกระบวนการคิดของโมเดล
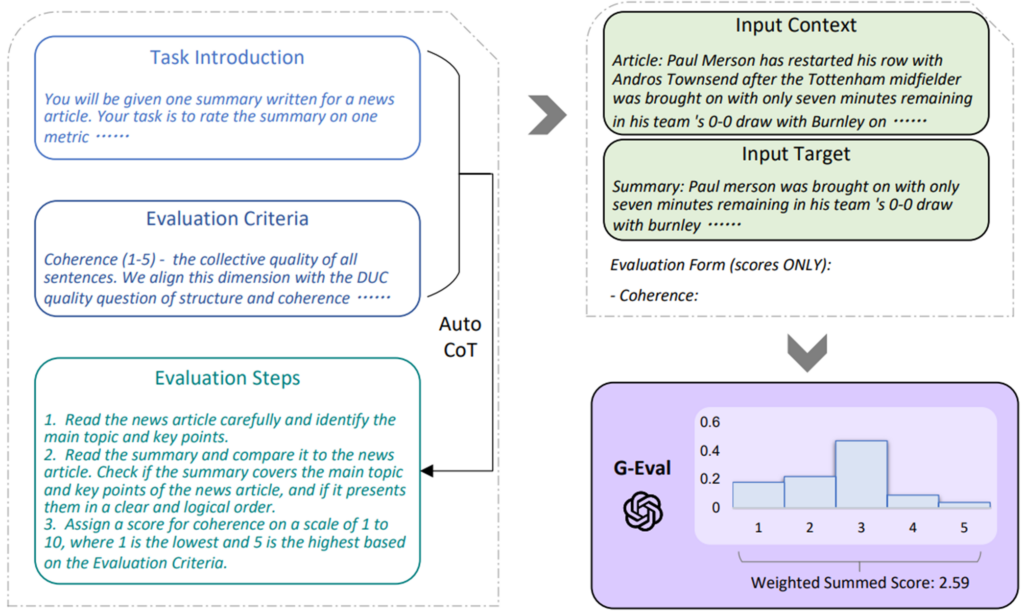
รูปที่ 2 แสดงกระบวนการ G-EVAL: LLM สร้าง chain of thoughts จากข้อมูลงานและเกณฑ์ แล้วใช้ผลลัพธ์นี้ประเมินแบบผ่านการใช้คำสั่ง (prompt) จากนั้นคำนวณคะแนนสุดท้ายโดยใช้ผลรวมถ่วงน้ำหนักด้วยความน่าจะเป็นของคะแนนผลลัพธ์ [2]
3 การผสมผสานระหว่างการวัดเชิงสถิติและโมเดล (Combining Statistical and Model-Based Scorers)
การผสมผสานระหว่างการวัดเชิงสถิติและการวัดด้วยโมเดลช่วยให้ได้ผลลัพธ์ที่มีความแม่นยำและเชื่อถือได้มากขึ้น โดยคำนึงถึงความหมายเชิงบริบท เช่น
- BERTScore: ใช้โมเดลภาษาที่ผ่านการฝึกฝนมาแล้ว เช่น BERT ในการประเมินความคล้ายคลึงระหว่างเวกเตอร์ของคำในข้อความที่สร้างขึ้นกับเวกเตอร์คำในข้อความอ้างอิง ยิ่งค่า BERTScore สูงมากเท่าใด ข้อความที่โมเดลสร้างก็ยิ่งมีความใกล้เคียงกับข้อความที่ต้องการมากขึ้นเท่านั้น
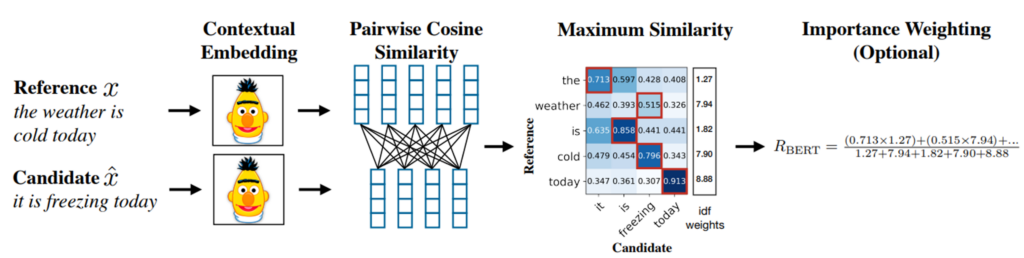
รูปที่ 3 แสดงการประเมินความคล้ายคลึงระหว่างข้อความอ้างอิงและข้อความที่สร้างขึ้น โดยใช้ BERT embeddings เพื่อแทนคำในรูปแบบเวกเตอร์ และใช้การคำนวณค่าความคล้ายคลึง (cosine similarity) ระหว่างคำในแต่ละประโยค จากนั้นจับคู่คำที่มีความคล้ายคลึงกันแบบ greedy matching (แสดงด้วยกรอบสีแดง) และอาจถ่วงน้ำหนักด้วย IDF เพื่อเพิ่มความแม่นยำ (เป็นตัวเลือก) [3]
การนำไปประยุกต์ใช้งานจริงและข้อควรระวัง
เพื่อให้การวัดประสิทธิภาพของโมเดลภาษาขนาดใหญ่มีความครอบคลุมและแม่นยำมากขึ้น ควรพิจารณาวิธีการที่หลากหลายดังนี้:
- การคำนวณค่าการวัดประสิทธิภาพหลายประเภทร่วมกัน: การนำการวัดเชิงสถิติ เช่น BLEU และ ROUGE มาร่วมกับการผสมผสานระหว่างการวัดเชิงสถิติและโมเดล เช่น BERTScore จะช่วยให้การประเมินผลมีความครอบคลุมมากขึ้น ได้รับภาพรวมที่ชัดเจนเกี่ยวกับความสามารถของโมเดล และลดความเสี่ยงในการ overfitting ของผลการวัดได้
- การประเมินความทนทานของโมเดล: ควรพิจารณาประสิทธิภาพของโมเดลภายใต้สถานการณ์ต่าง ๆ เช่น ข้อความที่มีโครงสร้างที่ซับซ้อนหรือมีการใช้ภาษาที่ไม่เป็นทางการ เพื่อให้มั่นใจว่าโมเดลสามารถทำงานได้ดีในสภาพแวดล้อมที่หลากหลาย การทดสอบโมเดลภายใต้เงื่อนไขที่หลากหลายจะช่วยให้เราเข้าใจความสามารถและข้อจำกัดของโมเดลได้อย่างครอบคลุม
- การประเมินด้วยมนุษย์: การเสริมการประเมินด้วยมนุษย์เข้าไปในการประเมินผลจะช่วยให้ได้ข้อมูลที่ละเอียดและเชิงคุณภาพมากขึ้น การใช้ผู้เชี่ยวชาญหรือผู้ใช้จริงในการประเมินความถูกต้อง ความเป็นธรรมชาติ และความเหมาะสมของข้อความที่โมเดลสร้างขึ้น สามารถจับข้อผิดพลาดที่การวัดประสิทธิภาพอาจไม่สามารถตรวจจับได้ การประเมินด้วยมนุษย์จะช่วยเสริมความเชื่อมั่นในความแม่นยำของผลลัพธ์ที่ได้จากการวัดเชิงสถิติและโมเดล
บทสรุป
การวัดประสิทธิภาพของโมเดลภาษาขนาดใหญ่เป็นกระบวนการที่สำคัญและจำเป็นในการพัฒนา LLM ที่มีคุณภาพ การใช้วิธีการวัดที่หลากหลายและการประเมินผลอย่างครอบคลุมจะช่วยให้ได้โมเดลที่มีประสิทธิภาพและสามารถตอบสนองต่อความต้องการของผู้ใช้ได้อย่างมีประสิทธิภาพในอนาคต
เอกสารอ้างอิง
- LLM Evaluation Metrics: The Ultimate LLM Evaluation Guide (https://www.confident-ai.com/blog/llm-evaluation-metrics-everything-you-need-for-llm-evaluation)
- A list of metrics for evaluating LLM-generated content (https://learn.microsoft.com/en-us/ai/playbook/technology-guidance/generative-ai/working-with-llms/evaluation/list-of-eval-metrics)
- G-EVAL: NLG Evaluation using GPT-4 with Better Human Alignment (https://arxiv.org/pdf/2303.16634)
- BERTScore: Evaluating Text Generation with BERT (https://arxiv.org/pdf/1904.09675)
บทความโดย ธนกร ทำอิ่นแก้ว
ตรวจทานและปรับปรุงโดย ดร.ขวัญศิริ ศิริมังคลา






Senior Data Management Training and Development Specialist at Big Data Institute (Public Organization), BDI




