จากบทความที่ผ่านมาได้มีการกล่าวถึง การวิเคราะห์ตะกร้าสินค้า (Market Basket Analysis) ด้วยการสร้างกฎความสัมพันธ์ หรือ Association Rule ไปแล้ว พร้อมกับอธิบายถึงแนวคิดพื้นฐานที่ถูกใช้ใน Association Rule ได้แก่ Support, Confidence และ Lift หากใครยังไม่รู้จักคำเหล่านี้ว่าหมายถึงอะไร สามารถเข้าไปอ่านในบทความ มาทำความรู้จัก Association Rule: เครื่องมือเพื่อการวิเคราะห์ตะกร้าตลาด กัน! ได้เลย ในส่วนของบทความนี้จะเป็นภาคต่อที่จะพูดถึงหนึ่งในขั้นตอนวิธีในการสร้างกฎความสัมพันธ์ โดยวิธีการที่เป็นที่นิยม เป็นเทคนิคที่ชื่อว่า Apriori Algorithm นั่นเอง
เริ่มต้นขอเกริ่นก่อนว่ากระบวนการในการหากฎความสัมพันธ์ (Association Rule Mining) นั้นสามารถแบ่งปัญหาออกเป็น 2 งานย่อยด้วยกัน ได้แก่
1. Frequent Itemset Generation
คือการหา itemsets ที่ผ่านเกณฑ์ minimum support ซึ่งจะเรียก itemsets เหล่านี้ว่าเป็น “Frequent Itemsets”
2. Rule Generation
คือการหากฎความสัมพันธ์ที่มีค่า Confidence หรือ Lift สูง หรือที่เรียกว่า “Strong Rules” ซึ่งกฎเหล่านี้จะถูกสร้างมาจาก Frequent Itemsets ที่ได้มาจากขั้นตอนก่อนหน้า
ในสองกระบวนการนี้ Apriori Algorithm จะเข้ามาเป็นส่วนหนึ่งในการช่วยเพิ่มประสิทธิภาพและความเร็วของการสร้างกฎความสัมพันธ์ ที่มีจำนวน items และ transactions จำนวนมาก สำหรับในบทความนี้จะขอโฟกัสไปที่การประยุกต์ใช้ Apriori Algorithm ในขั้นตอนการหา Frequent Itemsets กันก่อน
จากบทความก่อนหน้าเราพอทราบมาแล้วว่า หากมีสินค้าอยู่ N ชิ้น จะมี itemsets ที่เป็นไปได้ถึง 2N – 1 แบบ ซึ่งจะเห็นว่าจำนวน itemsets มีการเพิ่มแบบ exponential ตามจำนวน items ที่เพิ่มขึ้น สมมติ ถ้าร้านเรามีสินค้าทั้งหมด 4 items ได้แก่ apple, banana, water และ bread จะสามารถสร้าง itemsets ที่เป็นไปได้ทั้งหมด 24-1 = 15 itemsets ที่ประกอบไปด้วย itemsets ที่มีสินค้าแค่ 1 ชิ้น จนถึง itemsets ที่มีสินค้าครบ 4 ชิ้น ดังรูปด้านล่าง
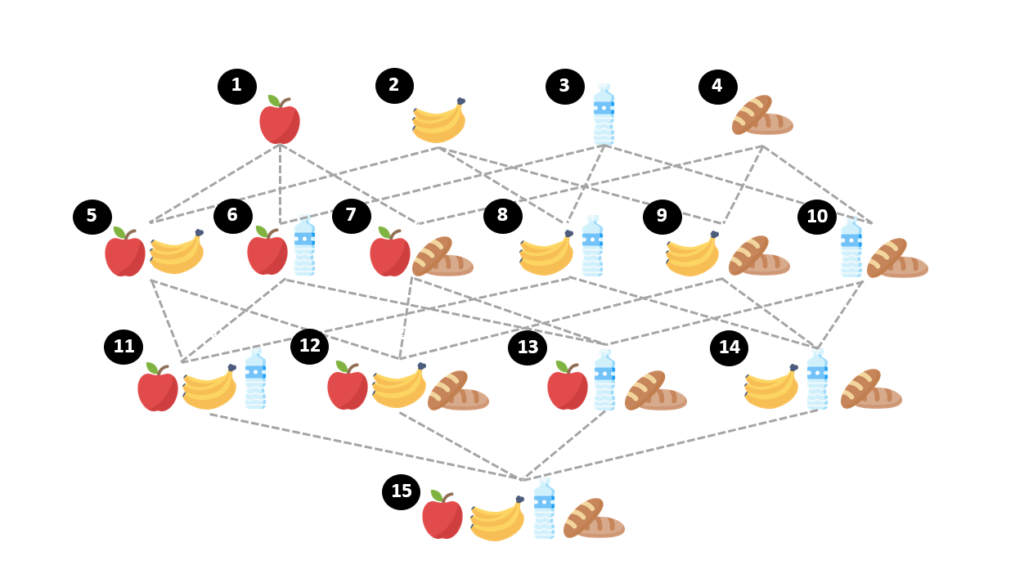
ถ้าใช้วิธีการแบบ Brute Force สำหรับการหา Frequent Itemsets ซึ่งจะหมายถึงการไล่คำนวณค่า Support ของทุก Itemsets ที่เป็นไปได้ทั้งหมด หรือทุก Candidate Itemsets สำหรับการใช้งานจริงในร้านค้าซึ่งมีสินค้าและ Transactions จำนวนมากนั้นอาจจะไม่เป็นการดี เนื่องจากใช้เวลาและทรัพยากรในการประมวลผลค่อนข้างสูง (Computational Expensive and Time Consuming) ดังนั้น Apriori Algorithm จึงถูกพัฒนาขึ้นมาเพื่อแก้ปัญหานี้ เพื่อลดจำนวน itemsets ที่จำนำมาพิจารณาให้เหลือน้อยลง โดยใช้หลักการที่ว่า
“ถ้า itemset ใดเกิดไม่บ่อย superset ทั้งหมดของ itemset นั้น ก็จะเกิดไม่บ่อยด้วยเช่นกัน”
เพื่อให้เห็นภาพมากขึ้นขอยกตัวอย่าง โดยหากลองพิจารณารายการซื้อขายที่เกิดขึ้นในอดีต เราพบ {apple} ใน 5 ตะกร้า สินค้าอื่นที่จะถูกซื้อร่วมกับ apple จะต้องปรากฎใน 5 ตะกร้านี้ด้วยเช่นกัน เป็นไปไม่ได้เลยว่า เราจะพบ {apple, bread} คู่กันเกิน 5 ตะกร้า ดังนั้นถ้าพบว่า {apple} ไม่ใช่ frequent itemsets แล้ว {apple, สินค้าใดๆ} ก็จะไม่ใช่ frequent itemsets ด้วยเช่นกัน หมายความว่า เราสามารถตัด supersets ของ itemsets ที่ไม่ใช่ Frequent Itemset ออกจากการพิจารณาได้เลย ซึ่งในทางปฏิบัติ ทำให้เราลดจำนวน itemsets ที่ต้องพิจารณา จาก 2N – 1 รูปแบบ ลงได้จำนวนมาก มีผลให้การคำนวณทำได้เร็วขึ้นนั่นเอง

จากภาพด้านบนเป็นตัวอย่างของการลดจำนวน itemsets ที่นำมาพิจารณาด้วยหลักการที่กล่าวไปข้างต้น โดยแสดงให้เห็นว่า หาก {apple} ถูกพิจารณาแล้วว่ามีค่า support ต่ำกว่าเกณฑ์ที่ตั้งไว้ ซึ่งจะถือว่า {apple} นั้นเป็น Infrequent Itemset ดังนั้นจะเห็นว่า itemsets ทั้งหมด ที่สร้างมาจาก {apple} จะไม่ถูกนำมาพิจารณาในการสร้าง Association Rule ต่อไปเพราะ Support ของ itemsets เหล่านี้ที่มี apple เป็นส่วนประกอบ จะน้อยกว่าหรือเท่ากับ support ของ {apple} ซึ่งจะมีค่า Support ที่ต่ำกว่าเกณฑ์ ซึ่งสามารถสรุปได้ว่า itemsets เหล่านี้จะถือว่าเป็น Infrequent Itemsets ด้วยทั้งสิ้น โดยจะเรียกวิธีการนี้ว่า “Support-Based Pruning” จะเห็นว่าวิธีการนี้จะช่วยลด itemsets ที่จะนำมาพิจารณาลงได้อย่างมากเลยทีเดียว
ขั้นตอนของ Apriori Algorithm เพื่อหา Frequent Itemsets
Step 0: เริ่มต้นจากการสร้าง itemsets ที่มีจำนวนสมาชิก 1 item ที่เป็นไปได้จาก items ทั้งหมด เช่น {apple} และ {egg} เป็นต้น ขั้นตอนนี้คือการสร้าง Candidate 1-itemsets (C1) ขึ้นมา
Step 1: ทำการคัดเลือก Frequent Itemsets โดยพิจารณาค่า Support ของแต่ละ itemsets ใน Candidate k-itemsets (Ck)ที่ได้จาก step ก่อนหน้า เพื่อหา Frequent k-Itemsets (Fk) โดยจะเก็บ itemsets ที่มีค่า Support ถึงเกณฑ์ที่ตั้งไว้ (Support Threshold) เท่านั้น ขั้นตอนนี้จะถูกเรียกว่าการ prune หรือก็คือการตัด itemsets (รวมทั้ง supersets ของ itemsets เหล่านั้น) ที่ไม่ผ่านเกณฑ์ออกไปนั่นเอง
Step 2: สร้าง Candidate Itemsets ที่มีจำนวนสมาชิกเพิ่มขึ้น 1 item โดยใช้ Frequent k-Itemsets (Fk) ที่ผ่านเกณฑ์จาก Step 1 ในการสร้าง Candidate k+1 itemsets (Ck+1) ใหม่ เพื่อพิจารณาต่อไป โดยใช้การ join คู่ของ Frequent Itemsets จาก Fk ที่มี item เหมือนกัน k-1 ตัว ดังตัวอย่างในรูปด้านล่าง
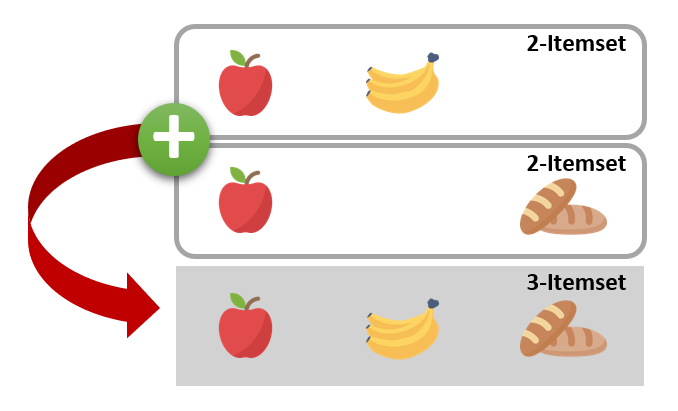
ตัวอย่างเช่น การสร้าง Candidate 3-itemsets (C3) จาก Frequent 2-temsets (F2) เราจะพิจารณา คู่ของ itemsets ใน F2 ที่มี item เหมือนกัน 1 ตัว เช่น {apple, banana} join กับ {apple, water} จากนั้นทำการ join 2 itemsets นี้เข้าด้วยกัน ได้เป็น {apple, banana, water}
Step 3: ทำซ้ำ Step 1 และ 2 โดยเพิ่มค่า k=1, 2, 3, … ไปเรื่อย ๆ จนกระทั่งไม่สามารถสร้าง itemsets ใหม่ได้อีก
ตัวอย่างการหา Frequent Itemsets ด้วย Apriori Algorithm
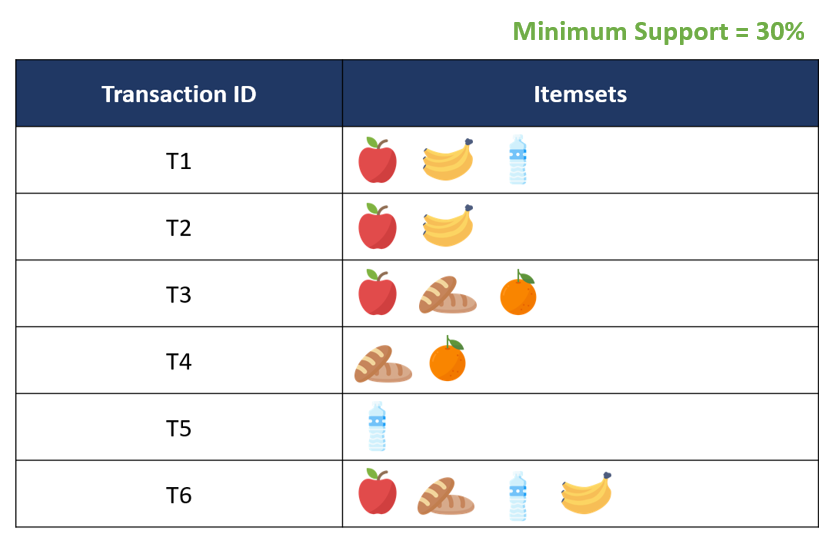
สมมติว่ามีรายการซื้อขายดังตารางด้านบน และเรากำหนดให้ค่า Minimum Support = 30%
1. สร้างตาราง Candidate 1-itemsets (C1) โดยการคำนวณค่า Support Count ของ itemsets ที่มีจำนวนสมาชิก 1 item ทั้งหมดที่เป็นไปได้ หรือเป็นการนับความถี่ ว่ามีการเกิดขึ้นของ item แต่ละ item ในจำนวนกี่ transactions
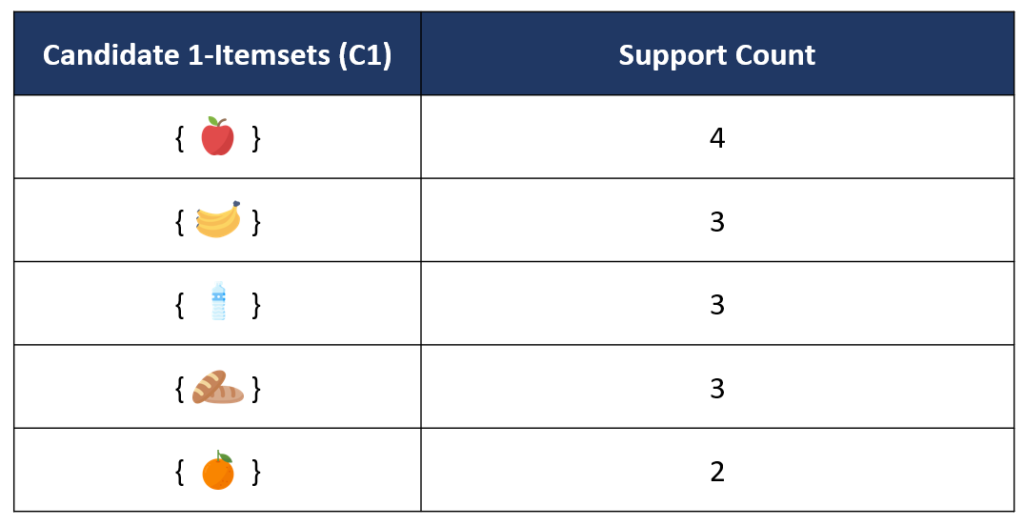
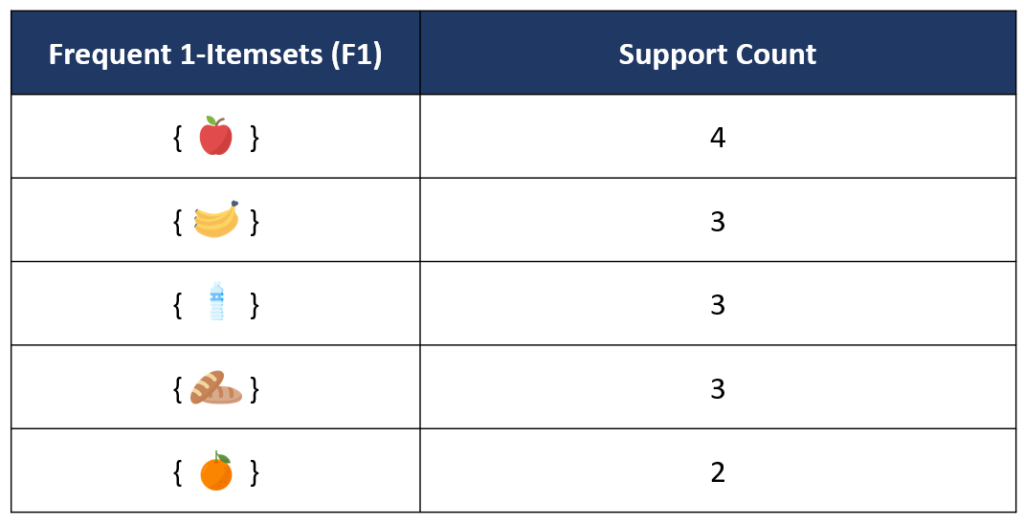
จากตาราง C1 ด้านบนจะเห็นว่า เมื่อนำมาเทียบกับค่า Minimum Support ที่ตั้งไว้ที่ 30% ของจำนวน transaction ทั้งหมด 6 transactions ซึ่งถ้าคิดเป็นเกณฑ์ Minimum Support Count จะได้เท่ากับ (30/100) x6 = 1.8 transactions จะเห็นว่าทุก itemset มี Support Count ที่เกินค่า Minimum Support Count ที่ตั้งไว้ จึงถือว่า itemset ทั้งหมดใน Candidate 1-Itemsets เป็น Frequent Itemset เราก็จะได้ตาราง Frequent 1-itemsets (F1) เป็นทุก item ดังที่แสดงในตารางด้านล่าง
2. ขั้นตอนถัดมาคือการสร้าง Candidate 2-itemsets (C2) โดยจะเป็นการสร้าง itemsets จากคู่ Combination ที่เป็นไปได้ทั้งหมด จาก Frequent Itemsets ที่ได้ในตาราง F1 และนับจำนวนการเกิดขึ้นของแต่ละ itemsets ใน C2
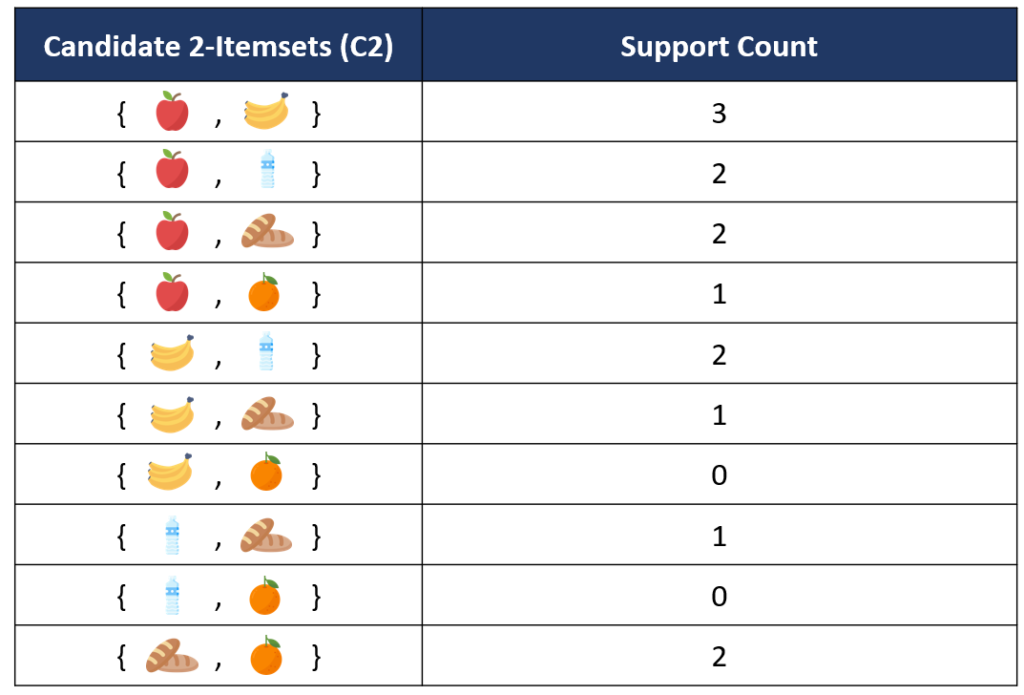
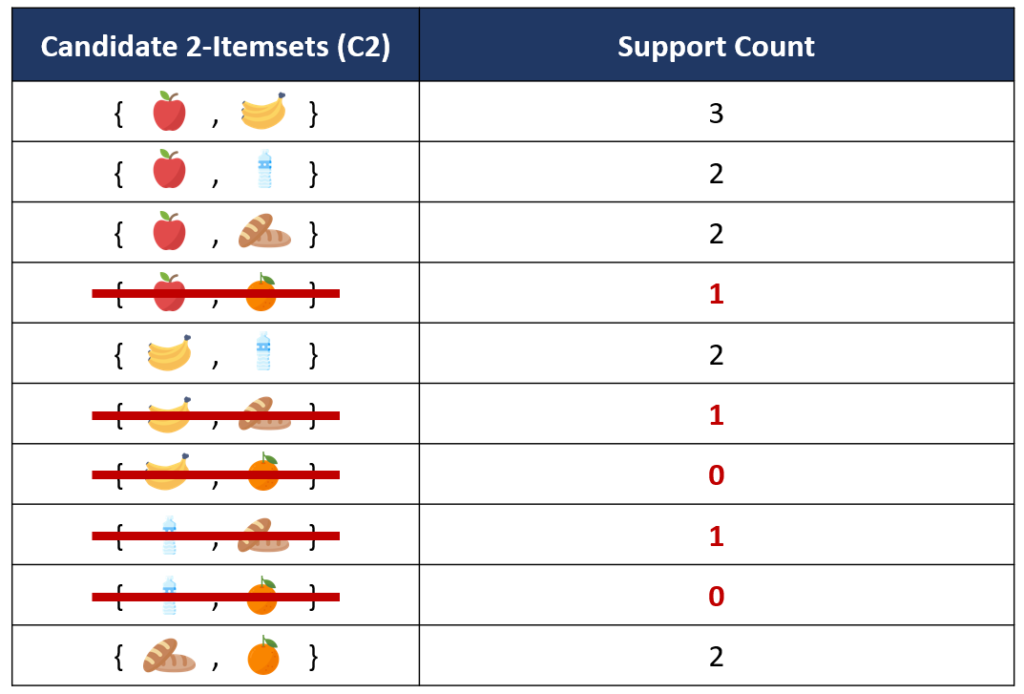
จากนั้นนำแต่ละ itemsets ใน C2 ไปเทียบกับค่า Minimum Support Count (1.8 transactions) จะเห็นว่ามีบางคู่ของ item ที่มีค่า Support Count ต่ำกว่าเกณฑ์ได้แก่ {apple, orange}, {banana, bread}, {banana, orange}, {water, bread} และ {water, orange} ซึ่งจะถูกเอาออกจากการพิจารณาในลำดับถัดไป
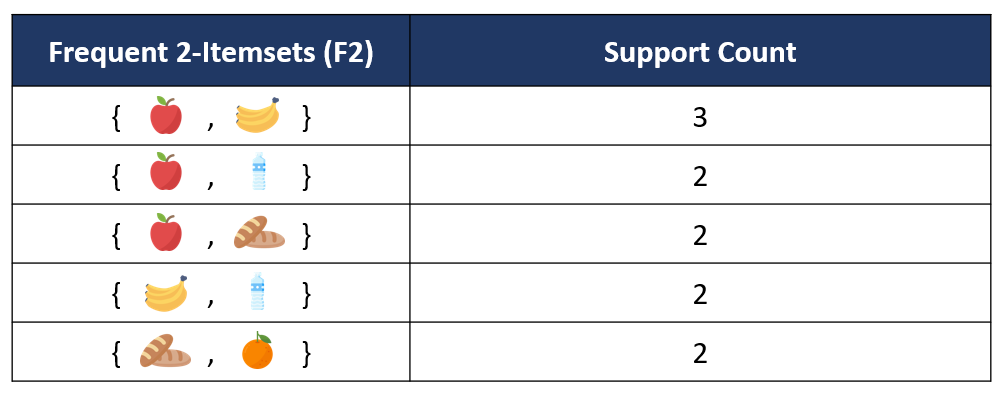
3. ขั้นตอนถัดมาคือการสร้าง Candidate 3-itemsets (C3) โดยจะเป็นการนำเอา Frequent Itemsets ที่ได้ในตาราง F2 ที่มี k-1 = 2-1 = 1 รายการแรกที่เหมือนกันมา join กัน ตัวอย่างเช่น itemsets ที่มีสินค้า apple มีทั้งหมด 3 sets ได้แก่ {apple, banana}, {apple, water}, {apple, bread} นำเอาทั้ง 3 sets มาสร้างคู่ Combination ของการ join ที่เป็นไปได้ทั้งหมด จะได้ดังนี้
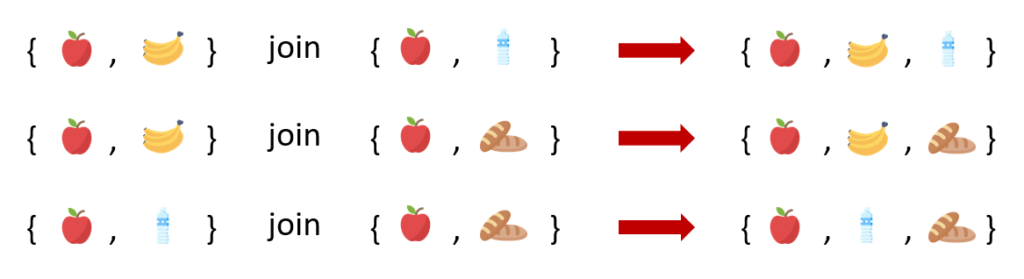
เนื่องจากการ join ในบางครั้งอาจทำให้เกิด itemsets ที่มี subset เป็น Infrequent Itemsets ได้ ดังนั้นหลังจากสร้าง 3-itemsets ที่เป็นไปได้จากการ join itemset ใน F2 แล้ว เราสามารถตัด 3-itemsets ที่ไม่ใช่ frequent itemsets ออกไปได้โดยการพิจารณา 2-itemsets ที่เป็น subset ของ 3-itemsets เหล่านั้น หาก 3-itemsets ใดมี 2-itemsets subset ไม่เป็น Frequent itemset ก็จะถูกตัดออกจากการพิจารณา เพื่อเป็นการลดการคำนวณค่า Support ของ Candidate 3-Itemsets ลง ให้ไม่ต้องคำนวณทุก candidate ตามหลักการของ Apriori Algorithm
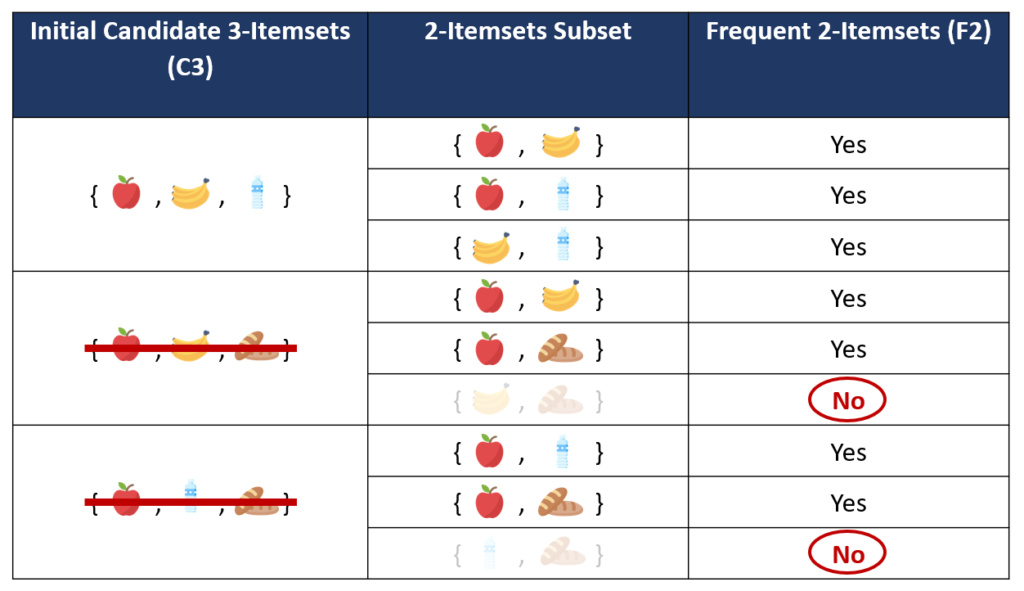
จากขั้นตอนการ prune ที่แสดงในตารางด้านบน จะเห็นว่า {apple, banana, bread} และ {apple, water, bread} มี 2-itemsets subset ที่ไม่อยู่ใน Frequent 2-Itemsets ดังนั้นเราจึงตัดสอง itemsets นี้ไปจาก Candidate 3-itemsets (C3) ทำให้เหลือ เพียง candidate เดียวคือ itemset {apple, banana, bread} ดังแสดงในตารางด้านล่าง

หลังจากนั้นก็นำค่า Support Count ของ item ใน Final Candidate 3-itemsets มาเทียบกับค่า Minimum Support เช่นเดิม จะเห็นว่า itemset {apple, banana, water} มีค่า Support Count ที่ผ่านเกณฑ์ จึงถึงว่า itemset นี้เป็น Frequent Itemset ด้วยเช่นกัน
สุดท้ายเราจะได้รายการของ Frequent Itemsets ทั้งหมด จาก F1-F3 ดังที่แสดงในตารางด้านล่าง
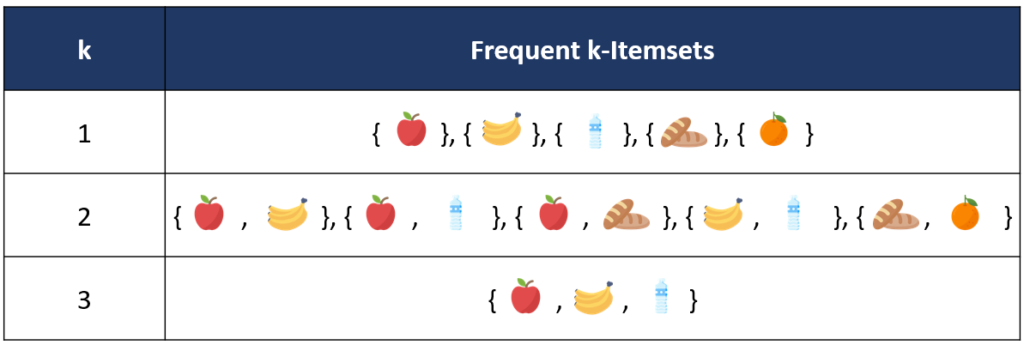
ขั้นตอนถัดไปหลังจากนี้จะเป็นการนำ Frequent Itemsets ทั้งหมดที่หามาได้จาก Apriori Algorithm ไปเข้าสู่กระบวนการที่สองคือสร้างกฎความสัมพันธ์ หรือ Rules Generation ซึ่งจะมีการพิจารณาค่า Confidence หรือ Lift ในการคัดเลือกกฎความสัมพันธ์ที่มีประสิทธิภาพโดยสามารถใช้หลักการของ Apriori ไปประยุกต์ใช้ได้ด้วยเช่นกัน จากตัวอย่างที่ผ่านมาจะเห็นได้ว่าการใช้ Apriori นั้นช่วยให้เราลดจำนวน itemsets ที่ต้องพิจารณาให้น้อยลงได้ โดยใช้แนวคิดของการ prune และ Join ซึ่งส่งผลให้เราสามารถคำนวณหากฎความสัมพันธ์ในฐานข้อมูลขนาดใหญ่ได้เร็วขึ้น หวังว่าบทความนี้จะช่วยให้ผู้อ่านเข้าใจหลักการของ Apriori Algorithm มากขึ้น และหากท่านใดสนใจในรายละเอียดของการสร้างกฎความสัมพันธ์หลังจากที่ได้ Frequent Itemsets มาแล้วนั้น สามารถติดตามอ่านได้ในบทความถัดไปเลยค่า
ที่มา
Icons made by Freepik from www.flaticon.com
https://www.javatpoint.com/apriori-algorithm-in-machine-learning
https://www.softwaretestinghelp.com/apriori-algorithm/
http://www.wiwatchin.com/page/article/Apriori.pdf
https://medium.com/@sawravador/overview-about-apriori-algorithm-a5f20f0a4d39
https://www.kdnuggets.com/2016/04/association-rules-apriori-algorithm-tutorial.html/2
Project Manager & Data Scientist
Big Data Institute (Public Organization), BDI