
บทความนี้ถูกคุ้มครองด้วย Creative Commons License
เนื้อหาส่วนมากของบทความนี้ได้รับการแปล สังเคราะห์ และเรียบเรียงจากหนังสือ Interpretable Machine Learning โดย Christoph Molnar
Most content in this article is translated, compiled, and summarized from the Interpretable Machine Learning by Christoph Molnar
Model-Agnostic Interpretation Methods
ท่านผู้อ่านที่เคยได้ยินหรือมีประสบการณ์ด้านการวิเคราะห์ข้อมูลอาจจะคุ้นเคยกับการพัฒนาโมเดลทางการเรียนรู้ของเครื่อง (Machine Learning) เพื่อทำนายผลตามโจทย์ที่ต้องการไม่ว่าจะเป็นการทำนายค่า (Regression) หรือการจำแนกหมวดหมู่ต่างๆ (Classification) อย่างไรก็ตามในหลายครั้ง จุดประสงค์หลักอีกอย่างหนึ่งของการพัฒนาโมเดล Machine Learning สำหรับพยากรณ์คือการวิเคราะห์ผลกระทบและความสำคัญ (Importance) ของคุณสมบัติ (Feature) ของข้อมูลที่มีต่อผลการทำนายของโมเดล การวิเคราะห์ข้อมูลในลักษณะนี้สามารถนำไปใช้ประโยชน์ต่อยอดได้ในหลากหลายด้าน เช่น ในด้านสุขภาพ การวิเคราะห์ปัจจัยที่มีผลมากในการทำนายการแพร่กระจายของโรคจะช่วยให้นักวิเคราะห์สามารถระบุประเด็นที่ควรพิจารณาเป็นพิเศษในการช่วยลดผลกระทบของโรคได้ หรือในด้านการค้า การวิเคราะห์ลักษณะของบุคคลที่มีผลมากในการซื้อสินค้าจะช่วยให้ผู้ขายสามารถออกแบบแผนการตลาดที่มีประสิทธิภาพสูงได้
วิธีหนึ่งที่ผู้ต้องการวิเคราะห์ข้อมูลในลักษณะสามารถใช้พิจารณาผลกระทบและความสำคัญของคุณสมบัติต่างๆ ได้อย่างตรงไปตรงมาคือ การเลือกโมเดลในตระกูลที่สามารถตีความได้ (Interpretable Model) มาใช้ในการพัฒนา ไม่ว่าจะเป็นโมเดลอยู่ในรูปแบบของสมการเช่นโมเดลตระกูล regression ที่ผู้ใช้สามารถนำค่าสัมประสิทธิ์ของตัวแปรในสมการต่างๆ มาอธิบายผลกระทบที่ตัวแปรมีแก่ผลลัพธ์ที่ต้องการทำนาย หรือ โมเดลในตระกูล decision tree ซึ่งหลังจากการฝึกฝนแล้วนั้น ผู้พัฒนาสามารถศึกษากฎการตัดสินใจในขั้นต่างๆเพื่อจำแนกผลลัพธ์ที่ต้องการได้
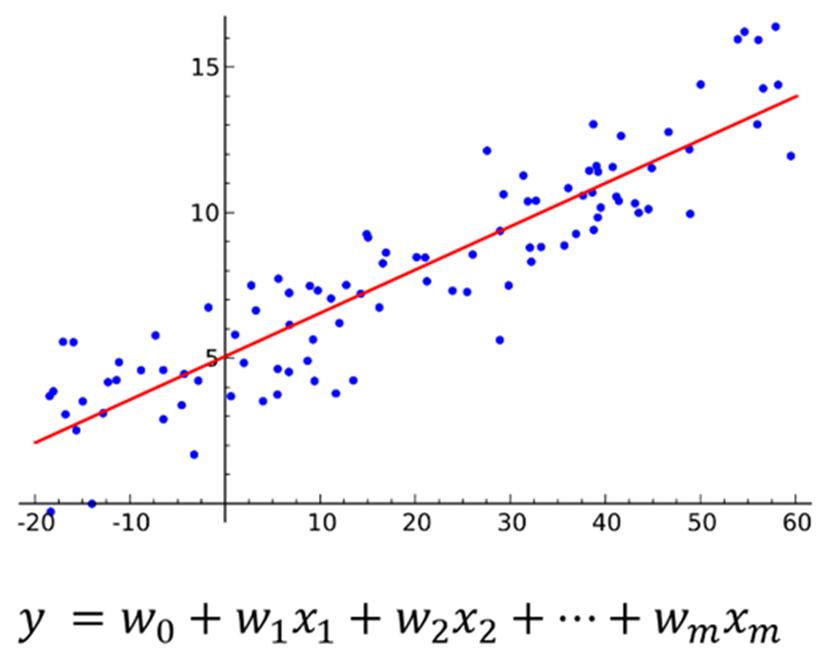
(รูปภาพโดย Sewaqu)
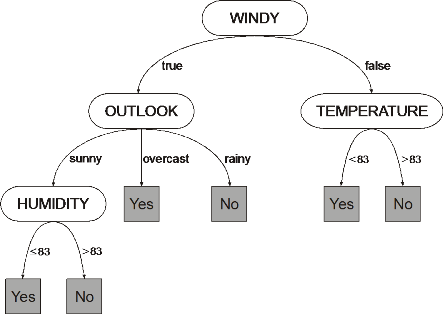
(รูปภาพโดย Oritnk)
อย่างไรก็ดี วิธีดังกล่าวจะจำกัดประเภทของโมเดลที่สามารถใช้งานได้ และหลาย ๆ โมเดลที่เป็นที่นิยมและใช้กันอย่างแพร่หลายเช่น โมเดลตระกูล neural network โมเดล random forest หรือ โมเดล gradient-boosted tree จะไม่ถูกเลือกมาใช้เนื่องจากสามารถตีความหมายได้ยาก เพื่อให้โมเดลกลุ่มที่ตีความหมายได้ยากเหล่านี้ถูกเลือกใช้ได้ จึงได้มีการพัฒนาเทคนิคสำหรับการตีความโมเดลโดยไม่ขึ้นอยู่กับชนิด (model-agnostic interpretation methods) ขึ้นเพื่อแก้ปัญหาข้อจำกัดดังกล่าว โดยคุณสมบัติที่เทคนิคเหล่านี้พึงมี (อ้างอิงจาก Ribeiro, Singh, and Guestrin 2016) ได้แก่
- Model flexibility: วิธีการตีความควรสามารถใช้ได้กับโมเดล machine learning ทุกประเภท
- Explanation flexibility: คำอธิบายที่ได้รับจากวิธีการตีความไม่ควรถูกจำกัดอยู่ในรูปแบบใดรูปแบบหนึ่ง เช่นบางโมเดลอาจเหมาะที่จะอธิบายด้วยสมการ ในขณะที่บางกรณีอาจจะเหมาะที่จะใช้การแสดง feature importance ในรูปแบบของกราฟหรือรูปภาพแทน
- Representation flexibility: วิธีการที่นำมาใช้ตีความโมเดลควรสามารถรองรับการใช้งานคุณสมบัติข้อมูล (features)ในรูปแบบที่แตกต่างจากที่ใช้งานในโมเดลที่ถูกวิเคราะห์ได้ เช่น ในการอธิบายการทำงานของ text classifier ที่ใช้งาน word embedding vectors (link ไปที่ article) ผู้ศึกษาอาจเห็นว่าการอธิบายด้วยการใช้คำ (word) จริงๆ ที่ปรากฏอยู่เอกสารนั้นสามารถอธิบายได้เหมาะสมกว่าและเลือกให้คำอธิบายในรูปแบบดังกล่าวแทน
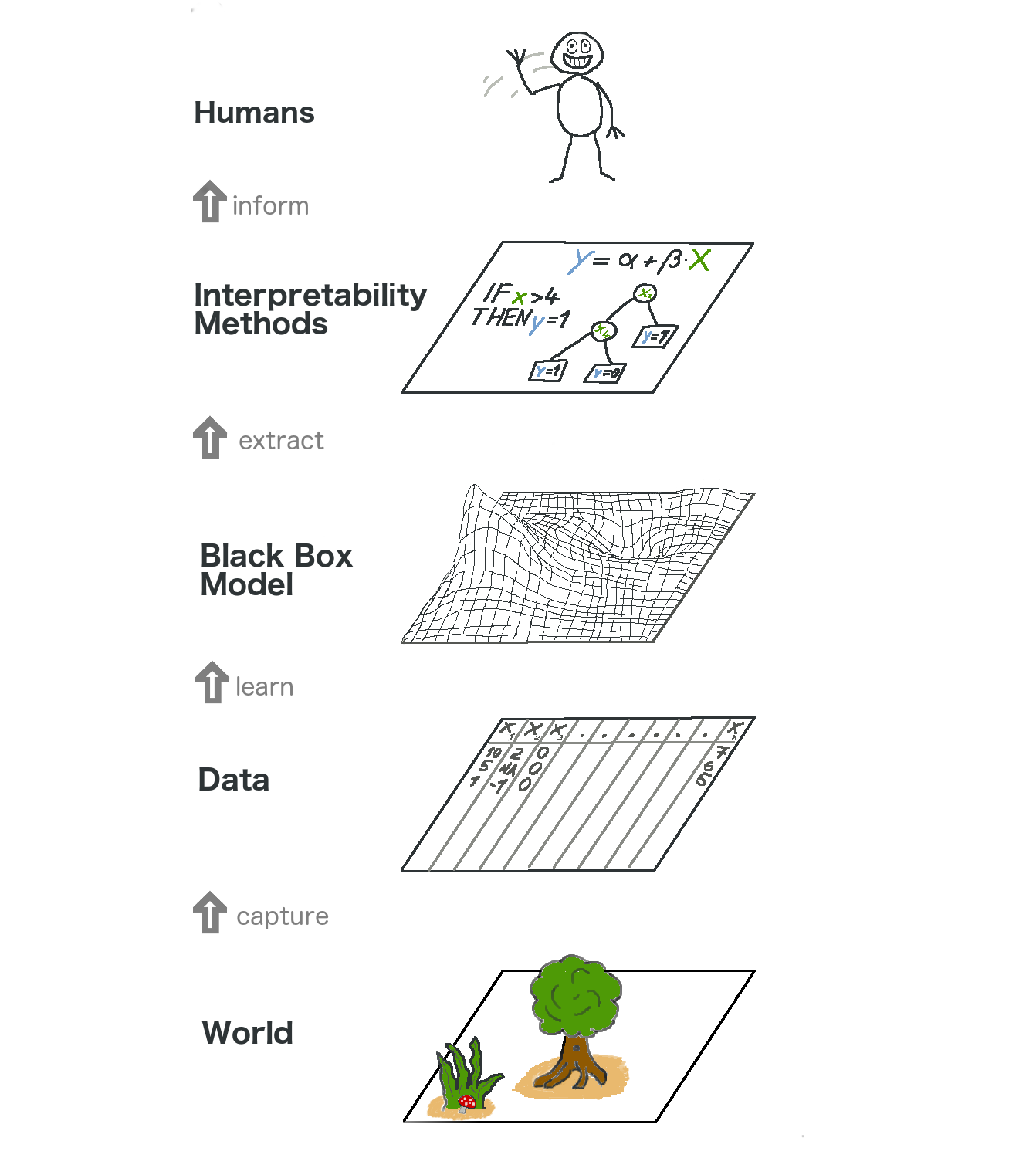
เทคนิคตระกูล model-agnostic interpretation methods นั้นสามารถถูกแบ่งย่อยออกได้เป็น 2 ประเภทหลัก ได้แก่เทคนิคสำหรับอธิบายภาพรวม (global method) และเทคนิคสำหรับอธิบายเฉพาะพื้นที่ (local methods) โดย global methods นั้นจะถูกใช้เพื่ออธิบายผลกระทบโดยเฉลี่ยของ feature ต่อการทำนาย (prediction) ของโมเดล ในขณะที่ local methods ถูกออกแบบมาเพื่ออธิบายผลกระทบเป็นรายการทำนาย
สำหรับบทความนี้ เราจะมาพูดถึงหนึ่งใน local method ที่ถูกใช้งานอย่างแพร่หลายซึ่งก็คือ Local Interpretable Model-agnostic Explanations (LIME)
Local Interpretable Model-agnostic Explanations (LIME)
LIME เป็นเทคนิคที่ทำการอธิบายผลกระทบของ feature ต่อการทำนายเป็นรายจุดข้อมูล โดยเทคนิคนี้จะถือว่าผู้ใช้ไม่มีข้อมูลการทำงานภายในของโมเดลที่ต้องการอธิบายเลย เรียกโมเดลนี้ว่าเป็น “กล่องดำ” (black box) และจะทำการสร้างโมเดลตัวแทน (Local Surrogate) ที่เลียนแบบพฤติกรรมของโมเดลตั้งต้นในพื้นที่ใกล้เคียงจุดที่ผู้ใช้ต้องการทำการศึกษาขึ้นมาแทน โมเดลที่ถูกสร้างขึ้นใหม่นี้จะถูกใช้เพื่อทำการอธิบายเหตุผลที่โมเดลตั้งต้นให้คำทำนายต่าง ๆ ตามที่ปรากฏ โดย LIME จะอาศัยการทดสอบว่า “จะเกิดอะไรขึ้นกับผลการทำนายของโมเดลที่เราต้องการศึกษา หากเราทำการเปลี่ยนแปลงข้อมูลที่นำเข้าใช้ทำนายไปเล็กน้อย” ผลจากการทดสอบนี้จะนำไปใช้ในการสร้างและปรับปรุงโมเดลตัวแทนให้ดียิ่งขึ้น
หลักการของทำงาน LIME จะเริ่มจากการสร้างชุดข้อมูลใหม่ซึ่งประกอบด้วยข้อมูลที่ถูกเปลี่ยนแปลงไปเล็กน้อย (perturbed samples) จากจุดข้อมูลที่เราสนใจพร้อมผลการทำนายจากการใช้ข้อมูลเหล่านี้กับโมเดล black box ที่ผู้ใช้ต้องการอธิบาย จากนั้นผู้ใช้จะทำการเลือกโมเดลประเภทที่สามารถตีความได้ง่าย เช่น lasso หรือ decision tree มาฝึกฝนเป็นโมเดลตัวแทน โดยจะใช้ข้อมูลจากชุดข้อมูลของ perturbed samples ที่ถูกสร้างไว้และจะให้น้ำหนักความสำคัญ (weight) ของแต่ละ sample แตกต่างกันตามความใกล้เคียง (proximity) กับจุดข้อมูลที่สนใจศึกษาผลกระทบ สิ่งที่ได้มาจากการฝึกฝนจะเป็นโมเดลที่สามารถประมาณค่าพฤติกรรมของโมเดลตั้งต้นได้อย่างแม่นยำเฉพาะในบริเวณพื้นที่ใกล้เคียงจุดที่สนใจ ความแม่นยำเฉพาะพื้นที่ในลักษณะนี้มีชื่อเรียกว่า local fidelity
ในทางคณิตศาสตร์ เราสามารถเขียน constraint ของการตีความของโมเดลได้ในรูปแบบดังต่อไปนี้
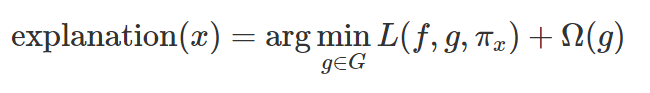
โดย
- g คือโมเดลสำหรับใช้อธิบาย (explanation model) เช่นโมเดล linear regression ซึ่งจะใช้สำหรับจุดข้อมูล x
- G คือตระกูลของคำโมเดลสำหรับใช้อธิบาย (เช่น โมเดล linear regression ทั้งหมดที่เป็นไปได้)
- f คือโมเดลตั้งต้นที่ผู้ใช้ต้องการอธิบาย
- πx คือมาตรวัดความใกล้เคียง (proximity measure) กล่าวคือ ความกว้างของพื้นที่ (neighborhood) รอบจุดข้อมูล x ที่เราจะทำการพิจารณาเพื่อใช้สร้างคำอธิบาย
- L คือ loss (Mean Squared Error) ที่ใช้วัดค่าความใกล้เคียงระหว่างโมเดลสำหรับใช้อธิบายกับโมเดลตั้งต้น
- Ω(g) คือความซับซ้อน (complexity) ของโมเดลที่สำหรับใช้อธิบาย โดยปกติแล้วจะพยายามทำให้มีค่าต่ำเช่นทำให้โมเดลที่จะใช้อธิบาย มีจำนวน feature น้อย
เห็นสมการแบบนี้แล้วก็อย่าเพิ่งตกใจไปนะครับ กล่าวโดยง่ายหน่อย คือ โมเดล g เป็น โมเดลที่ “ใช้อธิบาย” (เป็นโมเดลง่ายๆ เช่น linear regression) ซึ่งจะถูกปรับให้ความแตกต่างของคำทำนาย (loss) เมื่อเทียบกับคำทำนายของโมเดลตั้งต้น f (โมเดลที่ “ต้องการอธิบาย” ซึ่งอาจซับซ้อนกว่า เช่น โมเดล xgboost) น้อยที่สุด โดยในขณะที่ปรับคำนายนั้น เทคนิคนี้ก็พยายามจะให้ทำความซับซ้อนของโมเดลที่นำมาใช้นั้นอยู่ในระดับต่ำ (มี feature น้อย ซับซ้อนน้อย เข้าใจง่าย) นั่นเองครับ
ในการใช้งานจริง ตัวอัลกอริทึมของ LIME จะ optimize ส่วนที่เป็น Loss เท่านั้น กล่าวคือ จะปรับโมเดลที่เลือกมาเพื่อใช้อธิบายเฉพาะส่วนที่ทำให้มี error ระหว่างตัวโมเดลกับโมเดลที่เราต้องการอธิบายมีน้อยที่สุด สำหรับส่วนของความซับซ้อนของโมเดลเช่นจำนวน feature สูงสุดที่จะกำหนดให้ linear regression สามารถใช้ได้ ผู้ใช้เทคนิคจะต้องเป็นคนกำหนดเอง ซึ่งแน่นอนว่าการเลือกจำนวนของ features ที่จะใช้งานในโมเดลที่ใช้อธิบายนั้นไม่ใช้เรื่องที่ง่าย เพราะถึงแม้ว่าการมีจำนวน features น้อยจะช่วยให้ผู้ใช้สามารถตีความผลลัพธ์ได้ง่าย การที่มีจำนวน features มากจะช่วยให้มีโอกาสสูงขึ้นที่โมเดลที่ถูกเลือกมาใช้เพื่อตีความจะสามารถปรับพฤติกรรมให้ใกล้เคียงโมเดลที่ต้องการอธิบายได้ดี (มีค่า local fidelity ที่สูงขึ้น) ผู้ใช้จึงจำเป็นต้องทำการทดลองเพื่อหาเลขที่ตนคิดว่าเหมาะสมที่สุดครับ
เมื่อได้ตัดสินใจเลือกจำนวน features ที่จะใช้เพื่อฝึกฝนโมเดลแล้ว คำถามถัดมาคือเราจะสามารถเลือก feature ที่จะนำมาใช้อธิบายได้อย่างไร วิธีหนึ่งในการเลือกให้ได้จำนวน features ที่ต้องการคือการทำ regularization ชนิด lasso กับ โมเดลตระกูล regression (เช่น linear regression / logistic regression) ที่เราเลือกมาใช้อธิบาย
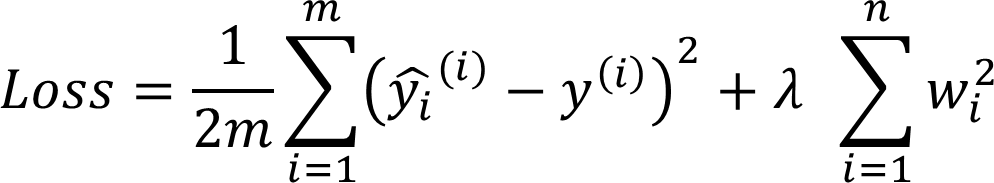
โดยผู้ใช้อาจเริ่มจากการตั้งค่า regularization parameter ที่มีค่าสูงจนไม่มี feature ไหนถูกเลือกเลย แล้วค่อย ๆ ทำการลดขนาด regularization parameter ลงเพื่อเพิ่มจำนวน feature ที่โมเดลเลือกใช้จนกระทั่งได้จำนวน feature ที่ต้องการ
สำหรับตัวอย่างวิธีอื่นในการเลือก features ให้ได้จำนวนที่ต้องการนั้น ได้แก่ การใช้โมเดลตระกูล tree ที่จำกัดจำนวนการ split สูงสุดในใช้การเลือก และ การทำ forward/backward feature selections ซึ่งเริ่มต้นจากโมเดลที่ใช้ features ทั้งหมด หรือไม่มี feature เลย แล้วทำการเพิ่ม feature เข้าและนำ feature พร้อมพิจารณาตามความแตกต่างของคำทำนายของโมเดลที่เลือกใช้กับโมเดลที่ต้องการอธิบายในแต่ละชุดของ features จนกระทั่งได้จำนวนและชุดของ feature ที่ทำให้ความแตกต่างมีค่าน้อยที่สุด เป็นต้น
เป็นอย่างไรกันบ้างครับ พอจะเข้าใจหลักการของ Model-Agnostic Interpretation Method สำหรับใช้ตีความโมเดล machine learning และหลักการทำงานคร่าวๆของ LIME กันไหมครับ ในบทความต่อไปเราจะลงรายละเอียดเพิ่มเติมกันว่า เราจะสามารถนำ LIME ไปใช้กับข้อมูลประเภทตาราง (tabular) กันได้อย่างไร พร้อมกับพูดถึงประโยชน์และข้อจำกัดของการตีความโมเดลต่างๆ ด้วยเทคนิคนี้กันครับ
ข้อมูลที่เกี่ยวข้องและข้อมูลเพิ่มเติม
- Ribeiro, Marco Tulio, Sameer Singh, and Carlos Guestrin. “Model-agnostic interpretability of machine learning.” ICML Workshop on Human Interpretability in Machine Learning. (2016)
- Interpretable Machine Learning โดย Christoph Molnar Chapter 6: Model-Agnostic Methods
- Interpretable Machine Learning โดย Christoph Molnar Chapter 9.2: Local Surrogate (LIME)
แปล สังเคราะห์ เรียบเรียง และเขียนเพิ่มเติม โดยปฏิภาณ ประเสริฐสม
ตรวจทานและปรับปรุงโดย พีรดล สามะศิริ




Senior Project Manager & Data Scientist
at Big Data Institute (Public Organization), BDI







