ในปัจจุบัน เราจะพบข้อมูลพิกัดบอกตำแหน่ง ละติจูด (Latitude) และลองจิจูด (Longitude) เป็นจำนวนมาก โดยการนำไปใช้ประโยชน์เชิงวิเคราะห์นั้น หากเลือกใช้ ละติจูด และลองจิจูดเป็นสองตัวแปรแยกกันมักจะได้ผลออกมาแล้วตีความยาก ในบทความนี้จะทำการอธิบายและนำเสนอตัวอย่างวิธีการ Feature Engineering จากข้อมูลพิกัดจุด
การเลือกใช้ ละติจูด และลองจิจูดเป็นสองตัวแปรแยกกันมักจะได้ผลออกมาแล้วตีความยาก
การสร้าง Feature จากข้อมูลพิกัดจุด (Geospatial Data) นั้นจำเป็นต้องใช้ความเข้าใจในความสัมพันธ์จากบริบทของภูมิศาสตร์ กับโจทย์ปัญหาที่เราต้องการแก้ เช่น หากโจทย์ต้องการทำนายราคาบ้าน เราอาจจะเริ่มด้วยการคิดว่ามีปัจจัยใดบ้างที่มีผลต่อราคา เช่น ระยะทางจากสถานีรถไฟฟ้า, ระยะทางจากศูนย์กลางเมือง, ระยะห่างจากทะเล เป็นต้น ดังนั้นเราจะต้องแปลงปัจจัยดังกล่าวให้เป็นตัวเลขเพื่อนำไปใช้ในการวิเคราะห์ และนำไปใช้ประโยชน์ได้
ในบทความนี้ เราจะยกตัวอย่างการใช้ข้อมูลพิกัดจุดเพื่อใช้ทำนายราคาบ้านโดยใช้ข้อมูล Kaggle California Housing Prices ในการวิเคราะห์ ซึ่งเป็นข้อมูลสำรวจ Census ในปี 1990 แต่ละระเบียนจะเป็นข้อมูลของสิ่งปลูกสร้าง 1 บล็อก ในชุดข้อมูลนี้จะมีข้อมูลอยู่ทั้งหมด 10 คอลัมน์ แต่เราจะเลือกใช้แค่ 4 คอลัมน์ ได้แก่
- longitude – ตำแหน่งพิกัดลองจิจูด
- latitude – ตำแหน่งพิกัดละติจูด
- median_house_value – ค่ามัธยฐานของมูลค่าบ้านใน block
- ocean_proximity – label ความห่างจากทะเล
รูปภาพประกอบในบทความนี้สามารถสร้างได้จากชุดคำสั่งใน Python ซึ่งผู้อ่านสามารถทำตามได้จาก House Value California: Feature Engineering
หากเรานำพิกัดจุดมาใช้โดยตรงนั้นจะไม่ค่อยได้ประโยชน์เท่าไหร่ เพื่อให้เห็นภาพชัดเจนเราจะใช้ scatter plot ระหว่างตัวแปรและค่าราคาบ้าน
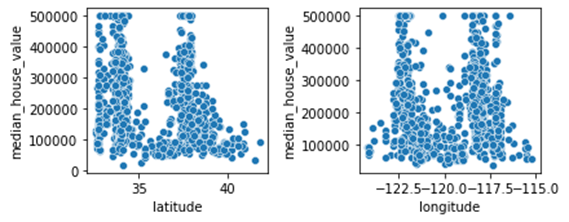
จะเห็นได้ว่าตัวแปรละติจูดและลองจิจูด นั้นไม่ได้มีความเกี่ยวข้องกับราคาบ้านที่ชัดเจน ดังนั้นเราอาจจำเป็นต้องผ่านกระบวนการอื่นเพิ่มเติมก่อนที่จะนำในการนำตัวแปรสองตัวนี้ไปใช้ประโยชน์ได้
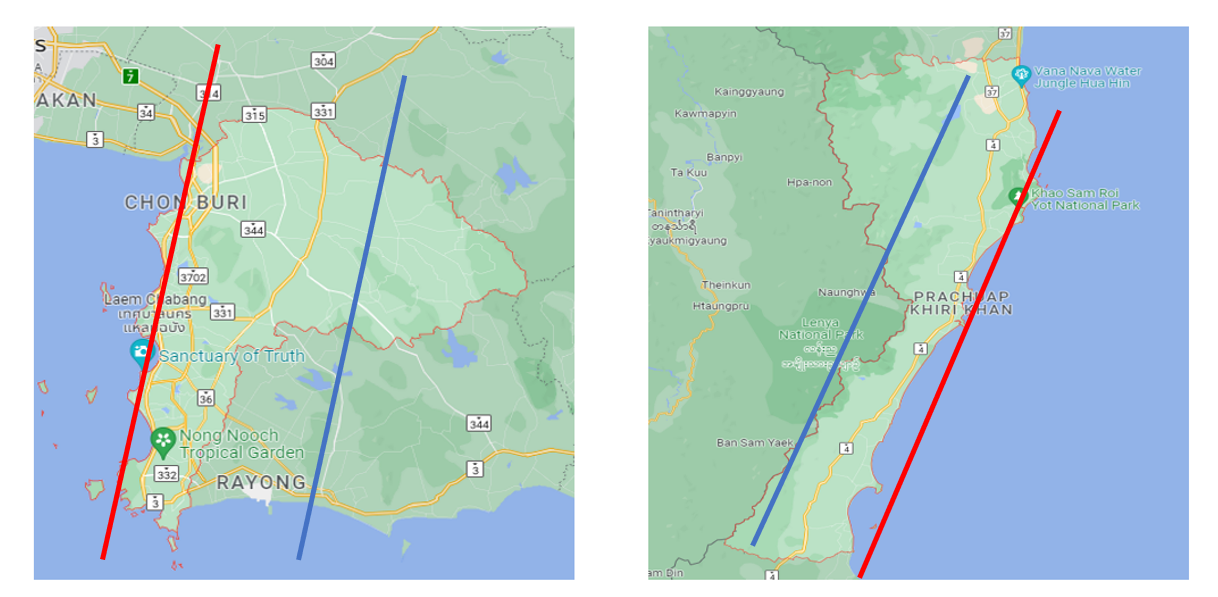
การใช้ Diagonal เพื่อประเมินระยะห่างจากชายฝั่ง
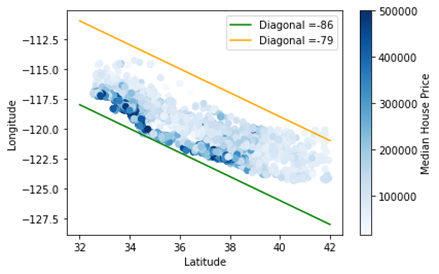
จาก Fig.2 จะมองเห็นได้ชัดเจนว่าบ้านที่อยู่ใกล้กับชายฝั่งจะมีราคาแพงมากกว่าบ้านที่อยู่ห่างจากชายฝั่ง โดยเราสามารถแปลความใกล้กับชายฝั่งได้แบบง่ายๆ โดยการนำเอาพิกัดละติจูดและลองจิจูดมาบวกกันเป็น Feature ใหม่ที่ชื่อว่า Diagonal
เมื่อย้อนกลับไปดูที่ Fig. 2 จะสามารถเห็นได้ว่าถ้าผลบวกน้อยจะใกล้ชายฝั่ง (เส้นสีเขียว) ถ้าผลบวกมากจะอยู่ห่างจากชายฝั่ง (เส้นส้ม) [1]
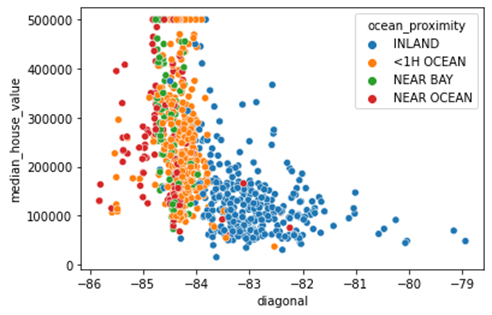
จะเห็นได้ว่า Diagonal นั้นมีความสัมพันธ์กับราคาบ้านที่ชัดเจนขึ้นและสอดคล้องกับ Label ที่ได้มาจากคอลัมน์ ocean_proximity การคำนวณ Diagonal นั้นมีข้อดีที่ใช้ง่ายและสามารถมองเห็นได้ด้วยตาเปล่า แต่อาจจะต้องปรับการใช้ตามลักษณะรูปร่างขอเมือง ในกรณีนี้สามารถใช้ได้ดีเป็นกรณีพิเศษเนื่องจากรัฐ California มีลักษณะเป็นแนวเส้นเฉียงจากซ้ายบนลงขวาล่าง (ตามรูป) โดยในประเทศไทยนั้นมีจังหวัดที่มีรูปร่างที่เหมาะกับการใช้ Diagonal ได้แก่ กระบี่, ตรัง และสตูล เป็นต้น
การใช้ Principal Component Analysis
ในส่วนนี้เราจะนำการใช้ Principal Component Analysis [3]เพื่อนำแนวความคิดของการใช้ diagonal มาใช้กับเมืองที่อยู่ติดชายฝั่ง แต่อาจจะไม่ได้เฉียงจากซ้ายบนลงขวาล่าง โดยจังหวัดในประเทศไทยที่เข้าข่ายนี้ ได้แก่ ชลบุรี และ ประจวบครีขันธ์
การใช้ Principal Component Analysis (PCA) นั้นจะให้ตัวโปรแกรมหาแกนที่เหมาะสมให้เราเอง โดยหลักการคร่าวๆนั้นตัวโปรแกรมจะทำการลากเส้นบนแผนที่ (ตาม Fig.4) แล้วเลือกแกนที่มีการกระจายตัวของข้อมูลมากที่สุดเป็น PCA 1 และเลือกแกนที่ตั้งฉากกันเป็น PCA 2
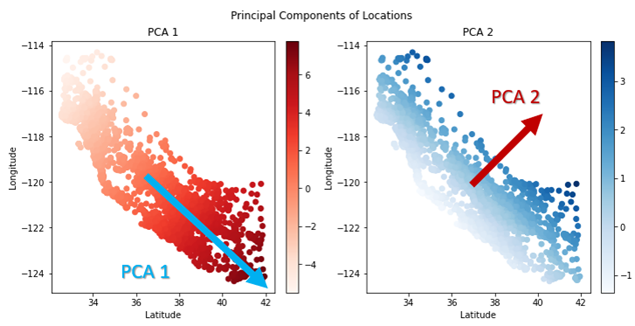
จะเห็นได้ว่าค่าของ PCA 2 ที่ได้มานั้นจะมีค่าสูงเมื่อบ้านอยู่ห่างจากชายฝั่ง และต่ำเมื่อบ้านอยู่ใกล้ชายฝั่ง จึงทำให้นำมาใช้แทน Diagonal ได้ แต่วิธีการนี้ก็ยังมีข้อจำกัดอยู่ที่ว่าสามารถใช้ได้กับเมืองที่มีลักษณะเป็นแนวเฉียงเท่านั้น ซึ่งในกรณีอื่นนั้นอาจจะนำความรู้เรื่องตำแหน่งของใจกลางเมืองมาช่วยในการสร้าง Feature เพื่อนำมาใช้ประโยชน์ได้
การใช้ระยะห่างจากเมืองใหญ่
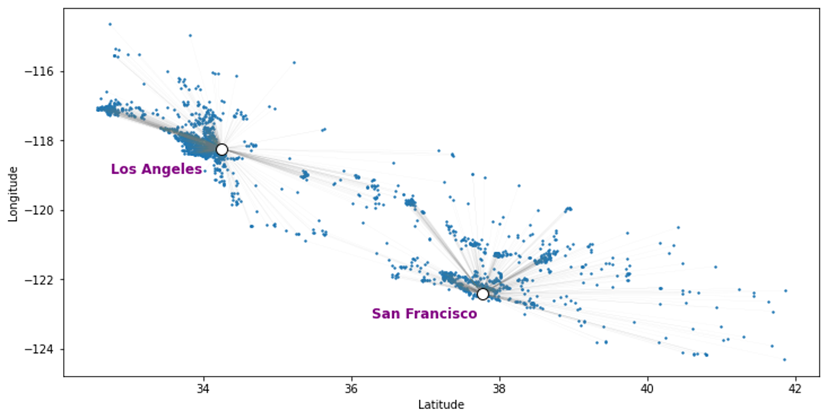
ย้อนกลับไปที่ Fig. 2 เราอาจสังเกตได้ว่าบ้านที่มีราคาสูงจะกระจุกตัวอยู่ใกล้ตัวเมือง Los Angeles และ San Francisco ซึ่งค่อนข้างสมเหตุสมผล เนื่องจากมีระยะใกล้กับสิ่งอำนวยความสะดวกและสถานที่ทำงานมากกว่า ทำให้มีความราคาแพงกว่าบ้านที่อยู่ห่างจากตัวเมือง ในกรณีนี้เราอาจจะเลือกใช้ระยะห่างจากเมืองใหญ่ถึงบ้านใช้เป็น feature ที่ใช้ในการทำนายราคาบ้านได้ โดยการคำนวณระยะทางจากพิกัดละติดจูด และ ลองจิจูด ตามหลักแล้วจะต้องใช้ฟังก์ชั่น Haversine (มีฟังก์ชั่นสำเร็จรูปใน Python – คู่มือการใช้) เพื่อการคำนวณให้แม่นยำ แต่ในกรณีนี้เราใช้เพื่อนำมาทำ Feature Engineering อาจจะไม่ต้องการความแม่นยำมาก เราอาจจะใช้สูตรพิทาโกรัส เพื่อคำนวณระยะห่างแบบง่ายๆ

โดยเราจะเลือกใช้ระยะทางจากเมืองที่อยู่ใกล้บ้านที่สุดมาใช้คำนวณได้
สรุปผล
การทำ Feature Engineering นั้น สิ่งที่จะต้องคำนึงถึงเป็นอย่างแรกคือลักษณะรูปร่างของเมืองและความสัมพันธ์ของข้อมูล ในบทความนี้เราได้ยกตัวอย่างรัฐ California ซึ่งมีลักษณะเฉพาะตัว โดยได้ยกตัวอย่างการทำ Feature Engineering อยู่ 3 วิธีคือ Diagonal, Principal Component Analysis และ การใช้ระยะห่างจากเมืองใหญ่ โดยเน้นวิธีการที่สามารถตีความได้ง่ายและไม่ซับซ้อน
โดยในบางกรณีการนำข้อมูล Geospatial ไปใช้ยังมีวิธีอื่นที่ไม่ได้รวมไว้อยู่ในบทความนี้ เช่น Clustering, geohash [6] โดยผู้ทำการวิเคราะห์สามารถเลือกใช้ให้เข้ากับบริบทของโจทย์
อ้างอิง
- Bayesian Regression – House Price Prediction
- Geospatial Feature Engineering and Visualisation
- A Step-by-Step Explanation of Principal Component Analysis (PCA)
- Calculating distance between two geo-locations in Python
- Geospatial Feature Engineering and Visualization
- Feature engineering: all I learnt about Geo-spatial features

Formal Senior Data Scientist at Big Data Institute (Public Organization), BDI



Senior Project Manager & Data Scientist
at Big Data Institute (Public Organization), BDI









