
สำหรับผู้ที่เคยสร้างโมเดลการรู้ของเครื่อง (Machine Learning Model) จะทราบดีว่า การที่โมเดลของเราจะทำงานได้มีประสิทธิภาพในระดับที่ต้องการกับข้อมูลจริงใน Production ตั้งแต่ครั้งแรกนั้นแทบจะเป็นไปไม่ได้เลย ในการที่เราจะทำโมเดลเพื่อตอบปัญหาต่าง ๆ ไม่ว่าจะเป็นปัญหาทางธุรกิจหรือปัญหาทางวิทยาศาสตร์ เราจะต้องผ่านกระบวนการซ้ำ ๆ เหมือนการที่เราลองต่อจิ๊กซอว์หลาย ๆ ชิ้นเข้าด้วยกันจนกระทั่งเราได้ผลลัพธ์ที่เราต้องการ ตั้งแต่ การเก็บข้อมูล, EDA, การเตรียมข้อมูล, Feature Engineering จนไปถึงการสร้างโมเดล การทดลองสอนโมเดล (Train Model) และการทดสอบโมเดลด้วยข้อมูลและอัลกอริทึมที่ต่างกัน หรือแม้กระทั่งหาข้อมูลเพิ่มเพื่อนำมาสอนโมเดล ในการทดลองปรับค่าเหล่านี้ยังรวมถึง Hyperparameters หรือที่เรียกกันว่า Hyperparameter Tuning
Hyperparameters เปรียบเสมือนปุ่มหรือแถบต่าง ๆ บนเครื่อง Mixer ที่สามารถหมุนและปรับขึ้นลงเพื่อตั้งค่าที่ Sound Engineer ใช้ในการปรับแต่งเสียง โดยที่เราในฐานะ Data Scientist มีสิ่งที่เรียกว่า Hyperparameters ที่ใช้เพื่อปรับค่าต่าง ๆ ก่อนที่จะสร้างโมเดล
เพื่อใช้ในการควบคุมการทำงานของ Machine Learning Algorithm สิ่งเหล่านี้มีผลกระทบอย่างยิ่งสำหรับการ Train Model เพราะเกี่ยวกับเวลาในการสอนโมเดล ข้อกำหนดเกี่ยวกับสเปคของเครื่องที่ต้องใช้ในการสร้างโมเดล นอกจากนี้ยังส่งผลโดยตรงกับ ค่า Convergence และ Accuracy ของโมเดล
หลังจากที่ทุกคนได้เห็นถึงความสำคัญของ Hyperparameters แล้ว เราลองมาดูกันครับว่าเราสามารถทำอะไรค่าพารามิเตอร์ตัวนี้ได้บ้าง ก่อนอื่นเราควรแยกความแตกต่างก่อนว่า การสร้างโมเดลการเรียนรู้ของเครื่องประกอบไปด้วยพารามิเตอร์ที่แตกต่างกัน 2 ชนิด ได้แก่
- Model Parameters คือ พารามิเตอร์ที่ได้มาระหว่างขั้นตอนการเรียนรู้ข้อมูลของโมเดล (Model Training) เช่น ค่า Weights ที่ใช้ใน Neural Network หรือค่า Coefficients ที่ได้จากการทำ Linear Regression เป็นต้น
- Hyperparameters คือ พารามิเตอร์ต่าง ๆ ที่ผู้ใช้สามารถกำหนดเองได้ก่อนที่โมเดลจะทำการเรียนรู้ เช่น ค่า Learning Rate ที่ใช้ในการควบคุมว่าใน 1 Step ของการเรียนรู้จะปรับค่า Weights ของ Neural Network อย่างไร หรือค่า n_estimators ซึ่งกำหนดจำนวนต้นไม้สำหรับการสร้างโมเดล Random Forest เป็นต้น
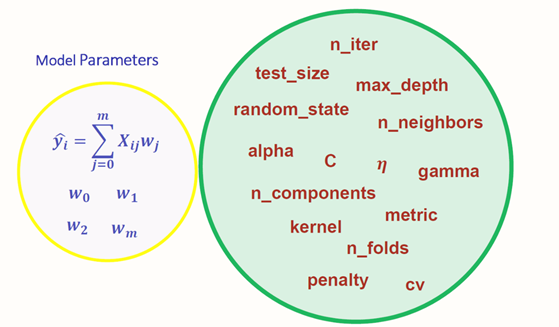
Model Parameters กำหนดว่าจะใช้ข้อมูลในการเรียนรู้อย่างไรเพื่อให้ได้ผลลัพธ์ที่ต้องการโดยจะได้มาระหว่างการเรียนรู้ของโมเดล แต่ Hyperparameters จะกำหนดโครงสร้างของโมเดลตั้งแต่ต้น
ดังนั้นการทำ Hyperparameter Tuning ในบางครั้งอาจจะถูกเรียกว่า Hyperparameter Optimization นับได้ว่าเป็น Optimization Problem รูปแบบหนึ่ง เนื่องจากเราต้องการหาว่า Set ของ Hyperparameters ที่เหมาะสมสำหรับโมเดลประเภทนั้น ๆ ที่จะส่งผลให้โมเดลมีความแม่นยำ (Accuracy) ที่สูง หรือต้องการลดค่า Loss ให้มีค่าต่ำที่สุด
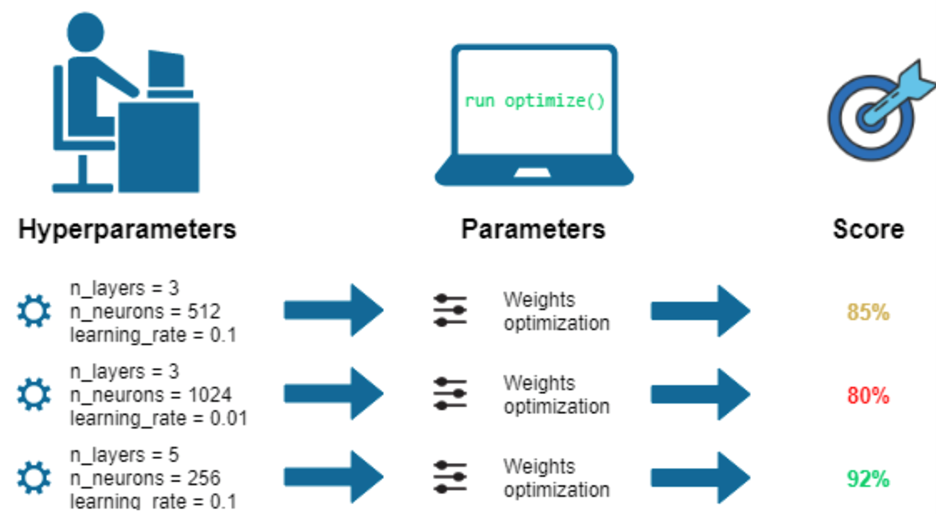
ในปัจจุบันมีเทคนิคมากมายที่ได้ถูกคิดค้นมาเพื่อใช้สำหรับ Hyperparameter Tuning เราอาจจะแบ่งออกเป็น 2 ประเภทใหญ่ ๆ ได้แก่
- Traditional Hyperparameter Tuning คือ วิธีการดั้งเดิมในการปรับค่าชุด Hyperparameters โดยจะเป็นการปรับค่าด้วยการเทียบผลของโมเดลทุก Combination ของ Hyperparameters หรือปรับค่าด้วยตนเองไปเรื่อย ๆ จนกว่าจะเจอชุดของ Hyperparmeter ที่ส่งผลให้โมเดลบรรลุผลตามที่คาดหมายไว้
- Automated Hyperparameter Tuning คือ การปรับค่าชุด Hyperparameters ที่เหมาะสมโดยอัตโนมัติด้วยอัลกอริทีมชนิดต่าง ๆ ที่ถูกออกแบบมาเพื่องานประเภทนี้
ในบทความนี้เพื่อแสดงให้ถึงผลของการทำ Hyperparameter Optimization ในแบบต่าง ๆ ของเทคนิคประเภท Traditional Hyperparameter Tuning เราจะใช้ข้อมูล Titanic จาก Kaggle เพื่อเปรียบเทียบประสิทธิภาพและเวลาในการคำนวณ (Computational Time) ของโมเดล Random Forest Classification เพื่อทำนายว่าผู้โดยสารในเหตุการณ์เรือไททานิคล่มจะรอดชีวิตหรือไม่รอดชีวิต (Binary Classification)
สำหรับ Automated Hyperparameter Tuning สามารถติดตามได้ในบทความถัดไป
Random Forest Classification คือ หนึ่งในโมเดลการเรียนรู้แบบมีผู้สอน (Supervised Learning Model) โมเดลนี้สร้างจาก Decision Tree หลาย ๆ โมเดล (ต้นไม้) ตั้งแต่ 10 ต้นจนถึงมากกว่า 1000 ต้น มารวมกัน โดยข้อมูลที่จะแบ่งออกเป็นหลาย ๆ ชุดไม่ซ้ำกันเพื่อนำไปสร้างโมเดลเพื่อทำนายคลาส (Prediction) หลังจากที่ Decision Tree ทุกโมเดลทำนายคลาสแล้ว คลาสไหนที่ที่มีคะแนนโหวตมากที่สุดจะกลายเป็นการทำนายโดยรวมของโมเดล Random Forest
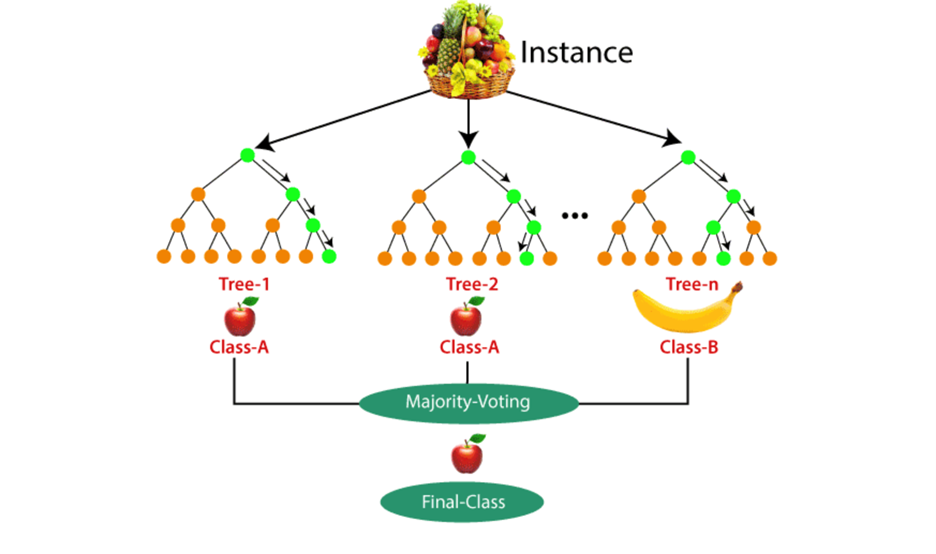
ก่อนอื่นเราจะทำการโหลดข้อมูลและแบ่งข้อมูลเพื่อใช้ในการสร้างโมเดลและทดสอบโมเดล
X=train.drop(['Survived'],axis=1)
y=train['Survived']
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.2, random_state=101)หลังจากนั้นเราจะทำการสร้างโมเดล Random Forest โดยใช้ค่าพารามิเตอร์ตั้งต้น
Baseline model with default parameters:
%%time
from sklearn.metrics import classification_report,confusion_matrix
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
model = RandomForestClassifier(random_state= 101).fit(X_train,y_train)
predictionforest = model.predict(X_test)
print(confusion_matrix(y_test,predictionforest))
print(classification_report(y_test,predictionforest))
acc1 = accuracy_score(y_test,predictionforest) Confusion Matrix
[[91 8]
[31 49]]
precision recall f1-score support
0 0.75 0.92 0.82 99
1 0.86 0.61 0.72 80
accuracy 0.78 179
macro avg 0.80 0.77 0.77 179
weighted avg 0.80 0.78 0.78 179
CPU times: user 238 ms, sys: 13.9 ms, total: 252 ms
Wall time: 262 ms ค่าความแม่นยำของโมเดลที่ทำการใช้พารามิเตอร์เริ่มต้น (default scikit-learn parameters) อยู่ที่ 78.21% โดยคำนวณจากสมการต่อไปนี้
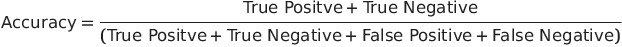
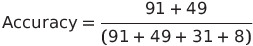
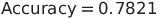
Traditional Hyperparameter Tuning
วิธีการค้นหา Hyperparameter ประเภทนี้มี 3 วิธี ได้แก่
- Manual Search
- Grid Search
- Random Search
Manual Search
สำหรับวิธีนี้ เราจะเลือกค่า Hyperparameter ของโมเดลจากประสบการณ์และความคิดเห็นส่วนบุคคล โดยจะทำการสร้างโมเดลขึ้นมาจากค่าที่เลือกและวัดความแม่นยำไปเรื่อย ๆ จนกว่าจะได้ค่าความแม่นยำที่พึงพอใจ
พารามิเตอร์หลักที่ใช้สำหรับ Random Forest Classification ได้แก่
- Criterion (ค่าตั้งต้น = gini) คือ ฟังก์ชันที่ใช้ในการวัดประสิทธิภาพของการแยกโหนดของ Decision Tree สามารถเลือกได้ระหว่าง gini (Gini Impurity) หรือ Entropy (Information Gain)
- max_depth (ค่าตั้งต้น = None) คือ ค่าความลึกของต้นไม้ (Decision Tree) แต่ละต้นใน Random Forest ยิ่งต้นไม้มีความลึกมากจะสามารถแยกข้อมูลได้ละเอียดมากขึ้น
- max_features (ค่าตั้งต้น = auto) คือ ค่าที่กำหนดจำนวนของฟีเจอร์ที่ Decision Tree แต่ละต้นจะสามารถใช้ในการสร้างโมเดล
- min_samples_leaf (ค่าตั้งต้น = 1) คือ จำนวนข้อมูลขั้นต่ำใน Leaf Node ของแต่ละ Decision Tree ถ้าจำนวนข้อมูลต่ำกว่าค่านี้จะหยุดการแยกโหนด
- min_samples_split (ค่าตั้งต้น = 2) คือ จำนวนขั้นต่ำที่จำเป็นในโหนดเพื่อทำให้เกิดการแยกโหนด
- n_estimators (ค่าตั้งต้น = 100) คือ จำนวน Decision Tree ที่จะใช้ใน Random Forest โดยปกติแล้วยิ่งจำนวนสูงยิ่งส่งผลให้ประสิทธิภาพของโมเดลดียิ่งขึ้น แต่จะทำให้เวลาที่ใช้ในการสร้างโมเดลนานขึ้นเช่นกัน
หากต้องการข้อมูลเพิ่มเติมเกี่ยวกับพารามิเตอร์ของ Random Forest Classification สามารถศึกษาเพิ่มได้ที่ Scikit-learning
เราจะลองทำ Manual Search ด้วยการเปลี่ยนค่า n_estimators ของโมเดลดังโค้ดข้างล่าง
%%time
model = RandomForestClassifier(n_estimators=10, random_state= 101).fit(X_train,y_train)
predictionforest = model.predict(X_test)
print(confusion_matrix(y_test,predictionforest))
print(classification_report(y_test,predictionforest))
acc2 = accuracy_score(y_test,predictionforest) Confusion Matrix
[[91 8]
[33 47]]
precision recall f1-score suppor
0 0.73 0.92 0.82 99
1 0.85 0.59 0.70 80
accuracy 0.77 179
macro avg 0.79 0.75 0.76 179
weighted avg 0.79 0.77 0.76 179
CPU times: user 39.7 ms, sys: 729 µs, total: 40.5 ms
Wall time: 43.1 ms หลังจากที่เราลองใช้ Manual Search หรือการทดลองปรับค่าเองไปเรื่อย ๆ น่าเสียดายที่ค่าความแม่นยำของโมเดลลดลงเล็กน้อย คือ 77.09%
Grid Search
Grid Search หรือการค้นหาแบบกริด เป็นเทคนิคที่ใช้ในการหาค่า Hyperparameter ที่เข้าใจง่ายและตรงไปตรงมา ด้วยการลองใช้พารามิเตอร์ที่กำหนดไว้ล่วงหน้าทุกชุด และประเมินประสิทธิภาพหรือความแม่นยำของโมเดลแต่ละชุด จะเป็นการลองสร้างโมเดลจากค่าของ Hyperparameter ทุกชุด รูปแบบของการทำงานจะคล้ายกริด โดยค่าทั้งหมดจะอยู่ในรูปของเมทริกซ์ (Matrix) พารามิเตอร์แต่ละชุดจะถูกนำมาพิจารณาและสังเกตความถูกต้อง เมื่อชุดของ Hyperparameter ทั้งหมดได้รับการประเมินแล้ว โมเดลที่มีชุดพารามิเตอร์ที่ให้ความแม่นยำสูงสุดจะถือว่าดีที่สุด สำหรับตัวอย่างการเขียนโค้ดของ Grid Search เราจะเพิ่มการทำ Cross-Validation สำหรับการสร้างโมเดลเข้าไปด้วย
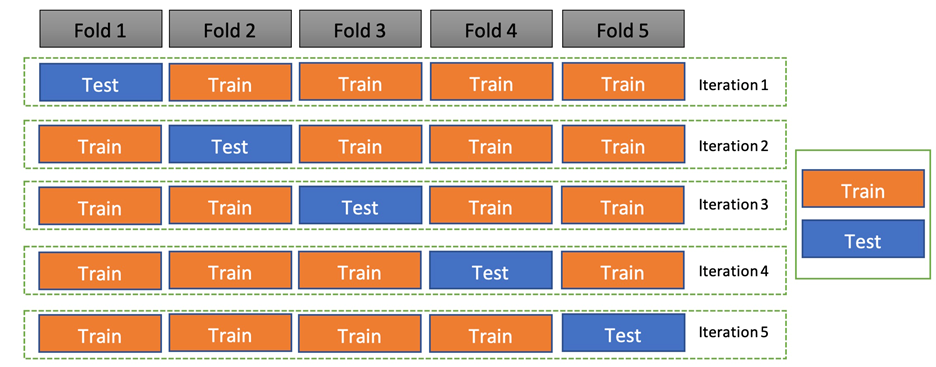
โดยทั่วไปแล้วขั้นตอนในการสร้าง Machine Learning เราจะแบ่งข้อมูลออกเป็น 2 ส่วน ได้แก่ ข้อมูลสำหรับสร้างโมเดล (Training Data) และข้อมูลสำหรับทดสอบโมเดล (Test Data) เพื่อที่จะทดสอบประสิทธิภาพของโมเดลกับชุดข้อมูลที่ไม่เคยเห็นมาก่อน สำหรับการทำ Cross-Validation นั้นเราเป็นการแบ่งข้อมูลของ Training Data ออกเป็น N ส่วนเพื่อป้องกันการเกิด Overfit ของโมเดล ซึ่ง 1 ในวิธีที่ใช้กันมากที่สุดคือ K-Fold Validation
K-Fold Validation จะแบ่งข้อมูล Training Data ออกเป็น N ส่วน จากนั้นจะสร้างโมเดลด้วย N-1 ส่วน และทดสอบโมเดลกับส่วนที่เหลือ ในการวนซ้ำแต่ละครั้งเราจะเปลี่ยนส่วนของที่ใช้ในการทดสอบโมเดล เมื่อเราสร้างโมเดลครบ N ครั้ง อัลกอริทึมจะทำการหาค่าเฉลี่ยของผลของการสร้างโมเดล เพื่อให้ได้ผลลัพธ์ที่มีประสิทธิภาพที่สุด การใช้ Cross-Validation สำคัญมากต่อการทำ Hyperparameter Optimization เนื่องจากเราสามารถหลีกเลี่ยงการใช้ Hyperparameter บางตัวซึ่งทำงานได้ดีกับ Training Data แต่ไม่ส่งผลดีต่อ Test Data
หลักจากที่เราได้รู้เกี่ยวกับหลักการทำงานของ Grid Search แล้วเราจะเริ่มเขียนโค้ดกัน ก่อนอื่นเราต้องสร้างกริดของ Hyperparameter เพื่อทำหน้าที่เป็น Search Space ซึ่งขนาดของ Search Space จะเท่ากับผลคูณของทุกพารามิเตอร์ทั้งหมด โดยตัวอย่างที่แสดงด้านล่างจะมีขนาด 2*10*4*5*3*5 = 6,000 Combinations
parameters ={
'max_depth': [10, 20, 30, 40, 50, 60, 70, 80, 90, 100],
'criterion' : ['gini', 'entropy'],
'max_features': [0.3,0.5,0.7,0.9],
'min_samples_leaf': [3,5,7,10,15],
'min_samples_split': [2,5,10],
'n_estimators': [50,100,200,400,600]} ในการเขียนโค้ดเพื่อทำ Grid Search เราสามารถใช้ Library ของ Scikit-learn ที่เรียกว่า GridSearchSV() ซึ่งในที่นี้เราจะทำการแบ่ง Training Set ออกเป็น 4 Folds (cv = 4)
%%time
from sklearn.model_selection import GridSearchCV
clf = RandomForestClassifier()
model = GridSearchCV(clf, parameters, cv=4, scoring='accuracy',n_jobs=-1)
model.fit(X_train, y_train)
predictionforest = model.best_estimator_.predict(X_test)
print(confusion_matrix(y_test,predictionforest))
print(classification_report(y_test,predictionforest))
acc3 = accuracy_score(y_test,predictionforest) Confusion Matrix
สังเกตวิธีการเขียน โคล่อน (:) และ ไม้ยมก (ๆ) ตามหลักราชบัณฑิตยสถาน จะเขียนโดยมี space เว้นวรรค
[[94 5]
[24 56]]
precision recall f1-score support
0 0.80 0.95 0.87 99
1 0.92 0.70 0.79 80
accuracy 0.84 179
macro avg 0.86 0.82 0.83 179
weighted avg 0.85 0.84 0.83 179
CPU times: user 3min 10s, sys: 12 s, total: 3min 22s
Wall time: 2h 56min 28s ค่าความแม่นยำหลังจากใช้ Grid Search สำหรับข้อมูลชุดนี้มีค่าสูงมาก คือ 83.84% ซึ่งวิธีนี้สามารถสร้างได้ง่าย ทำงานแบบ Parallel ได้ และมีประสิทธิภาพสูง โดยมีข้อแม้ว่าเราต้องกำหนด Search Space ที่เหมาะสม เพราะวิธีนี้จะทำการสร้างโมเดลโดยใช้ Hyperparameter ทุกชุดเพื่อหา ชุดของ Hyperparameter ที่ดีที่สุด แต่ข้อเสียที่เห็นได้ชัด คือ เวลาที่ใช้ในการสร้างโมเดลที่นาน เห็นได้จากเวลาที่ใช้ในการสร้างโมเดลถึง 2 ชั่วโมง 56 นาที และไม่เหมาะกับโมเดลที่เรากำหนด Search Space ที่กว้างมาก นอกจากนี้ประสิทธิภาพของโมเดลยังขึ้นอยู่กับ Search Space ที่เรากำหนดขั้นต้นเท่านั้น
Random Search
วิธีการทำงานของ Random Search คล้ายคลึงกับการทำ Grid Search แต่แทนที่จะลองใช้พารามิเตอร์ที่กำหนดไว้ล่วงหน้าในกริดทุกชุด RandomSearch จะทำการสุ่มเลือกค่าพารามิเตอร์จากกริดที่สร้างขึ้น ดังนั้นการทำ Random Search จะไม่รับประกันว่าเราจะได้โมเดลที่มีประสิทธิภาพที่สุดเหมือนกับ Grid Search แต่วิธีมีประสิทธิภาพสูงในการใช้งานจริงเนื่องจากใช้เวลาในการสร้างโมเดลที่น้อยมาก
ในการเขียนโค้ดเพื่อทำ Random Search เราจะใช้ Library จาก Scikit-learn ที่เรียกว่า RandomizedSearchCV() โดยเราจะแบ่ง Training Set ของเป็น 4 Folds (cv = 4) และจะให้โมเดลทำการสุ่มค่า Hyperparameter ออกมา 80 ชุด (n_iter = 80) เพื่อหาชุดของค่าพารามิเตอร์ที่ดีที่สุด
%%time
from sklearn.model_selection import RandomizedSearchCV
clf = RandomForestClassifier()
model = RandomizedSearchCV(estimator = clf, param_distributions = parameters, n_iter = 80, cv = 4, verbose= 1, random_state= 101, n_jobs = -1)
model.fit(X_train,y_train)
predictionforest = model.best_estimator_.predict(X_test)
print(confusion_matrix(y_test,predictionforest))
print(classification_report(y_test,predictionforest))
acc4 = accuracy_score(y_test,predictionforest) Confusion Matrix
[[93 6]
[29 51]]
precision recall f1-score support
0 0.76 0.94 0.84 99
1 0.89 0.64 0.74 80
accuracy 0.80 179
macro avg 0.83 0.79 0.79 179
weighted avg 0.82 0.80 0.80 179
CPU times: user 2.99 s, sys: 196 ms, total: 3.19 s
Wall time: 2min 38s สำหรับผลของโมเดลที่ใช้ Random Search จะเห็นได้ว่าค่าความแม่นยำพัฒนาจาก Baseline ที่ 78.21% เป็น 80.45% โดยมีความแม่นยำเพิ่มขึ้น 2.24% แต่ใช้เวลาในการสร้างโมเดลเพียง 2 นาที 38 วินาที
การวิเคราะห์ผลของ Hyperparameter Tuning
| Method | Accuracy | Computational Time (sec) | Improvement |
|---|---|---|---|
| Baseline Model | 78.21% | 191 | – |
| Manual Search | 77.09% | 43.21 | -1.43% |
| Grid Search | 84.83% | 10,588 | 8.46% |
| Random Search | 80.45% | 158 | 2.86% |
ตารางเปรียบเทียบ Accuracy, Computational Time ของ Manual Search, Grid Search, Random Search กับ Baseline model ด้วยพารามิเตอร์เริ่มต้น
จากตารางข้างต้น จะเห็นได้ว่าค่าความแม่นยำจากการทดลองใช้ Manual Search นั้นต่ำกว่า Baseline ที่เราตั้งไว้ตอนต้น เนื่องจากวิธีการนี้จะเป็นการปรับค่าโดยขึ้นอยู่กับความต้องการของผู้ทดลอง ซึ่งอาจจะต้องทำไปเรื่อย ๆ จนกว่าจะได้ความแม่นยำที่ต้องการ ในส่วนของ Grid Search นั้นมีข้อดีคือ ความแม่นยำของโมเดลสูงถึง 83.84% สูงที่สุดในการทดลองทั้งหมด ซึ่งมีค่าสูงกว่า Baseline Model ถึง 5.63% แต่ในแง่ของเวลาในการสร้างโมเดลนั้นใช้เวลานานถึง 10,588 วินาที (2 ชั่วโมง 56 นาที 28 วินาที) เทียบกับ Random Search ที่มีค่าความแม่นยำเพียง 80.45% แต่ข้อได้เปรียบของ Random Search คือ เวลาในการสร้างโมเดลที่ใช้เพียง 158 วินาที (2 นาที 38 วินาที) ซึ่งใช้เวลาน้อยกว่า Grid Search ถึง 67 เท่า สำหรับปัญหาง่าย ๆ ส่วนใหญ่นั้น Random Search จะเป็นตัวเลือกที่เป็นไปได้มากที่สุดสำหรับ Hyperparameter Tuning นอกจากนี้ผลลัพธ์ที่ได้จะขึ้นอยู่กับ Search Space ที่เราสร้างเป็นกริด และชุดข้อมูลที่ใช้ ดังนั้นในสถานการณ์ที่แตกต่างกัน เทคนิค Hyperparameter Tuning ที่แตกต่างกันไปอาจจะทำให้ได้ผลดีกว่า
บทสรุป
ท้ายที่สุดแล้วการทำ Machine Learning คือการหาสมดุลระหว่างเวลาในการคำนวณของโมเดลและประสิทธิภาพของโมเดล การที่โมเดลมีประสิทธิภาพที่ดีมากแต่ใช้เวลาคำนวณนานเกินไป จนผลของโมเดลอาจจะไม่ตอบโจทย์ที่ต้องการใช้ได้ทันท่วงที หรือการที่โมเดลสามารถคำนวณผลด้วยเวลาเพียง 5 นาที แต่ประสิทธิภาพของโมเดลต่ำไปก็ไม่สามารถใช้งานจริงได้เช่นกัน ซึ่งในบทความนี้เราได้แสดงให้เห็นถึงเทคนิค Random Search ซึ่งเป็นวิธีหนึ่งที่สามารถหาจุดสมดุลของโมเดลที่มีความแม่นยำในระดับที่ดี แต่ไม่ใช้เวลาในการคำนวณมากจนเกินไป จากตัวอย่างชุดข้อมูล Titanic ที่ได้นำเสนอไปข้างต้น ส่วนในการทำงานจริง การทดลองใช้ Hyperparameter Tuning วิธีต่าง ๆ ในระหว่างการพัฒนาโมเดลจะสามารถช่วยในการปรับปรุงประสิทธิภาพของโมเดลได้ดียิ่งขึ้น
ผมได้แนบโค้ดไว้สำหรับให้ทุกท่านได้ทดลองใน Github
เนื้อหาโดย ทินกร ม้าลายทอง ตรวจทานและปรับปรุงโดย ปพจน์ ธรรมเจริญพร
Project Manager & Data Scientist at Big Data Institute (Public Organization), BDI


Former-Editor-in-Chief at BigData.go.th and Senior Data Scientist at Government Big Data Institute (GBDi )









