
ทุกคนพอจะรู้กันอยู่แล้วว่าในการเรียนรู้ของเครื่อง (Machine Learning) จะประกอบไปด้วย 5 งานหลัก ๆ ได้แก่ การรวบรวมข้อมูล (Data Aggregation), การประมวลผลข้อมูล (Data Preprocessing), การฝึกฝนโมเดล (Training), การทดสอบโมเดล (Testing) และ การปรับปรุงเพื่อเพิ่มประสิทธิภาพของโมเดล (Improving) ซึ่งเทคนิคที่นิยมใช้ในการเพิ่มประสิทธิภาพของโมเดล คือการปรับไฮเปอร์พารามิเตอร์ (Hyperparameter Tuning) (อ่านเพิ่มเติมได้ในบทความนี้ Link) ซึ่งไฮเปอร์พารามิเตอร์ก็คือตัวควบคุมกระบวนการเรียนรู้ของโมเดลนั่นเอง แต่อย่างไรก็ตามการปรับไฮเปอร์พารามิเตอร์อาจใช้เวลานานรวมถึงต้องใช้ทรัพยากรในการคำนวณที่มาก และสิ่งที่เลวร้ายที่สุด คือเมื่อปรับเสร็จแล้วอาจจะไม่ได้ผลลัพธ์ที่ดีขึ้นเลย ถึงตรงนี้ก็อาจสงสัยแล้วว่าบางทีทำไมผลลัพธ์ถึงไม่ดีขึ้นเลย ซึ่ง 1 ในเหตุผลหลัก ๆ คือไฮเปอร์พารามิเตอร์ไม่มีนัยสำคัญทางสถิติต่อประสิทธิภาพของโมเดล จึงทำให้ต่อให้เราปรับกี่ครั้งก็ตามก็ไม่มีทางที่จะได้ผลลัพธ์ที่ดีขึ้น
แล้วเราจะสามารถรู้ได้อย่างไรละว่าไฮเปอร์พารามิเตอร์ที่เราใช้นั้นมีนัยสำคัญทางสถิติต่อประสิทธิภาพของโมเดลหรือไม่ วิธีการที่เราจะมาแนะนำกันในบทความนี้ก็คือ การวิเคราะห์ความอ่อนไหว (Sensitivity Analysis) วิธีการนี้เป็นวิธีการที่ใช้ในการวิเคราะห์ความหนักแน่นหรือความเสถียรของผลลัพธ์จากการทำการทดลอง โดยจะทดสอบจากการเปลี่ยนแปลงค่าบางอย่างในการศึกษานั้น ๆ เพื่อหาว่าการเปลี่ยนค่านั้น ๆ มีผลกระทบต่อผลลัพธ์สุดท้ายหรือไม่ ซึ่งวิธีนี้จะถือเป็นทางออกที่จะช่วยให้เราสามารถทราบถึงนัยสำคัญทางสถิติของไฮเปอร์พารามิเตอร์ได้ หากเราทราบถึงนัยสำคัญทางสถิติของไฮเปอร์พารามิเตอร์ก่อน เราก็ไม่จำเป็นที่จะต้องเสียเวลาที่จะ นำไฮเปอร์พารามิเตอร์ที่ไม่มีนัยสำคัญทางสถิติมาทำการปรับไฮเปอร์พารามิเตอร์ และเราจะทำการคัดเอาเฉพาะไฮเปอร์พารามิเตอร์ที่สำคัญเท่านั้นมาใช้
ถึงตรงนี้ทุกคนก็คงจะเห็นถึงความสำคัญในการใช้วิธีการวิเคราะห์ความอ่อนไหว (Sensitivity Analysis) แล้วใช่มั้ยครับ ต่อไปเราจะพูดถึงวิธีการวิเคราะห์ความอ่อนไหว ที่เป็นที่รู้จักกันดี 2 วิธีคือ
1. การวิเคราะห์การเปลี่ยนแปลงทีละครั้ง (One-at-a-time)
วิธีนี้จะทำการเปลี่ยนค่าของไฮเปอร์พารามิเตอร์ 1 ตัวที่เรากำหนดไปเรื่อย ๆ โดยที่ไฮเปอร์พารามิเตอร์ตัวอื่น ๆ จะไม่มีการเปลี่ยนแปลง ซึ่งเป้าหมายหลักของการใช้วิธีการนี้ ก็เพื่อต้องการที่จะทดสอบว่า ไฮเปอร์พารามิเตอร์ที่เราเลือกนั้นพอมีการเปลี่ยนแปลงค่าไป ส่งผลให้ประสิทธิภาพของโมเดลมีการเปลี่ยนแปลงบ้างหรือไม่ ซึ่งถ้าหากประสิทธิภาพของโมเดลมีการเปลี่ยนแปลงอย่างมีนัยสำคัญก็จะหมายความว่า ไฮเปอร์พารามิเตอร์ตัวนั้น เหมาะสมที่จะนำไปใช้ต่อในการปรับไฮเปอร์พารามิเตอร์ เรามาดูตัวอย่างสัก 1 ตัวอย่างกันนะครับ ตารางด้านล่างนี้จะประกอบไปด้วย ไฮเปอร์พารามิเตอร์ ทั้ง 4 ตัวของโมเดลการสุ่มป่าไม้ (Random Forest) จากตารางจะสังเกตได้ว่าจะมีเพียง max depth เท่านั้นที่ทำการเปลี่ยนค่าไปเรื่อย ๆ ทีละ 5 จนถึง 50 โดยที่ไฮเปอร์พารามิเตอร์ตัวอื่น ๆ ยังคงที่ค่าเอาไว้ ซึ่งหากการเปลี่ยนค่าของ max depth ส่งผลให้ประสิทธิภาพของโมเดลมีการเปลี่ยนแปลงอย่างมีนัยสำคัญ จะหมายความว่า max depth เหมาะสมสำหรับใช้ในการปรับไฮเปอร์พารามิเตอร์
| n-estimator | max depth | min sample leaf | min sample split |
|---|---|---|---|
| 200 | 5 | 5 | 10 |
| 200 | 10 | 5 | 10 |
| 200 | 15 | 5 | 10 |
| 200 | 20 | 5 | 10 |
| 200 | 25 | 5 | 10 |
| 200 | 30 | 5 | 10 |
| 200 | 35 | 5 | 10 |
| 200 | 40 | 5 | 10 |
| 200 | 45 | 5 | 10 |
| 200 | 50 | 5 | 10 |
2. การสุ่มตัวอย่างแบบละตินไฮเปอร์คิวบ์ (Latin Hypercube Sampling)
ในการสุ่มตัวอย่างแบบละตินไฮเปอร์คิวบ์ จะทำการสุ่มตัวอย่างของไฮเปอร์พารามิเตอร์ในจุดที่แตกต่างกันในเมทริกซ์ดังรูปด้านล่าง ซึ่งสิ่งแรกที่เราต้องทำก่อนเลย คือเราจะต้องกำหนดจำนวนจุดตัวอย่าง (ตัวอย่างในที่นี้ก็คือ ไฮเปอร์พารามิเตอร์) ที่จะต้องถูกสร้างขึ้นมา ซึ่งโดยส่วนใหญ่แล้วจำนวนจุดตัวอย่างที่นิยมใช้กันคือ 100 จุดซึ่งอ้างอิงมาจาก Statistichowto และ ผลงานตีพิมพ์ของ Bozkurt et al. และเมื่อเราทำการกำหนดจำนวนจุดตัวอย่างเรียบร้อยแล้ว จึงทำการสุ่มจุดตัวอย่างลงในแถวและคอลัมน์ในเมทริกซ์ ซึ่งในขั้นตอนนี้ก็จะมีการจดจำจุดตัวอย่างที่ได้ถูกทำการสุ่มลงไปบนเมทริกซ์แล้ว ซึ่งจะเหมือนกับหมากรุก ที่อยู่บนกระดานโดยไม่มีการสุ่มที่ซ้ำตำแหน่งเดิม กระบวนการนี้จะทำการสุ่มจุดตัวอย่างจนครบตามจำนวนที่เรากำหนดไว้ตอนแรก นอกจากนี้การสุ่มตัวอย่างแบบละตินไฮเปอร์คิวบ์สามารถพิจารณาไฮเปอร์พารามิเตอร์ทั้งหมดพร้อมกันได้ ซึ่งต่างกับการวิเคราะห์การเปลี่ยนแปลงทีละครั้งที่จะสนใจเฉพาะไฮเปอร์พารามิเตอร์ตัวเดียวที่ทำการเปลี่ยนค่าไปเรื่อย ๆ เท่านั้น
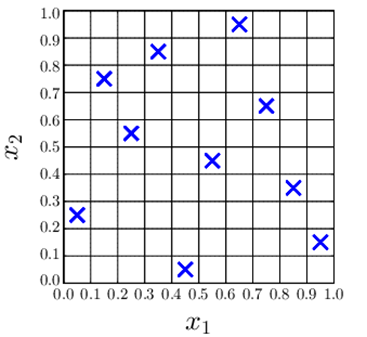
หลังจากที่เราได้รู้จักหลักการของ การวิเคราะห์การเปลี่ยนแปลงทีละครั้ง และการสุ่มตัวอย่างแบบละตินไฮเปอร์คิวบ์แล้ว ทุกคนก็อาจจะสงสัยว่าแล้วมันหานัยสำคัญทางสถิติของแต่ละไฮเปอร์พารามิเตอร์จากไหนละ เพราะทั้ง 2 วิธ๊นี้เป็นเหมือนการสร้างชุดข้อมูลขึ้นมาอย่างเดียว การวิเคราะห์ความแปรปรวน (Analysis of Variance) จึงถูกนำมาใช้เพื่อใช้ในการหานัยสำคัญทางสถิติหลังจากที่ได้ชุดข้อมูลจาก 2 วิธีดังกล่าวแล้ว
การวิเคราะห์ความแปรปรวน (Analysis of Variance: ANOVA)
การวิเคราะห์ความแปรปรวนเป็นการวิเคราะห์เพื่อ ทดสอบความแตกต่างของค่าเฉลี่ยของประชากรที่มากกว่า 2 กลุ่มขึ้นไป (ตั้งแต่ 3 กลุ่ม) เพื่อเปรียบเทียบความแตกต่างของประชากร ซึ่งการวิเคราะห์ความแปรปรวนนี้จะถูกใช้เพื่อระบุระดับนัยสำคัญของไฮเปอร์พารามิเตอร์ที่มีผลต่อประสิทธิภาพของแบบจำลอง ระดับนัยสำคัญ (p-value) มาตรฐานที่ใช้ในการทดลองส่วนใหญ่ คือ 0.05 ซึ่งบ่งชี้ว่าหากค่าระดับนัยสำคัญ ของไฮเปอร์พารามิเตอร์น้อยกว่า 0.05 (p-value < 0.05) จะมีความน่าจะเป็นทางสถิติ 99.5% ที่จะมีผลกระทบอย่างมีนัยสำคัญต่อประสิทธิภาพของแบบจำลอง
เรามาลองของจริงกัน
หลังจากที่ทุกคนได้รู้ถึงหลักการต่าง ๆ ที่ต้องใช้ในการวิเคราะห์ความอ่อนไหวของไฮเปอร์พารามิเตอร์แล้ว เราจะทำการยกตัวอย่างเล็กน้อย ในการวิเคราะห์หาความอ่อนไหวของไฮเปอร์พารามิเตอร์สำหรับโมเดลป่าไม้ (Random Forest) ด้วยวิธีการวิเคราะห์การเปลี่ยนแปลงทีละครั้ง ร่วมกับการวิเคราะห์ความแปรปรวนซึ่งเราจะใช้ 4 ไฮเปอร์พารามิเตอร์ที่นิยมใช้กันของโมเดลการสุ่มป่าไม้ ได้แก่ n-estimator, max depth, min sample leaf และ min sample split และชุดข้อมูลที่จะใช้ในการทดสอบประสิทธิภาพของโมเดล คือข้อมูลการนัดพบแพทย์ เพื่อทำนายว่าผู้ป่วยจะมาพบแพทย์ตามนัดในครั้งถัดไปหรือไม่ ซึ่งถูกนำมาจาก Kaggle โดยที่ตารางชุดข้อมูลจะแสดงถึงจำนวนฟีเจอร์และจำนวนข้อมูลของชุดข้อมูล และตารางการตั้งค่าไฮเปอร์พารามิเตอร์ของการวิเคราะห์การเปลี่ยนแปลงทีละครั้งจะแสดงถึงการตั้งค่าของไฮเปอร์พารามิเตอร์ที่จะใช้ในการวิเคราะห์การเปลี่ยนแปลงทีละครั้ง
| ชุดข้อมูลการนัดพบแพทย์ | |
|---|---|
| ฟีเจอร์ | 14 |
| จำนวนข้อมูลทั้งหมด | 110,527 |
ซึ่งจากที่เราเคยอธิบายไปแล้วว่าการ วิเคราะห์การเปลี่ยนแปลงทีละครั้งจะทำการเปลี่ยนค่าของไฮเปอร์พารามิเตอร์ 1 ตัวที่เรากำหนดไปเรื่อย ๆ โดยที่ไฮเปอร์พารามิเตอร์ตัวอื่น ๆ จะไม่มีการเปลี่ยนแปลง และเราได้กำหนดว่าจำนวนค่าที่เปลี่ยนแปลงคือ 20 ซึ่งหมายความว่า จะมีการสร้างลำดับของตัวเลขจำนวนเต็ม 20 ตัว ตัวอย่างเช่นชุดของการเปลี่ยนแปลงค่า max depth คือ {5, 10, 15, …, 100} โดยที่ค่าไฮเปอร์พารามิเตอร์อื่น ๆ จะไม่มีการเปลี่ยนแปลง และ ค่าคงที่สำหรับไฮเปอร์พารามิเตอร์ตัวอื่น ๆ จะใช้เป็นค่ามาตรฐาน ซึ่งพิจารณาจากประสบการณ์ที่เคยใช้บ่อย ๆ และอ้างอิงจากหลาย ๆ บทความ เช่น บทความของ Koehrsen และ Meinert จาก towardsdatascience และผลงานตีพิมพ์ของ Yang & Shami
| ไฮเปอร์พารามิเตอร์ | ช่วงของไฮเปอร์พารามิเตอร์ | ค่ามาตรฐาน | จำนวนค่าที่เปลี่ยนแปลง |
|---|---|---|---|
| n-estimator | (5, 385) | 100 | 20 |
| max depth | (5, 100) | 15 | 20 |
| min sample leaf | (1, 20) | 5 | 20 |
| min sample split | (2, 40) | 10 | 20 |
ในขั้นตอนสุดท้ายเราจะใช้การวิเคราะห์ความแปรปรวนเพื่อที่จะหาว่าไฮเปอร์พารามิเตอร์ตัวไหนสำคัญกับประสิทธิภาพของโมเดลบ้าง ซึ่งตัววัดประสิทธิภาพที่เราใช้ในส่วนนี้คือ ค่าความแม่นยำ (Accuracy) และ f1-score โดยที่ตารางด้านล่างแสดงถึงผลลัพธ์ที่ได้จากการวิเคราะห์ความแปรปรวนของไฮเปอร์พารามิเตอร์ แต่ละตัวโดยที่ Sig. ในที่นี้หมายถึงไฮเปอร์พารามิเตอร์ตัวนั้นสำคัญต่อประสิทธิภาพของโมเดล ตัวอย่างเช่น n-estimator, max depth, min sample leaf จะมีนัยสำคัญต่อค่าความแม่นยำของโมเดลการสุ่มป่าไม้ในข้อมูลการนัดพบแพทย์ เป็นต้น
| ไฮเปอร์พารามิเตอร์ | ค่าความแม่นยำ | ค่า f1-score |
|---|---|---|
| n-estimator | Sig | – |
| max depth | Sig | – |
| min sample leaf | Sig | Sig |
| min sample split | – | Sig |
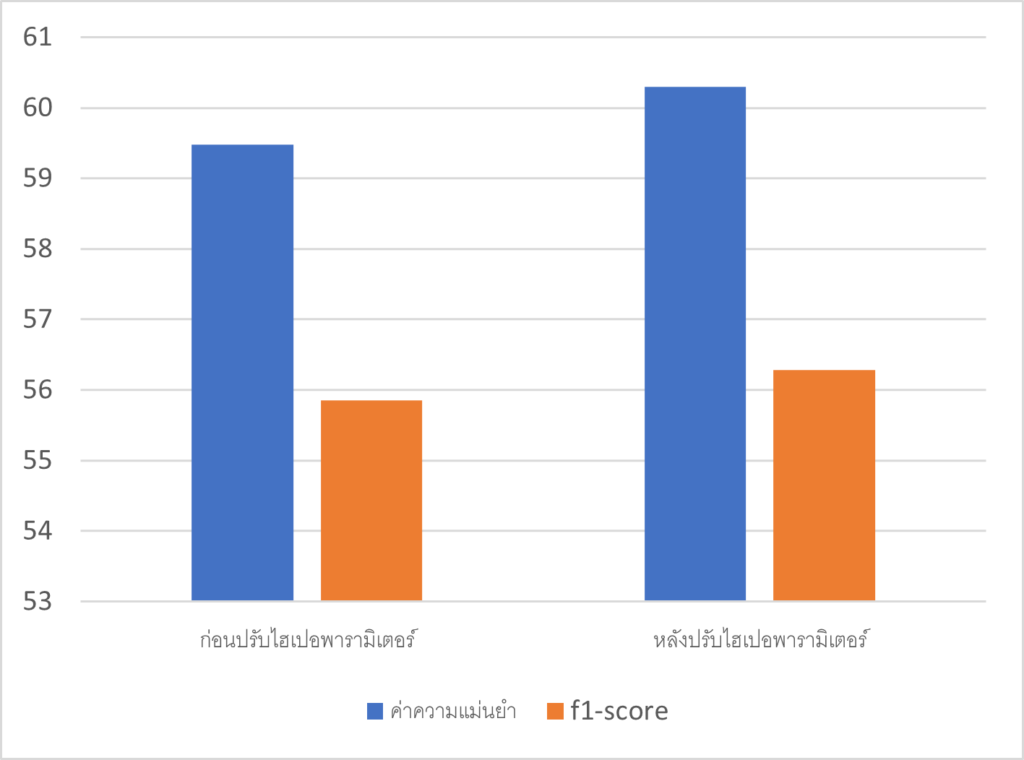
ไหน ๆ เราก็รู้กันแล้วว่าไฮเปอร์พารามิเตอร์ตัวไหนเหมาะสมที่จะใช้ในการปรับไฮเปอร์พารามิเตอร์สำหรับข้อมูลการนัดพบแพทย์แล้ว เราเลยลองทำการปรับไฮเปอร์พารามิเตอร์เพื่อเทียบผลลัพธ์ของโมเดลการสุ่มป่าไม้ก่อนและหลังปรับดูว่ามันดีขึ้นจริง ๆ ไหม ซึ่งในการปรับไฮเปอร์พารามิเตอร์ครั้งนี้เราจะใช้ การค้นหาแบบสุ่ม (random search) และช่วงของไฮเปอร์พารามิเตอร์จากตารางการตั้งค่าไฮเปอร์พารามิเตอร์ ซึ่งเมื่อเราได้ลองปรับไฮเปอร์พารามิเตอร์ดูแล้วผลลัพธ์ของค่าความแม่นยำ และ f1-score ในข้อมูลการนัดพบแพทย์เพิ่มขึ้นจาก 59.48 เป็น 60.3 และ 55.85 เป็น 56.28 ซึ่งแสดงในแผนภูมิด้างล่างนี้ และจากผลดังกล่าวก็จะเห็นได้ว่าค่าความแม่นยำ และ f1-score จากโมเดลการสุ่มป่าไม้นั้นเพิ่มขึ้น ถึงแม้ว่าอาจจะเพิ่มราว ๆ ไม่ถึง 1 เนื่องจากข้อมูลที่เรานำมาใช้เป็นข้อมูลที่ไม่ซับซ้อนมากนัก ซึ่งถ้าหากเราใช้การปรับไฮเปอร์พารามิเตอร์กับข้อมูลที่ซับซ้อนมากขึ้น ความต่างของผลลัพธ์ก็จะยิ่งเห็นชัดขึ้น
นี่ก็เป็นตัวอย่างสำหรับการวิเคราะห์ความอ่อนไหวของไฮเปอร์พารามิเตอร์ของโมเดลการสุ่มป่าไม้นั่นเอง มาถึงจุดนี้ก็คงจะเข้าใจแล้วว่า เราจะต้องคัดเลือกไฮเปอร์พารามิเตอร์ตัวไหนที่เหมาะสมสำหรับการปรับไฮเปอร์พารามิเตอร์ ซึ่งเนื้อหาที่เกี่ยวกับการปรับไฮเปอร์พารามิเตอร์สามารถดูเพิ่มเติมได้จากบทความใน bigdata.go.th ซึ่งจะพูดถึงการปรับไฮเปอร์พารามิเตอร์ด้วย การค้นหาแบบกริด (grid search) และ การค้นหาแบบสุ่ม (random search) ซึ่งจริง ๆ แล้วยังมีอัลกอริทึมอื่น ๆ ที่สามารถนำไปใช้ในการปรับไฮเปอร์พารามิเตอร์ได้อีกเช่นกัน
นอกจากนี้เทคนิคการปรับไฮเปอร์พารามิเตอร์ยังมีอีกหลายแบบที่น่าสนใจ เช่น ขั้นตอนวิธีหาค่าเหมาะสมที่สุดแบบกลุ่มอนุภาค (Particle Swarm Optimization) และขั้นตอนวิธีอาณานิคมมด (Ant Colony Optimization) ซึ่งในโอกาสหน้าเราจะมาทำความรู้จักกันนะครับ
สุดท้ายนี้ก็หวังว่าทุกคนจะได้รับความรู้เกี่ยวกับเรื่องการวิเคราะห์ความอ่อนไหว และเหตุผลที่ต้องใช้ ซึ่งสามารถทำให้ทุกคนนำไปต่อยอดในการปรับไฮเปอร์พารามิเตอร์ให้เข้ากับงานของตัวเองได้ครับ
เนื้อหาโดย ทิติยะ ตรีทิพไกวัลพร
ตรวจทานและปรับปรุงโดย นววิทย์ พงศ์อนันต์ และ ปพจน์ ธรรมเจริญพร










Former-Editor-in-Chief at BigData.go.th and Senior Data Scientist at Government Big Data Institute (GBDi )









