
“การถ่ายทอดการเรียนรู้ (Transfer learning)” หลายคนอาจเคยได้ยินมาบ้างเกี่ยวกับการถ่ายทอดการเรียนรู้ในคอมพิวเตอร์กับงานด้านภาพหรือวิดีโอ แต่รู้หรือไม่ว่า การถ่ายทอดการเรียนรู้ก็สามารถประยุกต์ใช้กับงานด้านภาษาได้เช่นกัน
ในช่วงหลายปีที่ผ่านมา มนุษย์มีความสามารถในการคาดการณ์สิ่งต่าง ๆ ได้ดียิ่งขึ้นโดยอาศัยเทคโนโลยีที่เรียกว่า การเรียนรู้ของเครื่อง (Machine learning) หลักการทำงานของเทคโนโลยีดังกล่าวคือการเรียนรู้และทำความเข้าใจข้อมูลที่ได้รับ และสร้างเป็นแบบจำลองที่มีประสิทธิภาพ การเรียนรู้ของแบบจำลองในปัจจุบันส่วนใหญ่เป็นงานเฉพาะด้าน เช่น การเรียนรู้เพื่อสร้างแบบจำลองสำหรับการจัดประเภทรูปภาพ การเรียนรู้เพื่อสร้างแบบจำลองสำหรับการคาดการณ์ล่วงหน้า ซึ่งแบบจำลองที่ถูกสร้างสำหรับงานเฉพาะด้านจะมีประสิทธิภาพที่สูงกับงานนั้น ๆ แต่ในทางกลับกัน แบบจำลองเหล่านั้น อาจเกิดข้อผิดพลาดได้ง่ายกับเงื่อนไข หรือข้อมูลที่ไม่เคยพบมาก่อน ในความเป็นจริง ข้อมูลที่ถูกนำมาให้แบบจำลองเรียนรู้อาจไม่สมบูรณ์ หรือไม่สามารถใช้งานได้ทันทีเหมือนแบบฝึกหัดที่ครูสอนในห้องเรียน ข้อมูลจริงมีโอกาสเกิดทั้ง ความผิดพลาด ความซับซ้อน และมีจำนวนที่น้อย ยกตัวอย่างเช่น ข้อมูลภาพถ่ายความร้อนในห้องน้ำสำหรับแบบจำลองการตรวจจับการล้ม[1] ซึ่งภาพถ่ายความร้อนในห้องน้ำสำหรับการตรวจจับการล้มนั้นเป็นข้อมูลที่เก็บได้ยาก เนื่องจากการล้มในห้องน้ำไม่ได้เกิดขึ้นบ่อย จึงทำให้ข้อมูลที่เก็บได้มีจำนวนน้อย อาจส่งผลให้แบบจำลองที่ถูกเรียนรู้จากข้อมูลดังกล่าวไม่สามารถคาดการณ์สิ่งต่าง ๆ ได้ดีพอ การถ่ายทอดการเรียนรู้จึงถูกนำมาใช้เพื่อแก้ไขปัญหาดังกล่าว โดยมีหลักการทำงานคือ การถ่ายทอดการเรียนรู้จากแบบจำลองหนึ่งไปยังอีกแบบจำลองหนึ่งดังภาพที่ 1
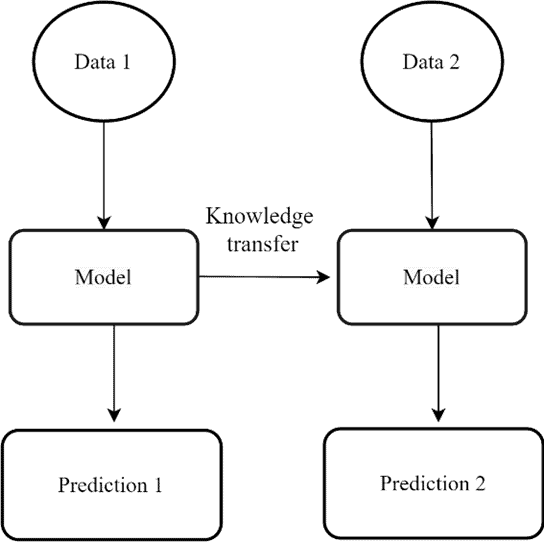
การถ่ายทอดการเรียนรู้ นิยมนำไปประยุกต์ใช้กับงานทางด้าน คอมพิวเตอร์วิทัศน์ (Computer Vision) เช่น การประมวลผลภาพ หรือวิดีโอ เพื่อให้คอมพิวเตอร์สามารถเข้าใจทัศนียภาพ หรือจำแนกวัตถุต่าง ๆ เนื่องจากแบบจำลองสำหรับงานด้านนี้มีพารามิเตอร์เป็นจำนวนมาก ซึ่งจำเป็นต้องใช้ชุดข้อมูลขนาดใหญ่ในการเรียนรู้ของแบบจำลอง โดยอาจใช้เวลาหลายวัน หรือหลายสัปดาห์ในการเรียนรู้ เพื่อให้แบบจำลองสามารถคาดการณ์สิ่งต่าง ๆ ออกมาได้ดียิ่งขึ้น ซึ่งการเรียนรู้แบบจำลองนั้นเป็นความท้าทายอย่างหนึ่งของผู้ที่สนใจในด้านนี้ จึงมีการจัดการแข่งขันที่มากมายในแต่ละปีเพื่อสร้างแบบจำลองที่ดีที่สุด ตัวอย่างเช่น การแข่งขัน ImageNet Large Scale Visual Recognition Challenge (ILSVRC) ที่จัดขึ้นเป็นประจำทุกปี เพื่อเชิญชวนให้นักวิจัยจากทุกมุมโลกมาเข้าร่วม และแข่งกันกันแสดงศักยภาพแบบจำลองของตนเอง ซึ่งทีม Visual Geometry Group (VGG) ได้รับรางวัลรองชนะเลิศอันดับ 1 ในปี ค.ศ. 2014 และมีชื่อเสียงมากในวงการนี้ แบบจำลองที่น่าสนใจของ VGG มีชื่อว่า VGG-16 ซึ่งมีการใช้ Convolution network เป็นโครงสร้างหลัก แบบจำลองดังกล่าวสามารถตรวจจับองค์ประกอบของรูปภาพได้ (ขอบ รูปแบบ สไตล์ และอื่นๆ) สถาปัตยกรรมของแบบจำลอง VGG-16 ค่อนข้างซับซ้อน มีเลเยอร์ที่หลากหลายและพารามิเตอร์จำนวนมาก ซึ่งผลลัพธ์ที่ได้แสดงให้เห็นว่า ชั้นประมวลผลที่ซ่อนอยู่ (Hidden layers) ของแบบจำลองสามารถตรวจจับองค์ประกอบในงานแต่ละงานได้ดี
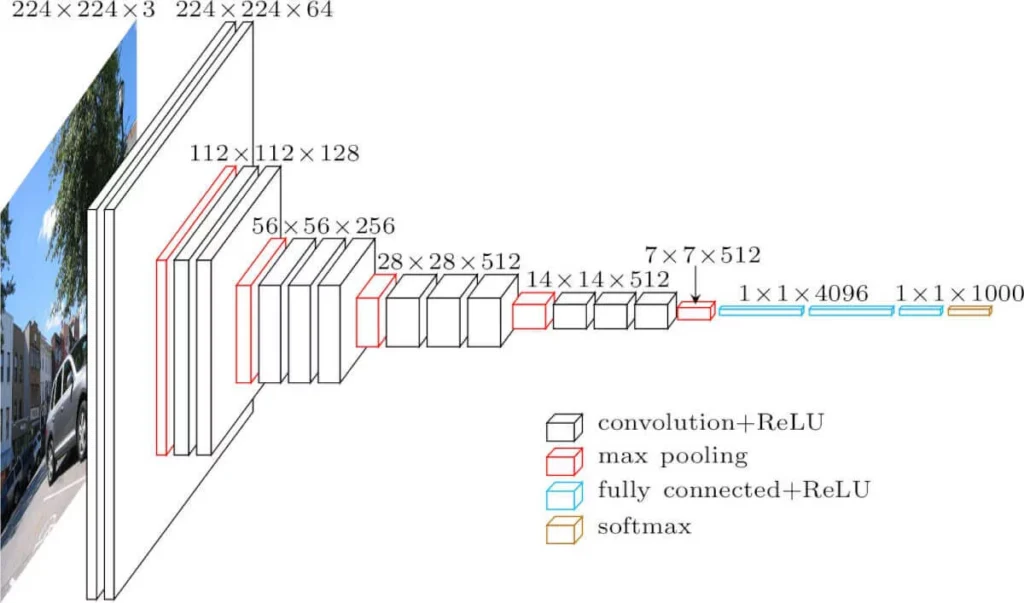
แนวคิดการถ่ายทอดการเรียนรู้ กล่าวคือ เลเยอร์ระหว่างกลางภายในแบบจำลองถือเป็นความรู้ทั่วไปที่แบบจำลองได้รับการฝึกอบรม ถ้ามองในมุมของแบบจำลอง VGG-16 ความรู้นั้นคือองค์ประกอบที่เกี่ยวกับภาพ เราสามารถใช้มันเป็นเครื่องมือสร้างแบบจำลองที่มีประสิทธิภาพ ซึ่งสามารถทำได้โดยการนำแบบจำลองที่ผ่านการเรียนรู้แล้ว มาประยุกต์ใช้กับแบบจำลองใหม่ โดยเปลี่ยนเป้าหมายหรือวัตถุประสงค์ของแบบจำลองตามที่ต้องการ ข้อมูลที่นำมาใช้สำหรับการเรียนรู้แบบจำลองใหม่จะมีลักษณะที่แตกต่างออกไปจากแบบจำลองเดิม จึงจำเป็นต้องเรียนรู้ใหม่อีกครั้ง โดยการเรียนรู้ของแบบจำลองครั้งนี้จะใช้ระยะเวลาที่สั้นขึ้น
นอกเหนือจากการเรียนรู้แบบจำลองที่เร็วขึ้นแล้ว การถ่ายทอดการเรียนรู้ยังเป็นสิ่งที่น่าสนใจเป็นพิเศษเช่นกัน การถ่ายทอดการเรียนรู้ทำให้ใช้ข้อมูลที่มีการกำกับ (Label) น้อยลง เมื่อเทียบกับชุดข้อมูลขนาดใหญ่ที่ถูกใช้ในการเรียนรู้แบบจำลองตั้งต้น ซึ่งข้อมูลที่มีการกำกับเป็นข้อมูลที่หายากและมีมูลค่าสูง ดังนั้นการถ่ายทอดการเรียนรู้เพื่อสร้างแบบจำลองที่มีคุณภาพโดยไม่ต้องใช้ข้อมูลขนาดใหญ่จึงเป็นที่นิยม
การถ่ายทอดการเรียนรู้ในงานด้านภาษา (Transfer Learning in Natural Language Processing, NLP)
ความก้าวหน้าในการเรียนรู้เชิงลึกสำหรับ NLP นั้นเติบโตน้อยกว่างานในด้าน Computer vision เนื่องจากคอมพิวเตอร์สามารถเรียนรู้ ขอบภาพ วงกลม สี่เหลี่ยม รูปร่างที่ปรากฏ ว่ามีลักษณะเป็นอย่างไร แล้วนำความรู้นี้ไปทำสิ่งต่าง ๆ แต่ในงานด้านภาษาไม่ได้ตรงไปตรงมาเหมือนงานด้านรูปภาพ ความพยายามแรกเริ่มที่ได้รับความนิยมในการถ่ายทอดการเรียนรู้ของ NLP คือการทำแบบจำลอง word embedding ตัวอย่างเช่น Word2Vec [2] และ Glove [3] ที่นิยมใช้กันอย่างแพร่หลาย
การแปลงคำให้เป็นตัวเลขหรือเวกเตอร์นี้ อาศัยบริบทแวดล้อมของคำนั้นๆ เพื่อสร้างการแทนค่าเชิงตัวเลข โดยคำที่มีความหมายใกล้เคียงกันจะมีค่าเวกเตอร์ที่ใกล้เคียงกันด้วย
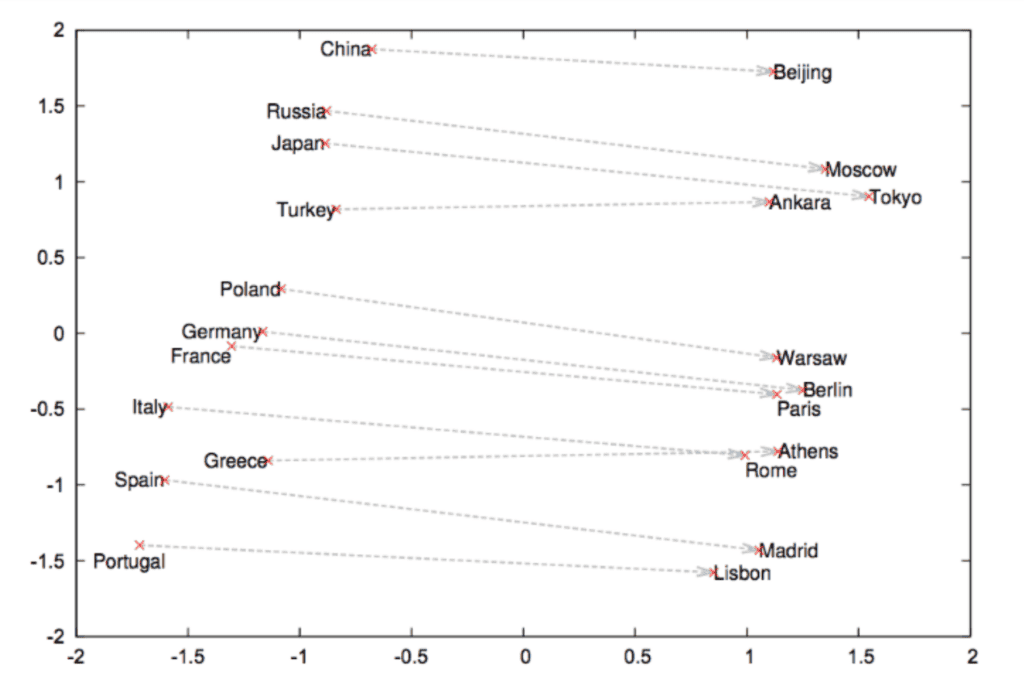
จากบทความ Word2Vec [2] แสดงให้เห็นว่าแบบจำลองสามารถเรียนรู้ความสัมพันธ์ระหว่างชื่อประเทศกับชื่อเมืองหลวงของประเทศได้อย่างแม่นยำ สิ่งนี้ทำให้ Word2Vec ได้รับการยอมรับอย่างกว้างขวางในวงการ NLP นอกจากนี้ ยังเปิดทางให้มีการพัฒนาวิธีการแทนค่า (representation) ของคำ ตัวอักษร และเอกสารที่มีประสิทธิภาพมากขึ้นต่อไป
การถ่ายทอดการเรียนรู้ใน NLP นั้นมีข้อจำกัด คือการจัดการกับภาษาที่ต่างกัน เช่น แบบจำลองที่ได้รับการเรียนรู้ด้วยภาษาอังกฤษ จะไม่สามารถที่จะนำไปใช้กับภาษาอื่น ๆ เนื่องจากรูปแบบไวยากรณ์ของแต่ละภาษามีความแตกต่างกัน
เมื่อปี 2018 Howard และ Ruder ได้นำเสนอแบบจำลอง Universal Language Model Fine-tuning (ULMFiT) [4] เพื่อเป็นแนวทางในการถ่ายทอดการเรียนรู้สำหรับ NLP แนวคิดหลักของแบบจำลองนี้มาจากแบบจำลองภาษา ซึ่งเป็นแบบจำลองที่สามารถคาดการณ์คำถัดไปโดยพิจารณาจากคำที่มีอยู่ เปรียบเสมือนการใช้โทรศัพท์มือถือรุ่นใหม่ ๆ ที่มีการคาดการณ์คำถัดไปให้ผู้ใช้งานในขณะที่ผู้ใช้งานกำลังพิมพ์ข้อความ ถ้าผลลัพธ์ที่ได้จาการคาดการณ์คำถัดไปของแบบจำลอง NLP ถูกต้อง นั่นหมายความว่า แบบจำลองได้เรียนรู้ และทำความเข้าใจเกี่ยวกับโครงสร้างภาษาเป็นอย่างดี ดังนั้นความรู้ดังกล่าวจึงเป็นจุดเริ่มต้น ในการเรียนรู้แบบจำลองงานอื่น ๆ ที่กำหนดขึ้นเอง
ULMFiT ได้ถูกพัฒนาโดยใช้โครงสร้าง ASGD Weight-Dropped LSTM (AWD-LSTM) [5] ซึ่งเป็นหนึ่งในแบบจำลองภาษาที่ได้รับความนิยม และถูกใช้อ้างอิงในเอกสารต่าง ๆ อีกมาก อีกทั้งยังเป็น LSTM ที่ดีที่สุดสำหรับการสร้างแบบจำลองภาษาในปัจจุบัน เมื่อแบบจำลองได้เรียนรู้รูปแบบภาษา มันสามารถนำไปประยุกต์ใช้กับงานอื่น ๆ ได้ แต่การนำไปใช้จริงยังคงต้องการปรับแต่งแบบจำลองเพื่อให้เหมาะสมกับงาน โดยเริ่มจากการฝึกอบรมรูปแบบภาษาสำหรับงานที่ใช้ หลังจากนั้นจึงฝึกอบรมสำหรับการทำงานจริง เช่น การฝึกอบรมให้แบบจำลองการจำแนกประเภท
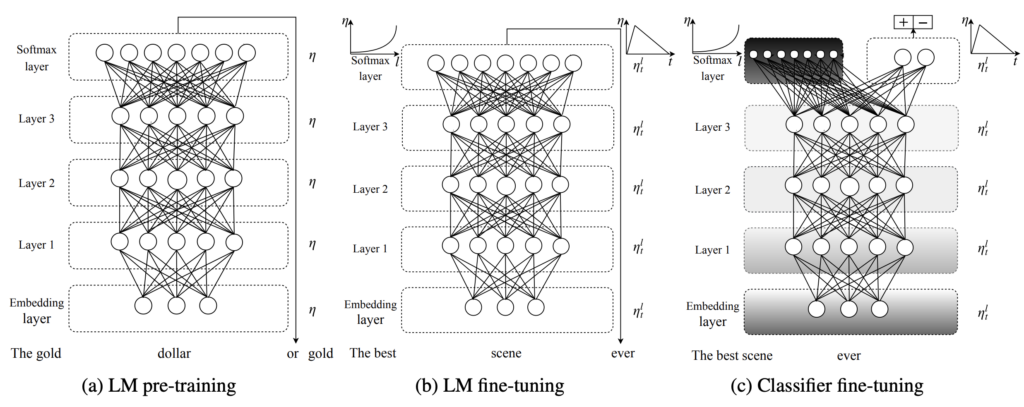
จากภาพที่ 4 การทำงานของ ULMFiT แบ่งออกเป็น 3 ขั้นตอนหลัก ได้แก่ LM pre-training คือการฝึกอบรม ULMFiT สำหรับรูปแบบภาษาทั่วไป ผลลัพธ์ที่ได้ คือแบบจำลองได้รับการเรียนรู้คุณสมบัติทั่วไปของภาษานั้น นอกจากนั้น การ pre-training จะมีประสิทธิภาพยิ่งขึ้นโดยเฉพาะข้อมูลที่มีขนาดเล็ก หรือกลาง LM fine-tuning นั้น เป็น การฝึกอบรม ULMFiT สำหรับรูปแบบภาษาเฉพาะ ผลลัพธ์ที่ได้ คือแบบจำลองที่มีรูปแบบที่เหมาะสม เพื่อใช้กับงานที่มีเป้าหมายแบบเฉพาะเจาะจง Classifier Fine-Tuning จะเป็นการฝึกอบรม ULMFiT สำหรับงานนั้น
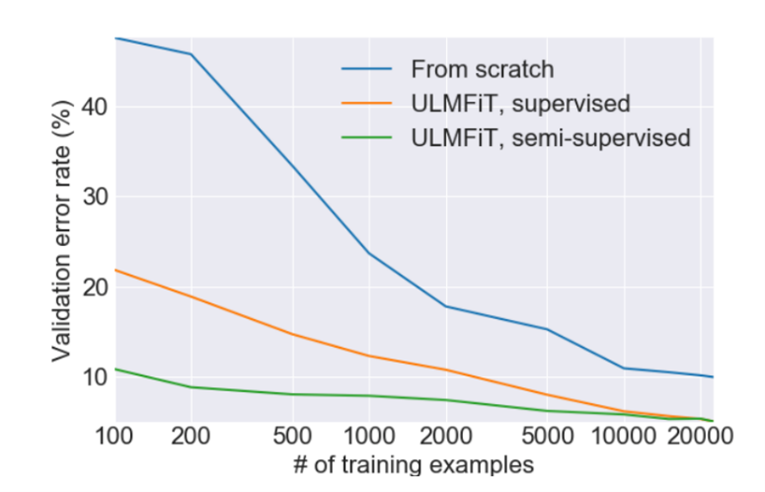
จากการทดสอบประสิทธิภาพในบทความ ULMFiT [4] พบว่าการใช้รูปแบบภาษาที่ได้รับการฝึกอบรมมาก่อน ทำให้การสร้างแบบจำลองจำแนกประเภทใช้ข้อมูลน้อยลง เช่น ผลลัพธ์จากการวิเคราะห์ IMDb ด้วยข้อมูลเพียง 100 ข้อมูล (เส้นสีเขียว) สามารถลดอัตราการผิดพลาดของแบบจำลองได้เทียบเท่ากับแบบจำลองที่ได้รับการฝึกอบรมด้วยข้อมูล 20,000 ข้อมูล (เส้นสีน้ำเงิน) ดังแสดงในรูปภาพที่ 5
และทั้งหมดนี้คือภาพรวมของการถ่ายทอดการเรียนรู้ที่สามารถนำไปใช้ในด้านการประมวลผลภาษา ความก้าวหน้าที่ได้รับจาก ULMFiT ได้ส่งเสริมการวิจัยในการถ่ายทอดการเรียนรู้สำหรับ NLP ซึ่งจะช่วยให้เราสร้างแบบจำลองการเรียนรู้ได้ดีขึ้นโดยใช้เวลาและทรัพยากรน้อยลง
การถ่ายทอดการเรียนรู้ในงาน NLP ไม่เพียงแต่เปิดประตูสู่การพัฒนาแบบจำลองภาษาที่มีประสิทธิภาพสูงขึ้น แต่ยังช่วยประหยัดเวลาและทรัพยากรอย่างมหาศาล เราเชื่อว่าเทคโนโลยีนี้จะเป็นกุญแจสำคัญในการปลดล็อกศักยภาพของ AI ในการเข้าใจและสื่อสารภาษามนุษย์ได้อย่างลึกซึ้งยิ่งขึ้น ติดตามความก้าวหน้าล่าสุดในวงการ NLP ได้ในบทความถัดไปของเรานะครับ
บทความโดย ธนกฤต คล้ายแก้ว
ตรวจทานและปรับปรุงโดย นววิทย์ พงศ์อนันต์
เอกสารอ้างอิง
[1] S. Kido, T. Miyasaka, T. Tanaka, T. Shimizu, and T. Saga, “Fall detection in toilet rooms using thermal imaging sensors,” in 2009 IEEE/SICE International Symposium on System Integration (SII), Nov. 2009, pp. 83–88, doi: 10.1109/SI.2009.5384550.
[2] T. Mikolov, I. Sutskever, K. Chen, G. Corrado, and J. Dean, “Distributed Representations of Words and Phrases and their Compositionality,” Oct. 2013, [Online]. Available: http://arxiv.org/abs/1310.4546.
[3] J. Pennington, R. Socher, and C. Manning, “Glove: Global Vectors for Word Representation,” in Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2014, pp. 1532–1543, doi: 10.3115/v1/D14-1162.
[4] J. Howard and S. Ruder, “Universal Language Model Fine-tuning for Text Classification,” in Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Jan. 2018, vol. 1, pp. 328–339, doi: 10.18653/v1/P18-1031.
[5] S. Merity, N. S. Keskar, and R. Socher, “Regularizing and Optimizing LSTM Language Models,” arXiv, Aug. 2017, [Online]. Available: http://arxiv.org/abs/1708.02182.

Data Scientist at Big Data Institute (Public Organization), BDI










