ถ้าหากว่าคุณเข้ารับการตรวจเลือด เพื่อวินิจฉัยโรค ๆ หนึ่ง แล้วผลออกมาเป็นบวก…คำถามที่เราอาจจะสงสัยคือว่า โอกาสที่เราจะเป็นโรคนั้นจริง ๆ เป็นเท่าไหร่? เราจะมาลองทำการคำนวณค่าความน่าจะเป็นนี้กัน และทำความรู้จักกับ Bayesian Trap เพื่อเสริมสร้างความเข้าใจของเราในการตีความค่าความแม่นยำ (accuracy) ให้ได้ลึกซึ้งมากยิ่งขึ้น
กรณีตัวอย่าง (Case Study) : กับดักของเบย์เซียน (Bayesian Trap)
ในกรณีที่ผลตรวจเลือดของเราเป็นบวก เพื่อที่จะหาค่าความน่าจะเป็นที่เราจะเป็นโรคนี้จริงๆ เราจำเป็นที่จะต้องรู้ความแม่นยำของผลตรวจเลือดครั้งนี้ก่อน ถ้าหากเรารู้ว่าผลเลือดนี้มีความแม่นยำเป็น 99% หลาย ๆ ท่านอาจจะคิดว่า เราจะมีโอกาสเป็นโรคนี้ถึง 99% ซึ่งในความเป็นจริงแล้วอาจจะไม่ใช่แบบนั้น
เนื่องจากว่าเราไม่ได้คำนึงความเป็นไปได้ที่เราจะเป็นโรคนี้ แต่ผลตรวจให้คำตอบที่ผิดคือ ให้ผลตรวจเป็นผลบวกแทนที่จะเป็นผลลบ ซึ่งทำให้เราจะต้องพิจารณาสัดส่วนของประชากรที่เป็นโรคและไม่เป็นโรค โดยปรากฏการณ์นี้เรียกว่า Bayesian Trap
ก่อนที่จะทำการคำนวณความน่าจะเป็นนั้น อยากให้ทุกท่านลองพิจารณาดังภาพข้างล่างเพื่อประกอบการอธิบาย

ถึงแม้ว่าผลตรวจเลือดจะมีความแม่นยำถึง 99% แต่เนื่องจากมีจำนวนคนที่ไม่เป็นโรคอยู่เป็นจำนวนมาก อาจจะทำให้เรามีโอกาสที่สูงขึ้นที่จะอยู่ในกลุ่มคนสีส้ม (คือกลุ่มคนที่ไม่เป็นโรคแต่มีผลเลือดเป็นบวก) แทนที่เป็นกลุ่มคนสีฟ้า (คือ กลุ่มคนที่เป็นโรคและมีผลเลือดเป็นบวก)
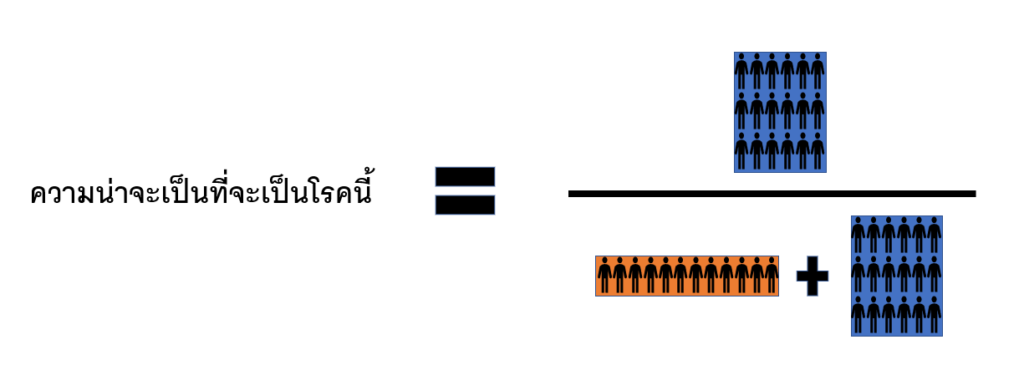
จากรูปด้านบน เมื่อเราได้รับผลตรวจเป็นบวก ค่าความน่าจะเป็นที่คุณจะเป็นโรคนี้จะสามารถคำนวณได้ด้วยอัตราส่วน คือ จำนวนกลุ่มคนที่เป็นโรคและมีผลเลือดเป็นบวก (กลุ่มคนสีฟ้า) ต่อจำนวนกลุ่มคนทั้งหมดที่มีผลเลือดเป็นบวก (กลุ่มคนสีส้มและกลุ่มคนสีฟ้า)
เพื่อความสะดวกในการคำนวณ สมมติว่าเรามีกลุ่มคนอยู่ 10,000 คน และมีคนที่เป็นโรคนี้อยู่เพียงแค่ 10 คน คนที่ได้รับผลตรวจเลือดเป็นบวก จะมีอยู่สองกลุ่มคือ
- ผู้ที่ไม่ติดโรค แต่ผลตรวจผิดเป็นบวก โดยกลุ่มนี้จะมีจำนวนประมาณ 1% จาก 9,990 คน หรือประมาณ 100 คน
- ผู้ที่ติดโรค และผลตรวจถูกให้เป็นบวก โดยกลุ่มนี้จะมีจำนวนอยู่ 99 % จาก 10 หรือประมาณ 10 คน
ดังนั้นหากเราพิจารณาจากกลุ่มคนที่มีผลตรวจเลือดเป็นบวกข้างต้น เราจะมีโอกาสที่จะเป็นโรคนี้จริง ๆ อยู่ที่ประมาณ 10/110 หรือประมาณ 9% เท่านั้น ซึ่งหมายความว่าความแม่นยำของการทดสอบที่เป็น 99% ตามที่ระบุไว้ในตอนแรกนั้นอาจจะไม่ใช่ตัวเลขที่เหมาะสมในการนำไปใช้
หลักการทางเบย์เซียน (Bayesian)
หลักการที่ได้ใช้อธิบายไว้ในข้างต้นเป็นตัวอย่างเบื้องต้นของการอนุมานแบบเบย์เซียน (Bayesian Inference) โดยหลักการแล้ว จะใช้ 2 องค์ประกอบในการพิจารณา คือ
- ความรู้เบื้องต้นเกี่ยวกับลักษณะประชากร (Prior Knowledge)
- หลักฐาน หรือความรู้ที่ได้จากการทดลอง (Evidence)
เมื่อทำการคำนวณเสร็จแล้ว เราจะได้ความรู้หลังประสบการณ์ (Posterior Knowledge) ซึ่งถือว่าเป็นคำตอบของการทำ Bayesian Inference ครับ เช่นกรณีการตรวจโรคข้างต้น เราจะได้คำตอบเป็นค่าความน่าจะเป็นของการที่ผู้ที่ได้รับผลตรวจเป็นบวกนั้นจะเป็นโรคจริงๆครับ
ในการอนุมานแบบเบย์เซี่ยน (Bayesian) เราจะใช้สมการของเบย์ (Bayes’ Equation) ในการหาข้อสรุปจากข้อมูลที่เราได้รับ โดยมีพื้นฐานมาจากสมการทางคณิตศาสตร์ดังนี้
[latexpage]
$$\mathbb{P}(A|B) = \frac{\mathbb{P}(B|A)\mathbb{P}(A)}{\mathbb{P}(B)} $$
โดยที่
$A$ คือ เหตุการณ์ (event) ที่ใช้อธิบายถึงคำตอบที่แท้จริงของเหตุการณ์ที่เราสนใจ เช่น เป็นโรค, ไม่เป็นโรค
$B$ คือ เหตุการณ์ (event) ที่ใช้อธิบายข้อมูลที่เราได้รับ เช่น ผลตรวจเลือดเป็นบวก, ลบ
นอกจากเราสามารถตีความแต่ละเทอมในสมการได้ดังต่อไปนี้ครับ:
Posterior Probability หรือ $\mathbb{P}(A|B)$ เป็นค่าความน่าจะเป็นของคำตอบที่เราสนใจหลังจากได้พิจารณาข้อมูลเพิ่มเติมแล้ว เช่น ค่าความน่าจะเป็นที่เราจะเป็นโรค หลังจากได้รับผลตรวจเลือดเป็นบวก
Likelihood หรือ $\mathbb{P}(B|A)$ เป็นค่าความน่าจะเป็นที่เราจะได้ข้อมูลนี้ ในกรณีที่ event $A$ เป็นจริง เช่น ค่าความน่าจะเป็นที่ได้ผลตรวจเลือดเป็นบวกในกรณีที่เราทราบว่าเป็นโรคนี้อยู่แล้ว
Prior Probability หรือ $\mathbb{P}(A)$ เป็นค่าความน่าจะเป็นที่ของคำตอบที่เราสนใจก่อนที่จะได้รับข้อมูลนี้ เช่น สัดส่วนของคนที่เป็นโรคนี้ในประชากรโรคทั้งหมด
Marginalization หรือ $\mathbb{P}(B)$ เป็นโอกาสที่เราจะได้ข้อมูลชุดนี้ขึ้นมา เช่น ค่าความน่าจะเป็นที่จะได้ผลตรวจเลือดเป็นบวก
สถิติแบบเบย์เซียนนั้นถูกตั้งชื่อตามนักสถิติชาวอังกฤษที่ชื่อว่า Thomas Bayes โดยแนวคิดของศาสตร์แขนงนี้ได้ถูกอ้างอิงมาจากบทความที่ชื่อว่า An Essay towards solving a Problem in the Doctrine of Chances ในปี 1963 ในบทความนี้ได้อธิบายถึงขั้นตอนการเปลี่ยนแปลงความเชื่อของเราผ่านทางข้อมูลที่เราได้รับ
แนวคิดสถิติแบบเบย์เซียนต่างจากสถิติแบบความถี่ที่เราเคยเรียนมาอย่างไร
แนวคิดแบบเบย์เซียน (Bayesian) จะค่อนข้างแตกต่างจากสถิติในแบบความถี่ (frequentist) ที่เราเคยเรียนมา ตรงที่การตีความของค่าความน่าจะเป็น
โดยฝั่ง frequentist นั้นจะมองว่าความน่าจะเป็นขึ้นอยู่กับความถี่ของการเกิดเหตุการณ์ต่าง ๆ แต่ฝั่งของ Bayesian นั้นมองว่าความน่าจะเป็นคือความของเราเกี่ยวกับเหตุการณ์ที่เราสนใจและความรู้ของเรานั้นสามารถเปลี่ยนแปลงได้ทุกครั้งที่เราได้หลักฐานเพิ่มเติมผ่านการอนุมานแบบเบย์เซียน (Bayesian Inference)
โดยส่วนใหญ่แล้วสถิติแบบ Frequentist นั้นจะเน้นการวิเคราะห์ผ่านทาง Likelihood เป็นหลัก นั่นหมายความว่าเราจะได้คำตอบที่อธิบายข้อมูลได้ดี ในทางกลับกันสถิติแบบ Bayesian นั้นจะต้องคำนึงถึงความรู้เบื้องต้น (Prior Knowledge) ด้วย
การวิเคราะห์แบบเบย์เซียนนั้นอาจฟังสมเหตุสมผลกว่าสถิติแบบความถี่ แต่ในทางปฎิบัติแล้วอาจจะมีข้อจำกัดอยู่บางประการ เช่น
- ไม่มีหลักการในการกำหนด Prior Knowledge ที่ชัดเจน ผู้ใช้จำเป็นต้องมีความเข้าใจโจทย์ที่กำลังศึกษาที่ดีเพื่อที่จะกำหนด Prior Knowledge ที่เหมาะสม
- ขั้นตอนการคำนวณค่อนข้างซับซ้อน ทำให้ใช้ทรัพยากรทางการคำนวณเป็นจำนวนมาก
ถึงแม้ว่าจะมีข้อจำกัดที่กล่าวมาข้างต้น เรายังสามารถนำสถิติแบบ Bayesian ไปใช้ได้ดีในกรณีที่อุปกรณ์การวัดของเรามีโอกาสที่จะคลาดเคลื่อนได้ เช่น การติดตามตำแหน่งยานพาหนะ, การวินิจฉัยโรค หรือการบังคับยานปลอดมนุษย์โดยสาร (Drone) เป็นต้นครับ ในส่วนถัดไปของบทความนี้เราจะอธิบายหลักการนำสถิติแบบเบย์เซียนมาใช้ติดตามตำแหน่งยานพาหนะกันครับ
การใช้ Bayesian Statistic ในการติดตามตำแหน่งยานพาหนะ

โดยปกติแล้วเราจะใช้อุปกรณ์จีพีเอส (GPS) เพื่อใช้ในการระบุตำแหน่งพาหนะ แต่ในบางครั้งตำแหน่งที่ได้รับจากอุปกรณ์นั้นอาจมีความคลาดเคลื่อนได้ มากหรือน้อยขึ้นอยู่กับประสิทธิภาพของอุปกรณ์ และลักษณะการใช้ ดังนั้นเราอาจจะต้องนำเอาข้อมูลจากสภาพแวดล้อม เช่น ตำแหน่งปัจจุบันของยานพาหนะ, ความเร็วของยานพาหนะ, สภาพถนน, ทิศทางลม และสภาพการจราจรมาเป็นเครื่องช่วยคำนวณค่าปัจจุบัน
ในทางปฏิบัติแล้ว เราจะใช้ตัวกรองคาลมาน (Kalman Filter) (ซึ่งเป็นที่รู้จักกันว่าคือ การประมาณค่าของสมการกำลังสองเชิงเส้น) เพื่อคำนวณตำแหน่งที่สมเหตุสมผลของยานพาหนะที่เราติดตาม ในบทความนี้เราจะไม่ลงรายละเอียดทางคณิตศาสตร์ของ Kalman Filter แต่จะใช้ตัวอย่างจำลองเพื่อแสดงให้เห็นถึงหลักการและเหตุผลที่จะนำไปใช้
สมมติว่าเราสนใจที่จะติดตามตำแหน่งของรถคันหนึ่งที่วิ่งจากซ้ายไปขวา (ดังรูปด้านล่าง)
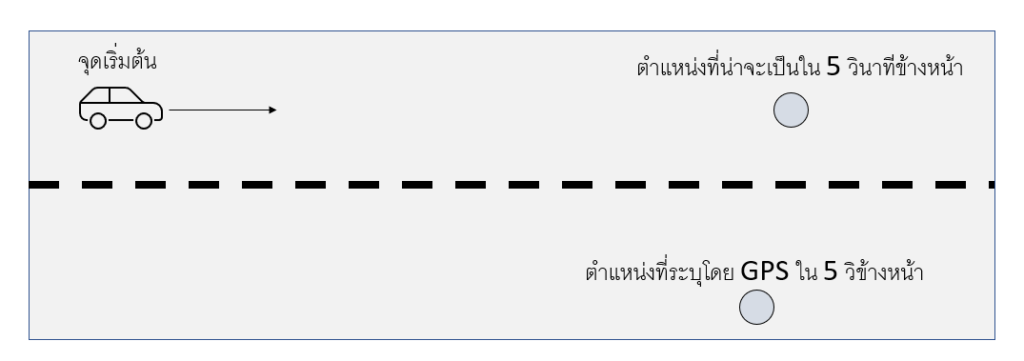
โดยปกติแล้ว ถ้าหากว่าเราถามว่ารถคันนี้ควรจะไปอยู่ตรงไหนในเวลา 5 วินาทีถัดมา คำตอบที่เป็นไปได้มากที่สุดคืออยู่ในเลนเดิมไปข้างหน้า แต่ถ้าหากว่า GPS ระบุว่ารถคันนี้อยู่ที่เลนฝั่งตรงข้ามประมาณ 20 เมตรข้างหน้า (ซึ่งสวนเลน ตามในรูปกำหนด) ในกรณีนี้ เราควรจะยึดตามค่าที่อ่านได้จาก GPS ได้มากแค่ไหน หลักการอนุมานทาง Bayesian จะช่วยให้เราแก้ไขข้อผิดผลาดจากอุปกรณ์นำทาง ในกรณีที่ค่าที่อ่านได้อยู่ในตำแหน่งที่ไม่สมเหตุสมผล
โดยสรุปแล้วบทความนี้ได้พูดถึง Bayesian Trap ซึ่งทำให้เราต้องคำนึงถึงลักษณะทางประชากร (Prior) ประกอบหลักฐานใหม่เสมอ ซึ่งแนวคิดนี้ได้เปิดช่องทางให้เราสามารถจัดการกับแหล่งข้อมูลหลายๆ แหล่งได้ ซึ่งเราได้ทำการยกตัวอย่างการติดตามตำแหน่งของยานพาหนะ ในทางปฏิบัติแล้วแนวคิดทาง Bayesian สามารถนำไปใช้ประโยชน์ได้ในหลายทาง สำหรับรายละเอียดเพิ่มเติม ผู้อ่านสามารถหาได้จากลิงค์อ้างอิง หรือบทความใน bigdata.go.th ในโอกาสถัดไปครับ
แหล่งข้อมูลอ้างอิงเพิ่มเติม
- What is Bayesian Inference?
- How Bayesian Inference Works?
- การคำนวณผลที่ได้จากนโยบายด้วย Causal Impact Analysis
- The Kalman Filter: An algorithm for making sense of fused sensor insight

Formal Senior Data Scientist at Big Data Institute (Public Organization), BDI