
เคยหรือไม่ที่คุณต้องเผชิญกับไฟล์ข้อมูลขนาดใหญ่จนโปรแกรมค้าง หรือหน่วยความจำ (RAM) ของเครื่องคอมพิวเตอร์ทำงานเกินขีดจำกัดจนไม่สามารถเปิดไฟล์เพื่ออ่านหรือประมวลผลได้ ปัญหานี้มักเกิดขึ้นบ่อยครั้งเมื่อต้องจัดการกับข้อมูลที่มีปริมาณมหาศาล โดยเฉพาะข้อมูลที่มีโครงสร้างซับซ้อน เช่น ไฟล์ CSV ขนาดใหญ่ ไฟล์บันทึก (Log files) ที่มีข้อมูลจำนวนมาก หรือแม้แต่ข้อมูลจากแหล่งข้อมูล Streaming ที่ไหลเข้ามาอย่างต่อเนื่อง การพยายามโหลดข้อมูลทั้งหมดเข้าสู่หน่วยความจำพร้อมกัน ไม่เพียงแต่จะทำให้เกิดปัญหาด้านทรัพยากรเท่านั้น แต่ยังส่งผลกระทบต่อประสิทธิภาพการทำงานของโปรแกรมโดยรวมอีกด้วย แล้วเราจะสามารถจัดการและประมวลผลข้อมูลขนาดใหญ่เหล่านี้ได้อย่างไรกัน
วันนี้ เราจะมาทำความรู้จักกับเทคนิคสำคัญที่ช่วยให้การจัดการข้อมูลขนาดใหญ่ ให้เป็นเรื่องที่ง่ายและมีประสิทธิภาพมากยิ่งขึ้น นั่นก็คือ “Chunking”
Chunking คืออะไร?
Chunking คือเทคนิคการแบ่งข้อมูลที่มีขนาดใหญ่ออกเป็นชิ้นส่วนย่อย ๆ ที่มีขนาดเล็กลง (หรือ “chunks”) เพื่อให้คอมพิวเตอร์สามารถประมวลผลข้อมูลทีละส่วน โดยไม่ต้องโหลดข้อมูลทั้งหมดลงในหน่วยความจำพร้อมกัน ซึ่งจะช่วยหลีกเลี่ยงปัญหา Memory Error ที่เกิดจากการใช้หน่วยความจำที่มากเกินไป
ทำไมต้องใช้ Chunking?
การนำเทคนิค Chunking มาใช้ มีข้อดีสำหรับการทำงานกับ Big Data โดยตรง เช่น
- ลดการใช้หน่วยความจำ: ช่วยให้สามารถประมวลผลข้อมูลที่ใหญ่กว่าขนาดหน่วยความจำ (RAM) ของเครื่องคอมพิวเตอร์ได้
- ประมวลผลข้อมูลที่ใหญ่เกินกว่าหน่วยความจำปกติได้: ทำให้ขีดจำกัดในการประมวลผลข้อมูลไม่ได้ขึ้นอยู่กับขนาด RAM ทั้งหมดอีกต่อไป
- ยืดหยุ่นในการประมวลผลทีละส่วน: สามารถนำตรรกะการประมวลผลมาใช้กับข้อมูลแต่ละส่วนย่อยได้อย่างอิสระ
Chunking กับการจัดการ DataFrame ขนาดใหญ่ใน Python
ในบริบทของการวิเคราะห์ข้อมูลด้วยภาษา Python นั้น DataFrame จากไลบราลี่ Pandas เป็นโครงสร้างข้อมูลแบบตารางสองมิติที่ใช้งานกันอย่างแพร่หลาย โดยมีแถว (Rows) แทนข้อมูลแต่ละรายการ และ คอลัมน์ (Columns) แทนคุณลักษณะหรือตัวแปรต่าง ๆ อย่างไรก็ตามไฟล์ข้อมูลที่บรรจุ DataFrame ที่มีจำนวนแถวและคอลัมน์มหาศาลนั้น การพยายามอ่านข้อมูลโดยใช้คำสั่งอ่านไฟล์มาตรฐาน เช่น pd.read_csv() อาจไม่สามารถทำได้ เนื่องจากปัญหา MemoryError ที่กล่าวไว้ข้างต้น ดังนั้นบทความนี้ จะแนะนำขั้นตอนการจัดการกับ DataFrame ขนาดใหญ่โดยใช้ Chunking ซึ่งประกอบด้วย 3 ขั้นตอนหลัก ดังนี้
ขั้นตอนที่ 1 มุ่งเน้นกับข้อมูลที่ตรงประเด็น (Focus on relevant data)
ก่อนจะเริ่มแบ่งข้อมูลเป็น chunks การลดปริมาณข้อมูลที่ต้องโหลดในแต่ละส่วนย่อยตั้งแต่ต้น จะช่วยลดภาระการประมวลผลลงได้อย่างมาก ขั้นตอนนี้จึงมีความสำคัญไม่แพ้การทำ Chunking เริ่มต้นจากการพิจารณาว่ามีคอลัมน์ใดที่ต้องการนำไปประมวลผลบ้าง และมีเงื่อนไขอื่นใดอีกหรือไม่ที่จะสามารถกรองข้อมูลเฉพาะส่วนที่เกี่ยวข้องได้ เพื่อให้ได้ข้อมูลที่ตรงประเด็นที่สุด ในกรณีที่เราไม่ใช่เจ้าของข้อมูลโดยตรง การขอพจนานุกรมข้อมูล (Data Dictionary) จากเจ้าของข้อมูลจะช่วยให้เข้าใจความหมายของแต่ละคอลัมน์และเลือกคอลัมน์ที่จำเป็นได้อย่างถูกต้อง
ตัวอย่าง: สมมติเราใช้ไฟล์ชุดข้อมูลรถยนต์มือสอง (autos.csv จาก Kaggle Used Cars Dataset) และมีโจทย์ที่ต้องการวิเคราะห์ความสัมพันธ์ระหว่างราคารถกับคุณลักษณะบางอย่างของรถยนต์มือสอง แทนที่จะโหลดคอลัมน์ทั้งหมดที่มี เราควรกำหนดตัวแปรเพื่อเลือกเฉพาะคอลัมน์ที่เกี่ยวข้องกับการวิเคราะห์ตั้งแต่ขั้นตอนการอ่านไฟล์ โดยใช้พารามิเตอร์ usecols ร่วมกับคำสั่งอ่านไฟล์ของ Pandas เช่น
pd.read_csv(‘autos.csv’, usecols= [‘price’, ‘vehicleTypes’, ‘brand’, …])
นอกจากนี้ หากมีเงื่อนไขสำหรับกรองข้อมูลเบื้องต้น เช่น ต้องการเฉพาะรถยนต์ที่เสนอขาย (Angebot) เท่านั้น ในคอลัมน์ประเภทข้อเสนอ (offerType) ก็ควรกำหนดเงื่อนไขการกรองนี้ไว้ด้วย ดังภาพตัวอย่างโค้ด
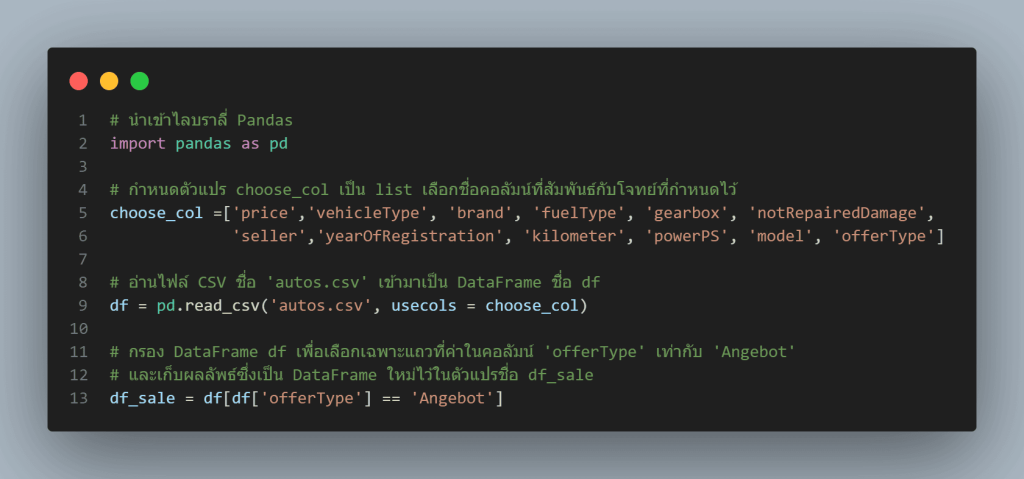
อย่างไรก็ตาม การกรองข้อมูลแถวในแนวยาว (เช่น df_sale = df[df[‘offerType’] == ‘Angebot’]) จะทำได้ก็ต่อเมื่อ DataFrame ที่เลือกคอลัมน์แล้วมีขนาดพอดีกับหน่วยความจำ หาก DataFrame นั้นมีขนาดใหญ่มากจนเกินหน่วยความจำ ก็มีความจำเป็นจะต้องทำการ Chunking เสียก่อน
ขั้นตอนที่ 2 โหลดข้อมูลทีละส่วน (Load Data in Chunks)
ขั้นตอนนี้เป็นหัวใจของการทำ Chunking สำหรับไฟล์ข้อมูลขนาดใหญ่ที่ไม่สามารถโหลดเข้าหน่วยความจำทั้งหมดได้ เราจะใช้พารามิเตอร์ chunksize ในฟังก์ชันอ่านไฟล์ของ Pandas โดยระบุขนาดของ chunk ที่ต้องการ เมื่อมีการประมวลผล Pandas จะไม่ส่งคืน DataFrame ทั้งก้อนให้ทันที แต่จะส่งคืนวัตถุที่เรียกว่า Iterator ซึ่งเราสามารถวนลูปเพื่อดึงข้อมูลมาประมวลผลได้ทีละส่วน (ทีละ chunk) ตามขนาดที่ได้กำหนดไว้
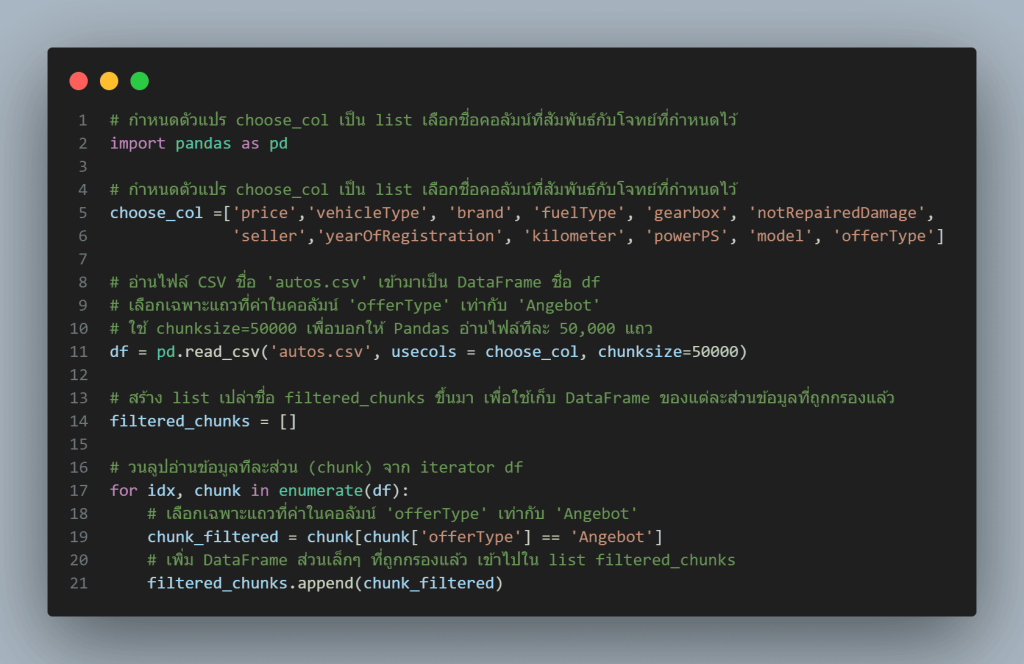
จากตัวอย่างโค้ดในภาพ 1 หากไฟล์ข้อมูล มี DataFrame ขนาดใหญ่ที่ไม่สามารถกรองข้อมูลรายแถวออกมาได้ทันที เราจำเป็นจะต้องใช้พารามิเตอร์เพื่อกำหนดขนาด chunksize ร่วมกับการอ่านไฟล์ด้วย Pandas ดังนี้
df = pd.read_csv(‘autos.csv’, chunksize = 50000)
เมื่อมีการกำหนด chunksize=50000 คำสั่งอ่านไฟล์จะส่งคืน Iterator ซึ่งเราต้องทำการวนลูป เพื่ออ่านและประมวลผลข้อมูลทีละส่วน เช่น กระบวนการกรองข้อมูลรายแถว chunk_filtered = chunk[chunk[‘offerType’] == ‘Angebot’] โดยแต่ละส่วนจะมีข้อมูลไม่เกิน 50,000 แถว และส่งคืนกลับมาในรูปแบบ DataFrame ขนาดเล็กหนึ่งก้อน การประมวลผลจะดำเนินการไปเรื่อย ๆ จนกระทั่งอ่านข้อมูลจากไฟล์ได้ครบทุกส่วน เมื่อการประมวลผลแต่ละส่วนเสร็จสิ้น เราจะได้ DataFrame ขนาดเล็กหลาย ๆ ก้อนที่ถูกกรองเป็นที่เรียบร้อย
ขั้นตอนที่ 3 บันทึกข้อมูลที่แก้ไขแล้วลงในไฟล์ใหม่ (Save modified data to new file)
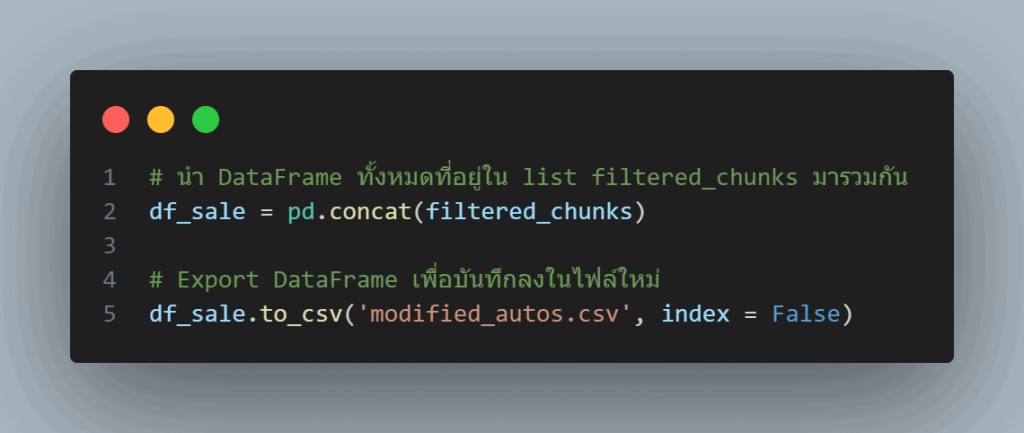
หลังจากที่เราได้ทำการโหลดและประมวลผลข้อมูลขนาดใหญ่ทีละส่วนตามขั้นตอนที่ 2 แล้ว ขั้นตอนสุดท้ายที่สำคัญคือการรวม DataFrame ขนาดเล็กเหล่านี้เข้าด้วยกันโดยการใช้คำสั่ง pd.concat() เพื่อสร้าง DataFrame ขนาดใหญ่ที่สมบูรณ์ซึ่งมีเฉพาะข้อมูลที่เราต้องการ เช่น
df_sale = pd.concat(filtered_chunks)
และบันทึกข้อมูลนี้ลงในไฟล์ใหม่ เพื่อให้สามารถนำไปใช้งานต่อในขั้นตอนการวิเคราะห์ข้อมูลขั้นสูงได้โดยไม่ต้องโหลดข้อมูลดิบขนาดใหญ่อีกต่อไป
เทคนิค Chunking ใน Python Pandas ที่นำเสนอในบทความนี้ ถือเป็นแนวทางที่มีประสิทธิภาพอย่างยิ่งในการจัดการกับ DataFrame ขนาดใหญ่เกินหน่วยความจำ ด้วยสามขั้นตอนสำคัญ เราสามารถเอาชนะข้อจำกัดนี้ ทำให้การทำงานกับชุดข้อมูลขนาดมหึมาเป็นไปได้อย่างราบรื่น เป็นระบบ และพร้อมสำหรับการวิเคราะห์ Big Data โดยนักวิทยาศาสตร์ข้อมูลและวิศวกรข้อมูลสามารถประยุกต์ใช้ได้โดยไม่ต้องกังวลกับปัญหา MemoryError อีกต่อไป
แหล่งข้อมูลอ้างอิง
- Python Simplified. (2023, May 6). Read Giant Datasets Fast – 3 Tips For Better Data Science Skills [Video]. YouTube. https://youtu.be/x2DxiL8WOmc?si=qmK_oJQo3soNms9N
- Pandas Development Team. (n.d.). Scaling to large datasets. In pandas 2.2.3 documentation. Pandas. Retrieved from [https://pandas.pydata.org/docs/user_guide/scale.html]
- TheDevastator. (2023). Used Cars [Data set]. Kaggle. https://www.kaggle.com/datasets/thedevastator/uncovering-factors-that-affect-used-car-prices?resource=download

Senior Data Management Training and Development Specialist at Big Data Institute (Public Organization), BDI






