
ข้อมูลบนอินเทอร์เน็ตนั้นมีมากมาย และนับวันก็จะมีเพิ่มมากขึ้นเรื่อย ๆ ถ้าเราสามารถที่จะดึงข้อมูลต่าง ๆ เหล่านี้ออกมาได้อย่างมีประสิทธิภาพ ก็จะช่วยให้เรานำไปวิเคราะห์หรือใช้ประโยชน์ในด้านอื่น ๆ ได้อย่างรวดเร็ว
การแพร่ระบาดของเชื้อไวรัส COVID-19 ในช่วงนี้ ทำให้หลายหน่วยงาน ทั้งภาครัฐและเอกชน ร่วมแรงร่วมใจกัน ทำทุกอย่างเท่าที่มีกำลังและความสามารถที่จะช่วยเหลือกันได้ ถ้าการระบาดของ COVID-19 เข้าสู่ระยะที่แพร่ระบาดไปทั่วประเทศ และมีผู้ป่วยติดเชื้อเป็นจำนวนมากแล้วนั้น ทรัพยากรแพทย์และความสามารถในการรองรับผู้ป่วยของโรงพยาบาลในแต่ละจังหวัดจะมีความสำคัญเป็นอย่างยิ่ง ถ้ามีผู้ป่วยจำนวนมากที่มีอาการหนัก แต่ไม่ได้เข้ารับการรักษาเพราะไม่มีสถานพยาบาลรองรับ จะมีความเสี่ยงที่อัตราการเสียชีวิตจะเพิ่มสูงขึ้นอย่างมีนัยสำคัญ ดังเช่นในประเทศอิตาลีได้
หากสถานพยาบาลหนึ่งใกล้เต็มไม่สามารถรองรับผู้ป่วยเพิ่มได้ รัฐผู้มีอำนาจจะต้องมีความพร้อมที่จะรับมือ และตัดสินใจได้ล่วงหน้าอย่างรวดเร็วว่าจะนำผู้ป่วยที่เหลือไปรักษาที่สถานพยาบาลอื่น ๆ ได้ที่ไหน อย่างไร จึงจะเหมาะสม หรือจะต้องนำงบประมาณไปลงที่พื้นที่ใด เพื่อสร้างสถานพยาบาลชั่วคราวมารองรับผู้ป่วยที่เพิ่มมากขึ้น เป็นต้น ด้วยเหตุนี้เองจึงเป็นสิ่งสำคัญที่รัฐจะต้องได้รับทราบข้อมูลข่าวสาร ติดตามสถานการณ์ทั่วทั้งประเทศได้แบบ real-time
สถาบันส่งเสริมการวิเคราะห์และบริหารข้อมูลขนาดใหญ่ภาครัฐ (GBDi) จึงได้ทำการรวบรวมข้อมูลสถานพยาบาลต่าง ๆ ทั่วประเทศ โดยหนึ่งในข้อมูลนั้นได้มาจากการดึง หรือ scrape ข้อมูลมาจาก เว็บไซต์ ของกองยุทธศาสตร์และแผนงาน สำนักงานปลัดกระทรวงสาธารณสุขเพื่อนำมาวิเคราะห์ ทำ data visualization จัดทำรายงาน นำเสนอให้ผู้มีอำนาจ และท่านนายกรัฐมนตรีนำไปใช้ประกอบการตัดสินใจ เพื่อที่ท่านจะได้สามารถออกนโยบายต่าง ๆ ได้มีประสิทธิภาพมากยิ่งขึ้น
ในซีรีส์ Data Scraping นี้ ผมจะมาเล่าถึงวิธีทำ automation ดึงข้อมูลจากเว็บไซต์ (web scraping) โดยใช้ Python ครับ ซึ่งจะประกอบไปด้วย:
- การศึกษาโครงสร้างของเว็บไซต์และ HTML code เบื้องต้นสำหรับ static website (Part 1)
- วิธีใช้ Python libraries
requestsและBeautifulSoupในการ scrape และ parse ข้อมูลจาก HTML code บนเว็บ (Part 2) - วิธีเขียน Python script เพื่อดึงข้อมูลเชิงลึก โรงพยาบาลจำนวนกว่า 2 หมื่นหน่วยงานจาก 2 หมื่นกว่าหน้าเว็บไซต์ (Part 3)
อนึ่ง ในเว็บไซต์ของกองยุทธศาสตร์และแผนงาน สำนักงานปลัดกระทรวงสาธารณสุข นั้นมีไฟล์ Excel เป็นตารางข้อมูลเบื้องต้นของสถานพยาบาลทั้งหมดให้เรา download ได้เลยโดยตรง แต่ไฟล์นี้จะไม่มีข้อมูลตำแหน่งที่ตั้ง (latitude กับ longitude) ของสถานพยาบาล ซึ่งการ scrape เว็บไซต์จะทำให้เราได้ข้อมูลเชิงลึกเพิ่มมากขึ้นครับ
บทความนี้เราจะทำการ scrape เว็บไซต์นี้โดยไม่ใช้ข้อมูลจากไฟล์ Excel นี้เลย เพื่อที่ท่านผู้อ่านจะได้เห็นภาพว่าถ้ากรณีที่ไม่มีไฟล์ Excel นี้มาให้แล้วเราจะสามารถดึงข้อมูลของสถานพยาบาลทั้งหมดมาได้อย่างไร จะได้นำไปประยุกต์ใช้ scrape เว็บไซต์อื่นๆ ต่อได้อย่างคล่องแคล่ว ว่าแล้วก็มาเริ่มกันเลยดีกว่าครับ!
ทำความรู้จักกับ Web Scraping
Web scraping เป็นการดึงข้อมูลจากอินเทอร์เน็ต การที่เราเปิดหน้าเว็บของเนื้อเพลงเพลงหนึ่งขึ้นมาเพื่อ copy-paste ลง word document ในคอมพิวเตอร์ ก็ถือว่าเป็นการทำ web scraping เช่นกัน! แต่คำว่า web scraping ส่วนใหญ่จะใช้เรียกกันในกรณีที่เป็น automation (นั่นคือ การให้โปรแกรมที่ทำงานได้ด้วยตัวเองอัตโนมัติหรือ bot ช่วย scrape ให้)
ในกรณีการ scrape ข้อมูล 2 หมื่นกว่าสถานพยาบาลจาก 2 หมื่นกว่าหน้าเว็บ (webpages) ที่เราจะทำให้ดูเป็นตัวอย่างในบทความนี้นั้น ลองนึกภาพว่าถ้าไม่ทำ automation แล้วเราต้องมานั่งเปิดทีละหน้าและทำการ copy-paste ข้อมูลเองทั้งหมดเลยนั้น จะต้องใช้เวลานั่งทำกี่วันกันนะ ?!?
คำเตือน บางเว็บไซต์เขาจะไม่ชอบให้เราทำ bot ไปเข้าเว็บเค้านะครับเพราะว่า มันอาจไปถ่วงตัว server ของเขา ทำให้เว็บไซต์เขาช้าลง ดังนั้น ก่อนจะทำ web scraping ในแต่ละเว็บไซต์ต้องศึกษาให้ดีก่อนว่า เราจะไม่ไปละเมิดกฎ (Terms of Service) ของเว็บไซต์นั้น ๆ ครับ เรื่องเกี่ยวกับกฎหมายต่าง ๆ ของ web scraping นั้นสามารถอ่านเพิ่มเติมได้ที่ Legal Perspectives on Scraping Data From The Modern Web
“ก่อนจะทำ web scraping ในแต่ละเว็บไซต์ต้องศึกษาให้ดีก่อนว่า เราจะไม่ไปละเมิดกฎ (Terms of Service) ของเว็บไซต์นั้น ๆ ครับ”
ความยากอันน่าท้าทายของ Web Scraping
เว็บไซต์ของแต่ละที่ จะมีเอกลักษณ์แตกต่างกัน รูปแบบการจัดวางข้อมูลจะไม่เหมือนกันกับเว็บอื่น ๆ ดังนั้น script ที่ใช้ scrape เว็บหนึ่งอาจจะไม่สามารถนำไป ใช้ scrape อีกเว็บหนึ่งได้โดยตรง อาจต้องมีการปรับแก้ script ให้เข้ากับรูปแบบการจัดวางข้อมูลของแต่ละเว็บนั้น ๆ โดยเฉพาะ
นอกจากนี้แล้วในเว็บไซต์เดียวกัน แต่วันเวลาผ่านไป ผู้ดูแลเว็บไซต์ก็อาจจะเปลี่ยนเป็นคนใหม่ อาจจะทำให้ style หรือ format ของหน้าเว็บเปลี่ยน ถ้าเรารัน script เดิม บนเว็บที่เปลี่ยนไป ก็จะมี error เกิดขึ้น ดังนั้นเมื่อวันเวลาผ่านไป ถ้าเว็บมีการเปลี่ยนแปลง เราก็อาจจะต้องมาปรับแก้ update script กันใหม่ครับ แต่โดยปกติ ส่วนมากการเปลี่ยนแปลงของเว็บไซต์ต่าง ๆ มักจะเป็นแบบค่อยเป็นค่อยไป script ที่ใช้ในการดึงข้อมูลจึงมักจะจำเป็นต้อง update แค่เพียงทีละเล็กละน้อยเท่านั้น
APIs: อีกหนึ่งทางเลือกแทนการทำ Web Scraping
เจ้าของเว็บไซต์ (web provider) บางเจ้ามี Application Programming Interfaces (APIs) ให้ผู้ใช้สามารถดึงข้อมูลได้ตรง ๆ โดยที่ไม่ต้อง parse HTML
รูปแบบ (format) ของข้อมูลที่ให้เราดึงทาง APIs จะนิยมใช้เป็น JSON กับ XML โครงสร้างของ APIs มักจะไม่เปลี่ยนบ่อยเท่ากับหน้าตาของ website ทำให้ไม่จำเป็นที่จะต้องปรับแก้ script กันบ่อยนัก
อย่างไรก็ดี APIs ก็อาจจะเปลี่ยนแปลงไปได้เช่นกัน ยิ่งถ้าผู้ให้บริการเว็บไซต์เค้าไม่ได้ทำ documentation มาเขียนอธิบายให้ดี การอ่านโครงสร้างของ API ด้วยตาเปล่าของเราเองนั้นอาจจะยากพอสมควร สำหรับบทความนี้ เราจะยังไม่ลงรายละเอียดการเชื่อมโยงข้อมูลทาง APIs ครับ
Scraping ข้อมูลหน่วยงานบริการสุขภาพ
เราจะเริ่มสร้าง web scraper มาดึงข้อมูลหน่วยงานบริการสุขภาพ ทุกสถานพยาบาลจากทุก webpages ที่มี URL links อยู่บนหน้าเว็บไซต์ของกองยุทธศาสตร์และแผนงาน สำนักงานปลัดกระทรวงสาธารณสุข Web scraper ที่เราสร้างนี้จะวิเคราะห์ตัดคำจาก HTML codes เพื่อที่จะดึงเอา ข้อมูลที่เราอยากได้จากบนหน้าเว็บออกมาครับ
ขั้นตอนแรกสุดคือการเปิดหน้าเว็บตัวอย่างที่เราต้องการ scrape ขึ้นมาบน web browser เพื่อดูว่ามีข้อมูลที่เราต้องการอยู่ที่ตรงส่วนไหนบ้าง
ทำความคุ้นเคยกับหน้าเว็บไซต์
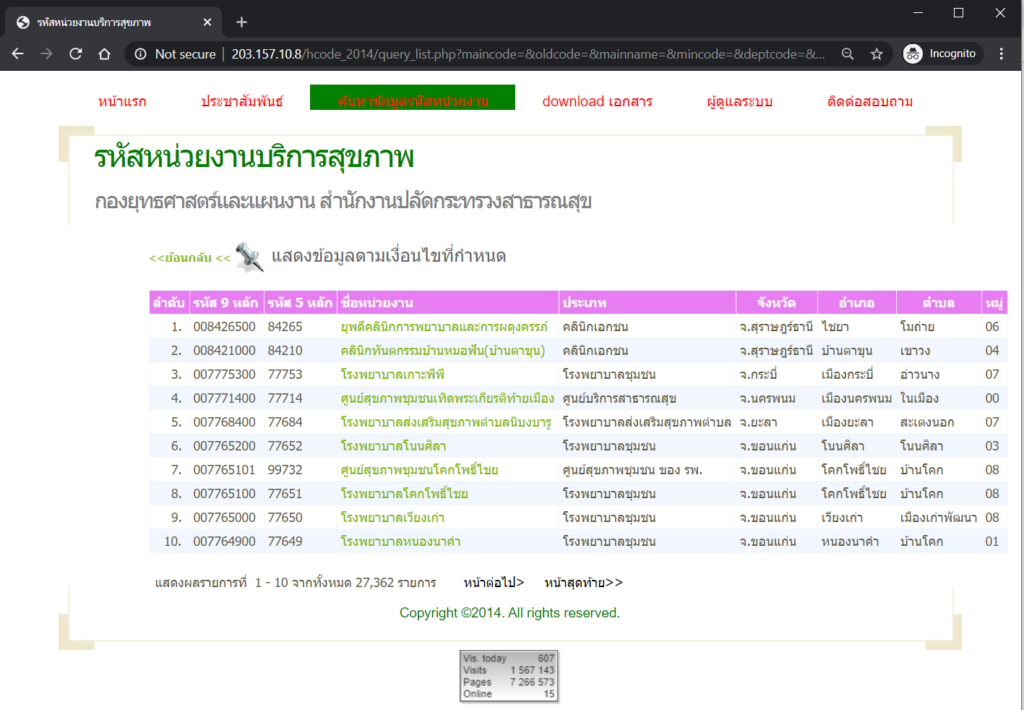
ในหน้าเว็บแรกสุด (ตามรูปข้างล่าง) นี้จะมีชื่อสถานพยาบาลอยู่ 10 แห่ง โดยที่ชื่อของแต่ละแห่ง (text สีเขียวอ่อน) นั้นจะลิงค์ไปอีกหน้าเว็บหนึ่งซึ่งมีข้อมูลรายละเอียดของสถานพยาบาลนั้น ๆ อยู่
ถ้าลองคลิกสักลิงค์หนึ่ง เช่น เข้าไปที่ โรงพยาบาลเกาะพีพี เราจะเจอกับหน้าเว็บที่มีข้อมูลของโรงพยาบาลนี้อยู่ (รูปที่ 2) มีที่อยู่ เบอร์โทรศัพท์ จำนวนเตียง พิกัดทางภูมิศาสตร์ เป็นต้น. ถ้าลองคลิกเข้าไปที่สถานพยาบาลอื่น ๆ ก็จะพบหน้าเว็บที่มีหน้าตาคล้าย ๆ กันกับของโรงพยาบาลเกาะพีพี
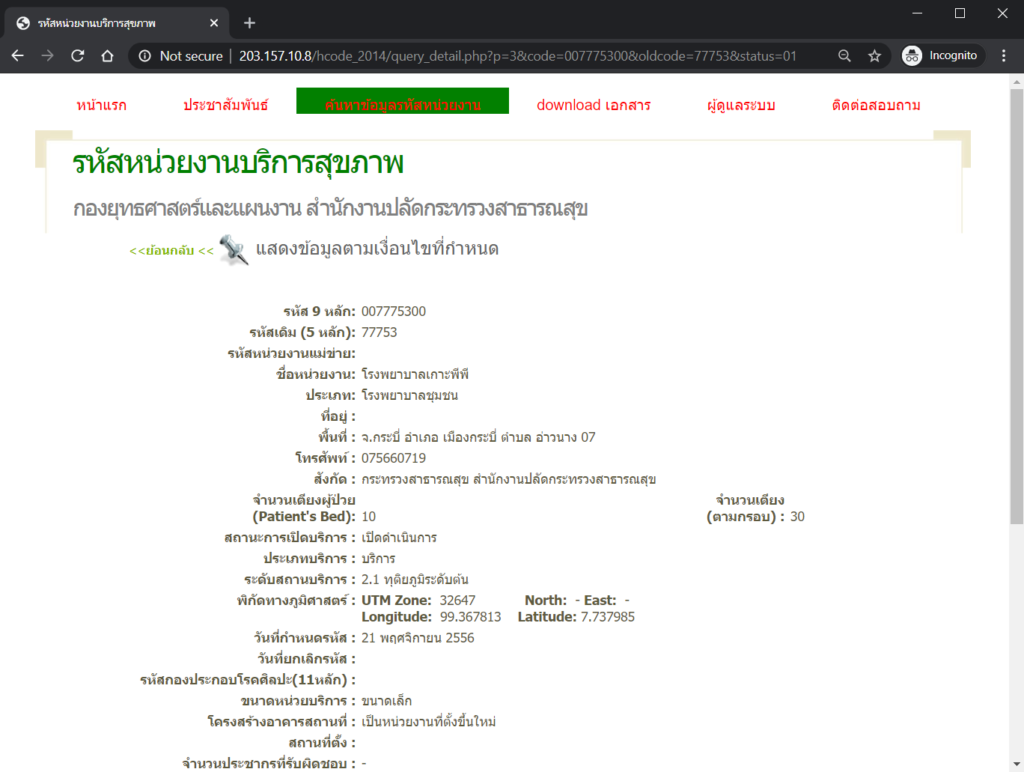
รูปที่ 2 หน้าข้อมูลโรงพยาบาลเกาะพีพี โดย URL จะมีรูปแบบที่คล้ายกับหน้าของสถานพยาบาลอื่น ๆ. โดยจะแตกต่างกันเพียงแค่ตัวเลข code และ oldcode เท่านั้น
อ่านดูที่ URLs
ทำความเข้าใจว่า URL ของแต่ละหน้าของแต่ละสถานพยาบาลมีความเหมือน หรือแตกต่างกันอย่างไรบ้าง. เช่น ถ้าเราดูที่ URL ของ โรงพยาบาลเกาะพีพี ดังในรูปที่ 2 นั้น URL คือ
http://203.157.10.8/hcode_2014/query_detail.php?p=3&code=007775300&oldcode=77753&status=01
จะพบว่ามี code=007775300 ตรงกับรหัส 9 หลัก ตามตารางในรูปที่ 1 และ oldcode=77753 ตรงกับรหัส 5 หลัก ตามตารางในรูปที่ 1 เช่นกัน และถ้าลองไปที่ webpage ของสถานพยาบาลอื่น ๆ ก็จะพบว่า URL แต่ละแห่งมีรูปแบบคล้าย ๆ กัน แตกต่างกันเพียง ตัวเลข code และ oldcode เท่านั้นครับ
การที่ URLs ของ webpages ทั้งหมดที่เราต้องการ scrape มีรูปแบบคล้าย ๆ กันแบบนี้ ช่วยทำให้ชีวิตเราง่ายขึ้นมากเลยครับ เพราะเราจะสามารถสั่ง bot ให้เข้าไปที่หน้าเว็บนั้น ๆ ผ่านทาง URL ได้โดยตรง เพียงแค่เรารู้ code รหัส 9 หลัก กับ oldcode รหัส 5 หลัก ครับ ดังนั้น แผนในหัวของเรา คร่าว ๆ ตอนนี้คืออันดับแรกสุดเราจะต้องได้มาซึ่ง code และ oldcode ของสถานพยาบาลทั้งหมด โดย scrape มาจากตารางในรูปที่ 1 และตารางใน “หน้าต่อไป” ทั้งหมดครับ
การจะสั่ง bot ให้ไป “หน้าต่อไป” นั้น จะสั่งให้ bot ไป click ที่ปุ่ม “หน้าต่อไป” ใต้ตารางในรูปที่ 1 ก็ได้นะครับ แต่ยังมีอีกวิธีหนึ่งที่ง่ายกว่ามาก คือ ถ้าเราสังเกตดู pattern ของ URLs ของหน้าตารางเหล่านี้หลายๆ หน้า เราจะพบว่า URLs มีความคล้ายกันหมด แตกต่างกันแค่ตัวเลขที่ตามหลังคำว่า pageNum_rsList= เท่านั้น โดยตัวเลขจะเป็นจำนวนเต็มไล่ตั้งแต่ 0 (หน้าแรกสุด) ไปจนถึง 2736 (หน้าสุดท้าย) ครับ พอเห็น pattern แบบนี้แล้ว แผนของเราคือจะสั่ง bot ให้มาที่แต่ละหน้าเว็บโดยบอก URL ตรง ๆ ได้เลย (เขียน for loop ให้เปลี่ยนเลขไปเรื่อย ๆ จาก 0 ถึง 2736) ซึ่งง่ายกว่าการสั่ง bot ให้กดปุ่มครับ จะเห็นได้ว่า เพียงแค่เราสังเกตดู pattern ของ URLs ก่อนสักนิด ก็ช่วยให้ชีวิตเราง่ายขึ้นมากครับ
“ในการทำ web scraping นั้น จะเห็นได้ว่า เพียงแค่เราสังเกตดู pattern ของ URLs ก่อนสักนิด ก็ช่วยให้ชีวิตเราง่ายขึ้นมากครับ”
ดูโครงสร้างหน้าเว็บโดยใช้ Developer Tools
ขั้นตอนนี้คือการทำความเข้าใจว่าเค้าจัดวางข้อมูลยังไงบนหน้าเว็บ โดยเราจะดูที่ HTML code ของหน้าเว็บนั้น ๆ เลย เพื่อที่จะได้รู้ว่า ข้อมูลแต่ละชิ้นนั้นเราจะไปหยิบมันออกมาจากตรงไหน อย่างไรดี การที่เราต้องดูที่ HTML code นั้นก็เพราะว่า bot ที่เราจะเขียนขึ้นมา scrape web มันจะอ่านและ scrape ข้อมูลที่เป็น HTML code และจะเห็นไม่เหมือนกับที่เราเห็นเป็นหน้าเว็บสำเร็จรูปครับ
วิธีดูว่าเว็บไซต์นึงมีโครงสร้างอย่างไรนั้นเราสามารถใช้ Developer tools มาเปิดดูได้ครับ Web browsers ในปัจจุบันแทบทุกอันจะมี developer tools ติดมาด้วยอยู่แล้ว ในบทความนี้เราจะใช้ developer tools ของ Google Chrome ครับ ใน web browsers อื่น ๆ ก็ทำคล้ายๆ กัน
เราสามารถเปิด developer tools ใน Chrome ได้โดย click ขวา แล้วเลือก Inspect หรือจะเข้าไปที่ menu More tools → Developer tools ก็ได้เช่นกันครับ ในหน้าเว็บแรกสุด ที่เป็นตารางตามรูปที่ 1 นั้นถ้าเราเปิด Developer tools ขึ้นมาก็จะพบกับ HTML code ที่เป็นโครงสร้างของ หน้าเว็บนั้น ๆ ดังในรูปที่ 3 ข้างล่างนี้
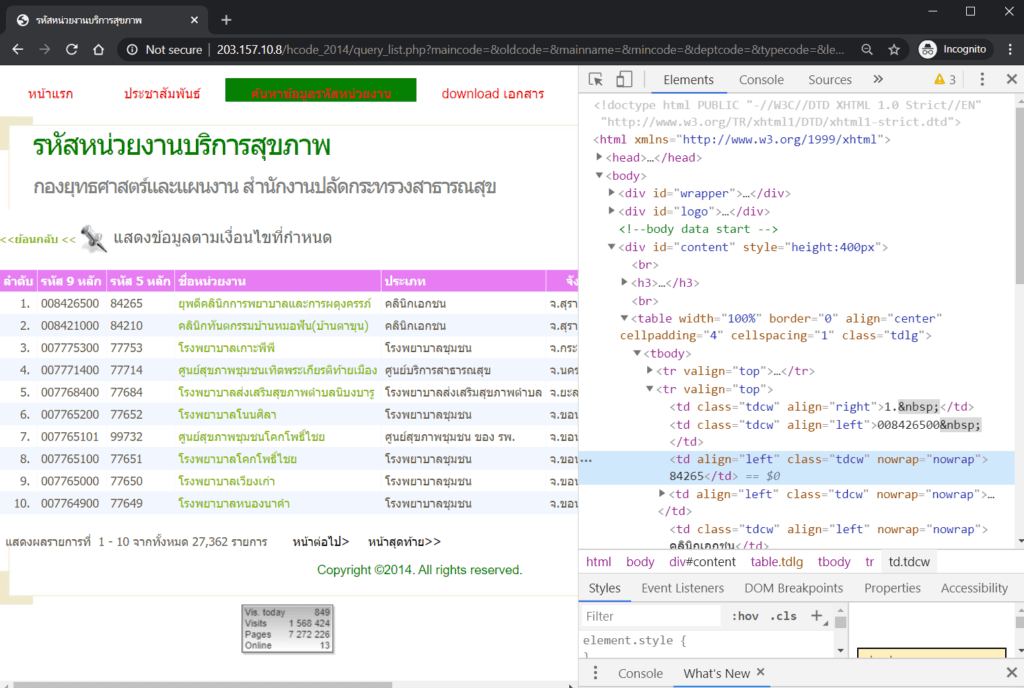
ในรูปที่ 3 นี้ ดังที่ได้เกริ่นไปในเบื้องต้นครับว่า bot จะเห็นแต่ HTML code ที่แสดงใน developer tools ทางด้านขวามือเท่านั้น โดย bot จะไม่เห็นหน้าเว็บในแบบที่เราเห็นทางด้านซ้ายมือของรูปนี้ครับ จะสังเกตเห็นว่า HTML แต่ละบรรทัดสามารถกด ขยาย (expand) ยุบซ่อน (collapse) elements ต่าง ๆ ได้ ในขณะนี้ เราต้องการได้มาซึ่ง รหัส 9 หลัก (code) กับรหัสเก่า 5 หลัก (oldcode) ของสถานพยาบาลแต่ละแห่งเพื่อเอาไปทำ URL ของหน้าเว็บข้อมูลของสถานพยาบาลแห่งนั้น ๆ ครับ เราสามารถที่จะดูได้ว่า รหัส 9 หลัก กับรหัส 5 หลัก ของแต่ละสถานพยาบาลนั้น แสดงอยู่ที่ตำแหน่งใดใน HTML code โดยให้เอา เมาส์ไปวางที่ตัวเลขนั้น ๆ บนตาราง แล้วคลิกขวา แล้วเลือก Inspect ครับ ตัว Developer tools จะ zoom ขยายและ highlight ที่ HTML code บรรทัดที่มีตัวเลขนั้นอยู่
ถ้าดูตัวอย่าง ในรูปที่ 4 นี้ผมเอาเมาส์ไปคลิกขวาที่ตัวเลข “84265” ในตาราง row แรกสุด column รหัส 5 หลัก แล้วเลือก Inspect ทำให้ Developer tools โผล่ขึ้นมาด้านขวามือแบบ zoom in และ highlight สีฟ้าที่บนบรรทัดที่ HTML code มีตัวเลข “84265” นี้วางอยู่ครับ พอเราหาตำแหน่งของตัวเลขเหล่านี้ได้แล้วก็จะสามารถสั่งให้ bot มา scrape ตัวเลขเหล่านี้ได้ถูกที่ครับ
เป็นอย่างไรกันบ้างครับ? เบื้องต้นการทำ web scraping ไม่ยากเลยใช่ไหมครับ? ในขั้นตอนต่อไป เราจะมาทำการดึงข้อมูลจริงจากเว็บไซต์ด้วย Python ใน Part 2 ซึ่งเราจะทำการเผยแพร่ในลำดับถัดไปครับ
สุดท้ายนี้ เราขอขอบคุณ สำนักงานปลัดกระทรวงสาธารณสุข สำหรับข้อมูลที่เผยแพร่สาธารณะนี้ เพื่อให้เราได้นำมาเขียนบทความที่เป็นประโยชน์ด้านการศึกษา Data Science ครับ

Senior Project Manager & Data Scientist at Big Data Institute (Public Organization), BDI









