

จากบทความที่แล้ว เรียนรู้วิธีการสร้าง Interactive Visualization ด้วย Plotly ได้มีการเล่าถึงวิธีการใช้และประโยชน์ของ Plotly ในการสร้างแผนภูมิที่สามารถโต้ตอบได้หลากหลายมิติไปเบื้องต้นแล้ว ในบทความนี้ ผู้เขียนอยากทำการเจาะลึกไปถึงการสร้างแผนภูมิสำหรับช่วยตรวจสอบลักษณะข้อมูลเบื้องต้นและการสร้างแผนภูมิที่ปรับแต่งได้อย่างซับซ้อน โดยจะทดลองประยุกต์ใช้กับข้อมูลอนุกรมเวลา (time series) ซึ่งเป็นข้อมูลที่ถูกจัดเก็บตามลำดับเวลาต่อเนื่องกันเป็นช่วง ๆ เพื่อช่วยแสดงให้เห็นการเปลี่ยนแปลงของข้อมูลที่สนใจในช่วงเวลาหนึ่งได้อย่างชัดเจน
ชุดข้อมูล
ผู้เขียนใช้ชุดข้อมูลค่าฝุ่นละออง PM2.5 เฉลี่ย 24 ชั่วโมง ในปี พ.ศ. 2563 จากกองจัดการคุณภาพและเสียง กรมควบคุมมลพิษ โดยสามารถดาวน์โหลดข้อมูลได้ ที่นี่ เลือกกดเพื่อดาวน์โหลดข้อมูลย้อนหลัง ทำการแตกไฟล์ pm25_2011_2020.zip แล้วเลือกไฟล์ PM2.5(2020).xlsx
import pandas as pd
data = pd.read_excel('./PM2.5(2020).xlsx')
data.tail() | Date | 02T | 05T | 10T | 11T | … |
| 2020-12-29 00:00:00 | 36 | 24.0 | 28.0 | 29.0 | … |
| 2020-12-30 00:00:00 | 36 | 21.0 | 30.0 | 27.0 | … |
| 2020-12-31 00:00:00 | 23 | 17.0 | 22.0 | 20.0 | … |
| NaN | NaN | NaN | NaN | NaN | … |
| หมายเหตุ | N/A : ไม่มีข้อมูล | NaN | NaN | NaN | … |
จากตัวอย่างข้อมูลพบว่า มีคอลัมน์ “Date” ที่เป็นวันที่ และคอลัมน์อื่น ๆ ที่เป็นค่าฝุ่นละออง PM2.5 เฉลี่ย 24 ชั่วโมง (ไมโครกรัมต่อลูกบาศก์เมตร) ในแต่ละสถานีวัดคุณภาพอากาศ อย่างไรก็ตามมีข้อมูลบางแถวไม่ครบถ้วน และจำนวนคอลัมน์ (สถานีวัดคุณภาพอากาศ) มีเยอะมาก ดังนั้นทางผู้เขียนจึงจำเป็นต้องทำการทำความสะอาดข้อมูลและเลือกยกตัวอย่างเฉพาะสถานีวัดคุณภาพอากาศที่ถูกเก็บโดยสถานีอุตุนิยมวิทยา เพื่อทำให้ง่ายต่อการนำไปสร้างแผนภูมิ ซึ่งมีทั้งหมด 4 ขั้นตอน ได้แก่
- ลบข้อมูล 2 แถวสุดท้ายออก เนื่องจากเป็นข้อมูลรายละเอียดของตาราง
- ทำการเลือกคอลัมน์ที่สนใจ ได้แก่ Date (วันที่บันทึก) 05T (กรมอุตุนิยมวิทยา แขวงบางนา เขตบางนา กทม.) 37T (สถานีอุตุนิยมวิทยาลำปาง ต.พระบาท อ.เมือง จ.ลำปาง) 79T (สถานีอุตุนิยมวิทยากาญจนบุรี ต.บ้านเหนือ อ.เมือง จ.กาญจนบุรี) โดยสำหรับการแปลงค่าพารามิเตอร์_สถานี xxT นั้น สามารถดูได้จากแถบ “พารามิเตอร์_สถานี” ของไฟล์ excel
- ทำการปรับประเภทข้อมูลของวันที่ให้ถูกต้อง
- เพิ่มคอลัมน์สำหรับข้อมูลเดือน
# ลบข้อมูล 2 แถวสุดท้าย
data = data[:-2]
data.head()
# ทำการเลือกคอลัมน์ของข้อมูลที่ต้องการ
data_selected = data[['Date','05T','37T','79T']]
data_selected.columns = ['วันที่','กรุงเทพ','ลำปาง','กาญจนบุรี']
# ทำการปรับประเภทข้อมูลของวันที่ให้ถูกต้อง
data_selected['วันที่'] = pd.to_datetime(data_selected['วันที่'])
# เพิ่มคอลัมน์สำหรับข้อมูลเดือน
data_selected['เดือน'] = [x.month for x in data_selected['วันที่']]
data_selected.head() | วันที่ | กรุงเทพ | ลำปาง | กาญจนบุรี | เดือน |
| 2020-12-27 | 32.0 | 31.0 | 29.0 | 12 |
| 2020-12-28 | 16.0 | 32.0 | 34.0 | 12 |
| 2020-12-29 | 24.0 | 31.0 | 26.0 | 12 |
| 2020-12-30 | 21.0 | 36.0 | 32.0 | 12 |
| 2020-12-31 | 17.0 | 24.0 | 19.0 | 12 |
ตัวอย่างข้อมูลค่าฝุ่นละออง PM2.5 เฉลี่ย 24 ชั่วโมง ในปี พ.ศ. 2563 ที่ถูกทำความสะอาดแล้ว
สุดท้ายนี้ เราจะได้ตารางข้อมูลหลังทำความสะอาดแล้ว ซึ่งประกอบไปด้วยคอลัมน์ วันที่ เดือน และค่าฝุ่นละออง PM2.5 เฉลี่ย 24 ชั่วโมง ที่ถูกเก็บข้อมูลโดยสถานีอุตุนิยมวิทยาจังหวัดกรุงเทพ ลำปาง และกาญจนบุรี พร้อมต่อการนำไปสร้างแผนภูมิต่าง ๆ ได้ทันที
แผนภูมิสำหรับทำการตรวจสอบและสำรวจข้อมูลเบื้องต้น
สิ่งที่ควรทำก่อนเป็นอันดับแรกเมื่อได้รับข้อมูลใหม่ คือ การทำการตรวจสอบและสำรวจข้อมูลเบื้องต้น (Exploratory Data Analysis หรือ EDA) เพราะจะช่วยให้เข้าใจลักษณะของข้อมูลและช่วยในการวิเคราะห์การแจกแจงความน่าเป็นของข้อมูล (probability distribution) ซึ่งทำให้เลือกโมเดลทางคณิตศาสตร์ที่เหมาะสมกับข้อมูลที่มีอยู่ได้ดีขึ้น
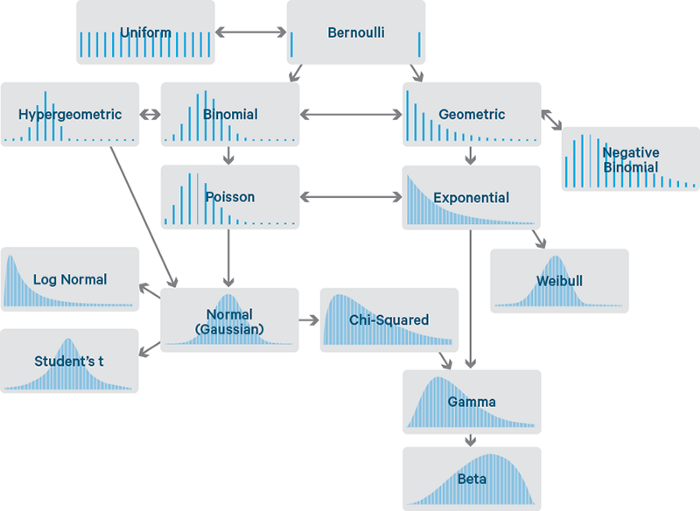
ที่มา https://www.kdnuggets.com/2020/02/probability-distributions-data-science.html
เราสามารถใช้แผนภูมิการกระจายตัวของข้อมูล (density plot) ในการช่วยแสดงการกระจายตัวของข้อมูลเป็นแบบช่วงค่าที่ต่อเนื่อง โดยที่ข้อมูลจะถูกแบ่งเป็นช่วงข้อมูลแต่ละช่วง (bin) แล้วนับจำนวนความถี่ของข้อมูล (frequency) ในแต่ละช่วง โดย Plotly มีคำสั่ง create_distplot เพื่อสร้างกราฟนี้โดยเฉพาะ ซึ่งคำสั่งดังกล่าวรับตัวแปรที่สำคัญดังนี้
hist_data= ข้อมูลที่สนใจ สำหรับแผนภูมินี้ทางผู้เขียนสนใจข้อมูลค่าฝุ่นละออง PM2.5 ของกรุงเทพ ลำปางและกาญจนบุรีgroup_labels= ชื่อที่ต้องการแสดงให้เห็นในแผนภูมิbin_size= ขนาดของช่วงข้อมูลแต่ละช่วง สำหรับแผนภูมินี้ทางผู้เขียนสนใจแบ่งข้อมูลค่าฝุ่นละออง PM2.5 ทุก ๆ 5 ไมโครกรัมต่อลูกบาศก์เมตร
import plotly.figure_factory as ff
fig = ff.create_distplot(
hist_data=[data_selected['กรุงเทพ'], data_selected['ลำปาง'], data_selected['กาญจนบุรี']],
group_labels=['กรุงเทพ','ลำปาง','กาญจนบุรี'],
bin_size=5)
# เพิ่มชื่อแผนภูมิ
fig.update_layout(title='แผนภูมิแสดงการกระจายตัวของข้อมูลค่าฝุ่นละออง PM 2.5 (ไมโครกรัมต่อลูกบาศก์เมตร)')
fig.show() 
จากรูปแสดงให้เห็นว่า จังหวัดลำปางมีการกระจายตัวของค่าฝุ่นละออง PM2.5 ที่กว้างและมีค่าสูงสุดที่ 136 ไมโครกรัมต่อลูกบาศก์เมตร ในขณะที่จังหวัดกรุงเทพมีค่าการกระจายตัวไม่เกิน 70 ไมโครกรัมต่อลูกบาศก์เมตร และทั้ง 3 จังหวัดมีค่าฝุ่นละออง PM2.5 กระจายตัวที่กระจุกตัวไปทางซ้าย (กราฟเบ้ขวา ซึ่งมีค่าเฉลี่ยมากกว่าค่าฐานนิยม) ดังนั้นในการนำข้อมูลนี้ไปวิเคราะห์ทางสถิติบางอย่าง อาจจะต้องทำการแปลงข้อมูล เช่น การทำ Log Transform เพื่อให้ข้อมูลมีการกระจายตัวกว้างขึ้นคล้ายกับการแจกแจงปกติ (normal distribution) ซึ่งเป็นส่วนช่วยในการสร้างโมเดลคณิตศาสตร์ที่แม่นยำมากขึ้น
การสร้างหลายแผนภูมิย่อยในแผนภูมิหลัก
Plotly สามารถสร้างรูปแบบการจัดวางของแผนภูมิได้เช่นกัน โดยสามารถกำหนดจำนวนแถวและคอลัมน์ว่าต้องการให้มีการจัดวางแผนภูมิในรูปแบบไหนและแต่ละแผนภูมิมีหน้าตาเป็นอย่างไร ด้วยการใช้คำสั่ง make_subplots โดยคำสั่งดังกล่าวรับตัวแปรที่สำคัญดังนี้
rows= จำนวนแถวที่ปรากฎอยู่ในแผนภูมิcols= จำนวนคอลัมน์ที่ปรากฎอยู่ในแผนภูมิsubplot_titles= ชื่อของแผนภูมิย่อยที่สร้างขึ้นมา
จากตัวอย่างด้านล่าง ทางผู้เขียนสร้างแผนภูมิย่อย 2 แผนภูมิเปรียบเทียบกัน โดยกำหนดให้แผนภูมิทางได้ซ้ายมือเป็นแผนภูมิการกระจัดของกรุงเทพ และแผนภูมิทางด้านขวามือเป็นแผนภูมิเส้นของลำปาง เพื่อแสดงถึงความยึดหยุ่นในการสร้างแผนภูมิของ Plotly
from plotly.subplots import make_subplots
import plotly.graph_objects as go
# ตั้งค่าการจัดวางของแผนภูมิ
fig = make_subplots(rows=1, cols=2,subplot_titles=("จังหวัดกรุงเทพ", "จังหวัดลำปาง"))
# เพิ่มแผนภาพการกระจาย (Scatterplot) แบบจุด (markers) สำหรับกรุงเทพ
fig.add_trace(go.Scatter(
name="กรุงเทพ", x=data_selected['วันที่'], y=data_selected['กรุงเทพ'], mode='markers'
),row=1, col=1)
# เพิ่มแผนภาพการกระจาย (Scatterplot) แบบเส้น (lines) สำหรับลำปาง
fig.add_trace(go.Scatter(
name="ลำปาง", x=data_selected['วันที่'], y=data_selected['ลำปาง'], mode='lines'
),row=1, col=2)
# เพิ่มชื่อของแผนภูมิหลัก
fig.update_layout(title_text="เปรียบเทียบค่าฝุ่นละออง PM2.5 ระหว่างจังหวัดกรุงเทพและจังหวัดลำปาง ในปี 2563")
fig.show() 
การสร้างหลายแผนภูมิอนุกรมเวลาแบบซับซ้อน
สำหรับบทความก่อนหน้านี้ผู้เขียนได้เล่าถึงการใช้ plotly.express ซึ่งเป็นเครื่องมือสำหรับการสร้างแผนภูมิที่ง่ายและรวดเร็ว อย่างไรก็ตามในหลายครั้ง เราต้องการแผนภูมิที่มีความหลากหลาย เช่น การปรับโครงสร้างของแผนภูมิโดยรวม การเพิ่มเส้นพิเศษ และการเพิ่มแผนภูมิหลากหลายประเภทในแผนภูมิหลัก เป็นต้น ทำให้ต้องสร้างแผนภูมิด้วยวิธี Graph Objects ซึ่งเป็นรูปแบบการสร้างแผนภูมิที่ยืดหยุ่นกว่า
จากตัวอย่างด้านล่าง ทางผู้เขียนต้องการสร้างแผนภูมิจากข้อมูลอนุกรมเวลาที่สามารถปรับแต่งเลือกดูเวลาช่วงเฉพาะของข้อมูล และมีการเพิ่มปุ่มที่สามารถกำหนดเส้นกำกับสำหรับแบ่งช่วงคุณภาพอากาศเพื่อใช้ในการเปรียบเทียบกับค่ามาตรฐานได้ โดยมีขั้นตอนดังนี้
- การประกาศคำสั่งเริ่มต้นของ Plotly Graph Objects
- สร้างกราฟเส้นของแต่ละจังหวัด โดยมีการกำหนดชื่อของแผนภูมิเส้น และข้อมูลที่นำมาใช้สร้างแผนภูมิในแกน x และ y
- เพิ่มเส้นกำกับสำหรับแบ่งช่วงคุณภาพอากาศ โดยกำหนดให้เป็นเส้นประ มีการตั้งค่า แกน x (จุดเริ่ม
x0และจุดสิ้นสุดx1) และแกน y (จุดเริ่มy0และจุดสิ้นสุดy1) ซึ่งค่าฝุ่นละออง PM 2.5 ได้ดังนี้ 0-25 ไมโครกรัมต่อลูกบาศก์เมตร คือ ดีมาก, 26-50 ไมโครกรัมต่อลูกบาศก์เมตร คือ ดี, 51-100 ไมโครกรัมต่อลูกบาศก์เมตร คือ ปานกลาง และ 101 ไมโครกรัมต่อลูกบาศก์เมตรขึ้นไป คือ เริ่มมีผลกระทบต่อสุขภาพ (อ้างอิงจาก กรมควบคุมมลพิษ) - จัดวางรูปแบบของแผนภูมิทั้งหมด
import plotly.graph_objects as go
# ประกาศคำสั่งเริ่มต้นของ Plotly Graph Objects
fig = go.Figure()
# เพิ่มแผนภูมิเส้นของแต่ละจังหวัดด้วย .add_trace()
fig.add_trace(go.Scatter(name="กรุงเทพ", x=data_selected['วันที่'], y=data_selected['กรุงเทพ']))
fig.add_trace(go.Scatter(name="ลำปาง", x=data_selected['วันที่'], y=data_selected['ลำปาง']))
fig.add_trace(go.Scatter(name="กาญจนบุรี", x=data_selected['วันที่'], y=data_selected['กาญจนบุรี']))
# เพิ่มเส้นกำกับสำหรับแบ่งช่วงคุณภาพอากาศ
index1 = [dict(type="line", x0=min(data_selected['วันที่']), x1=max(data_selected['วันที่']),
y0=26, y1=26, line=dict(color="Green", dash="dot"))]
index2 = [dict(type="line", x0=min(data_selected['วันที่']), x1=max(data_selected['วันที่']),
y0=51, y1=51, line=dict(color="Yellow", dash="dot"))]
index3 = [dict(type="line", x0=min(data_selected['วันที่']), x1=max(data_selected['วันที่']),
y0=101, y1=101, line=dict(color="Orange", dash="dot"))]
# จัดวางรูปแบบแผนภูมิด้วยคำสั่ง update_layout
fig.update_layout(
## เพิ่มชื่อของแผนภูมิ
title_text="แผนภูมิอนุกรมเวลาของค่าฝุ่นละออง PM 2.5 ของจังหวัดกรุงเทพ ลำปาง และกาญจนบุรี",
## เพิ่มปุ่มให้เลือกเพิ่มเส้นแบ่งคุณภาพอากาศ
updatemenus=[dict(type="buttons",
buttons=[
dict(label="ไม่กำหนดเส้นกำกับ", method="relayout", args=["shapes", []]),
dict(label="คุณภาพอากาศดี", method="relayout", args=["shapes", index1]),
dict(label="คุณภาพอากาศปานกลาง", method="relayout", args=["shapes", index2]),
dict(label="เริ่มมีผลกระทบต่อสุขภาพ", method="relayout", args=["shapes", index3])])],
## เพิ่มการเลือกดูเฉพาะช่วงเวลาที่สนใจ
xaxis=dict(rangeselector=dict(
buttons=list([
dict(count=1, label="1 เดือน", step="month", stepmode="backward"),
dict(count=6, label="6 เดือน", step="month", stepmode="backward"),
dict(label="ทั้งหมด", step="all")])),
rangeslider=dict(visible=True),type="date"))
fig.show()
จากแผนภูมิจะเห็นได้ว่า โดยรวมค่าฝุ่นละออง PM2.5 จะมีค่าที่สูงในระดับคุณภาพปานกลางหรือสูงกว่า (สูงกว่า 51 ไมโครกรัมต่อลูกบาศก์เมตร) ประมาณเดือนมกราคมถึงพฤษภาคมของปี 2563 โดยจังหวัดลำปางมีค่าฝุ่นละออง PM2.5 ที่สูงสุดในช่วงนั้น จากนั้นค่าฝุ่นละออง PM2.5 จะลดลงอย่างมากทั้ง 3 จังหวัดในช่วงที่เหลือของปี
จบไปแล้วนะครับสำหรับการสร้างแผนภูมิของ Plotly ที่ซับซ้อนมากขึ้น หวังว่าบทความนี้จะเป็นไอเดียที่ดีในการที่ผู้อ่านจะนำไปปรับใช้ไปตามความต้องการที่ดีขึ้น หากหากผู้อ่านสนใจการสร้างแผนภูมิบน Plotly ในรูปแบบอื่น ๆ ที่อยู่นอกเหนือจากบทความนี้ สามารถเข้าไปดูได้ ที่นี่
เนื้อหาโดย ธนกร ทำอิ่นแก้ว ตรวจทานและปรับปรุงโดย ดร. นนทวิทย์ ชีวเรืองโรจน์















