การวัดผลความแม่นยำ (Accuracy) ของ Model นั้น มีความสำคัญอย่างยิ่งในการวัดความน่าเชื่อถือและการเลือกใช้โมเดล ถ้าเช่นนั้นการคัดเลือกตัวชี้วัดที่เหมาะสมจึงมีความสำคัญไม่แพ้กับการสร้าง Model แล้วเราจะทำการเลือกตัวชี้วัดใดมาใช้ในการวัดความแม่นยำของ Model ของเรา ดังนั้นในบทความนี้ เราจะคัดเลือกตัวชี้วัด (Metrics) บางตัว ที่ใช้ในการวัดผลของโจทย์การวิเคราะห์ในประเภท Regression (เช่น ทำนายรายได้ ทำนายความต้องการใช้ไฟฟ้า) ทั้งตัวชี้วัดมาตรฐาน (เช่น MSE, RMSE, MAE, MAPE, sMAPE ฯลฯ) และ ตัวชี้วัดที่ปรับตามบริบทการใช้งาน เพื่ออธิบายถึงวิธีการคำนวณ ข้อดีข้อเสีย และวิธีการเลือกใช้กันนะครับ
Table of Contents
- ประเด็นควรพิจารณาก่อนเลือกใช้ตัววัดความแม่นยำ
- ตัวชี้วัดโมเดลที่น่าสนใจมีอะไรบ้าง ?
- Mean Absolute Percentage Error (MAPE)
- Symmetric Mean Absolute Percentage Error (SMAPE)
- ตัวชี้วัดตามบริบทของการใช้งาน
- บทสรุปการนำตัวชี้วัดไปใช้งาน
ประเด็นควรพิจารณาก่อนเลือกใช้ตัววัดความแม่นยำ
ตัวชี้วัดที่ใช้ในการวัดผลโมเดลนั้นมีหลายตัว และจำเป็นต้องเลือกใช้ให้เหมาะสมแก่สถานการณ์ (no one-size-fits-all) โดยในบทความนี้ เราจะพูดถึงตัวชี้วัดต่าง ๆ โดยคำนึงถึง 3 แง่มุม ได้แก่
- Interpretability (ตีความง่าย): ในหลาย ๆ ครั้ง เราจำเป็นต้องรายงานผลความแม่นยำของโมเดลแก่ผู้มีส่วนได้ส่วนเสีย (Stakeholders) ซึ่งอาจไม่ได้มีพื้นฐานความเข้าใจเฉพาะทาง ในกรณีนี้ควรเลือกตัวชี้วัดที่ทำความเข้าใจได้ง่าย เพื่อทำให้สามารถตัดสินใจได้เร็ว
- Applicability (การนำไปใช้): ผู้วิเคราะห์ควรพิจารณาว่า ผลของโมเดลนี้จะถูกนำไปใช้เพื่ออะไร (เช่น สำรองงบประมาณ จัดเตรียมสินค้าคงคลัง ตรวจสอบความผิดปกติ หรือ ทำนายมูลค่าเพื่อการลงทุน) โดยแต่ละการนำไปใช้เหล่านี้ อาจจะมีเหมาะสมกับตัวชี้วัดคนละตัวกัน ในบางกรณีผู้วิเคราะห์อาจจะต้องคิดค้นตัวชี้วัดโดยการคำนวณจากผลกระทบที่เกิดจากความผิดพลาดของโมเดล เพื่อประกอบการตัดสินใจนำโมเดลไปใช้งาน
- Optimizability (ทฤษฎีที่รองรับ): ในกรณีที่เราใช้ตัวชี้วัดนี้ในการปรับโมเดล ในกรณีนี้จำเป็นต้องคำนึงถึงทฤษฎีทางคณิตศาสตร์ที่รองรับในการปรับโมเดล ว่าเหมาะสมเพียงใด ในส่วนนี้ผู้อ่านสามารถศึกษารายละเอียดเพิ่มเติมได้ผ่านบทความภาษาอังกฤษชื่อ Forecast KPIs: RMSE, MAE, MAPE & Bias (Vandeput, 2019)
ตัวชี้วัดโมเดลที่น่าสนใจมีอะไรบ้าง ?
เพื่อความสะดวกในการอธิบาย เราจะทำการจำลองสถาณการณ์การทำนายยอดขายของสินค้าแต่ละชิ้น โดยกำหนดให้
- ค่าความต้องการจริง (Actual Demand) แทนด้วย [math]A_i[/math] ของสินค้าชิ้นนั้น,
- ค่าทำนายของความต้องการ (Forecast Demand) แทนด้วย [math]F_i[/math] ของสินค้าชิ้นนั้นที่ได้จากโมเดล
ในกรณีนี้ เราจะกำหนดค่าความคาดเคลื่อน (error) ของโมเดล โดยกำหนดให้ค่าความคลาดเคลื่อน
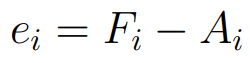
หากค่าทำนายสูงกว่าค่าจริง ค่า error จะเป็นบวก แต่ถ้าค่าจริงสูงกว่าค่าทำนาย ค่า error จะเป็นลบ
Mean Absolute Percentage Error (MAPE)
Mean Absolute Percentage Error สามารถหาได้จากค่าเฉลี่ยของค่าเปอร์เซ็นต์ความคลาดเคลื่อนมาเฉลี่ยกัน ดังสมการ
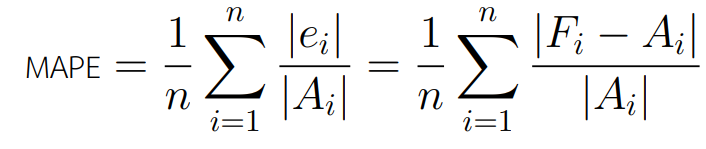
โดยผู้อ่านสามารถทำความเข้าใจวิธีการคำนวณค่า MAPE ได้ตามตารางด้านล่าง
| สัญลักษณ์ตัวแปร | [math]i=1[/math] | [math]i=2[/math] | [math]i=3[/math] | [math]i=4[/math] | [math]i=5[/math] |
|---|---|---|---|---|---|
| [math]A_i[/math] | 5 | 4 | 3 | 10 | 5 |
| [math]F_i[/math] | 4 | 4 | 2 | 9 | 7 |
| [math]|e_i|[/math] | 1 | 0 | 1 | 1 | 2 |
| [math]|e_i|/A_i[/math] | 0.20 | 0 | 0.33 | 0.1 | 0.4 |
จากตารางข้างต้น จะสามารถสรุปค่าความคาดเคลื่อนเฉลี่ย ได้เท่ากับ
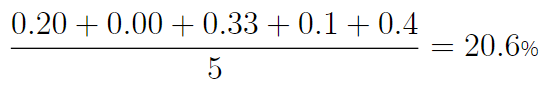
ค่า MAPE สามารถใช้ตีความได้ง่าย
ค่า Mean Absolute Percentage Error ใช้การรายงานผลเป็นเปอร์เซนต์ทำให้สามารถทำความเข้าใจถึงระดับความแม่นยำได้ โดยไม่ต้องคำนึงถึงขนาดของสิ่งที่กำลังทำนายอยู่ (scale-independent) ทำให้รายงานให้ผู้มีส่วนได้ส่วนเสียเข้าใจได้ง่าย และสามารถตัดสินใจได้เร็ว
ข้อจำกัดด้านเทคนิคของ MAPE
- ตัวหารที่ใกล้เคียง 0: ในกรณีที่ค่าจริง (Actual Demand) เป็น 0 จะไม่สามารถหาค่าได้ หรือในกรณีที่มีค่าใกล้เคียง 0 จะทำให้ค่าความคาดเคลื่อน มีค่าสูงผิดปกติ
- สูตรไม่สมมาตร: ในกรณีที่ค่าทำนายนั้น น้อยกว่าค่าจริง ค่า Absolute Percentage Error จะอยู่ที่ 0-100% แต่ในกรณีที่ค่าทำนายสูงกว่าค่าจริง ค่า Absolute Percentage Error มีโอกาสที่จะสูงกว่า 100% ดังนั้นการใช้ค่านี้ ในการเลือกโมเดล จะมีแนวโน้มที่จะได้โมเดลที่ทำนายค่าที่ต่ำกว่าปกติ
Symmetric Mean Absolute Percentage Error (SMAPE)
Symmetric Mean Absolute Percentage Error มีวิธีการคำนวณคล้ายคลึงกับ MAPE แต่เปลี่ยนตัวหารจากค่าจริง เป็นค่าเฉลี่ยของค่าจริง กับค่าทำนาย ดังสมการ
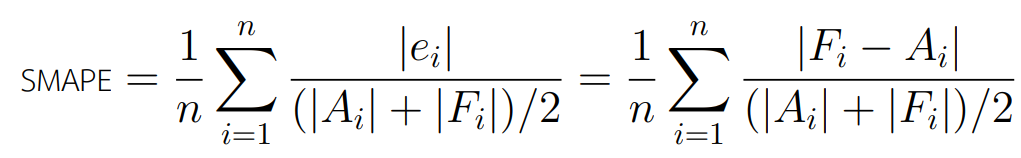
ตัววัดผล Symmetric Mean Absolute Percentage Error นั้นสามารถแก้ไขปัญหาเรื่องการหารด้วย 0 ได้ นอกจากนี้ยังสามารถจำกัดค่าความคลาดเคลื่อนของแต่ละกรณีไว้ที่ระหว่าง 0-200% แต่ตัวชี้วัดแบบสมมาตรนี้ยังมีความ Sensitive สูงต่อกรณีที่ทั้งค่าจริง และค่าทำนายมีค่าเข้าใกล้ 0 เช่นในกรณีที่ค่าจริงมีค่า [math]A_i[/math] แต่ [math]F_i[/math] กรณีนี้จะคำนวณค่า symmetric error ได้เป็น 100% ซึ่งอาจจะไม่สมเหตุสมผลได้บางกรณี
Mean Absolute Error (MAE)
เป็นอีกตัวชี้วัดที่ได้รับความนิยมสูง โดยสามารถคำนวณได้ จากการนำค่าสัมบูรณ์ของความคลาดเคลื่อน (Absolute Error) มาเฉลี่ยกัน ดังสมการ
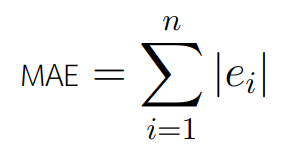
วิธีการคำนวณ MAE นั้นตรงไปตรงมา แต่การทำความเข้าใจนั้นยากกว่า Mean Absolute Percentage Error เนื่องจากจำเป็นต้องพิจารณาควบคู่กับขนาด (scale) ของสิ่งที่ทำนายด้วย สมมติว่าค่า MAE ของโมเดลหนึ่งเท่ากับ 20 เซนติเมตร ผู้ตีความจำเป็นต้องพิจารณาว่าโมเดลนี้กำลังทำนายขนาดของอะไร ถ้าโมเดลนี้ใช้ทำนายความสูงของตึกที่มีความสูงเฉลี่ย 10 เมตร ในกรณีนี้ถือว่าดี แต่ถ้าใช้ทำนายความสูงของมนุษย์ที่มึความสูงเฉลี่ย 1.5 เมตร ในกรณีนี้อาจจะถือว่าไม่ดีพอ ในกรณีนี้จำเป็นต้องหารค่า MAE ด้วยค่าเฉลี่ยของค่าจริงหรือที่เราจะเรียกว่า %MAE ของ MAE ดังสมการ
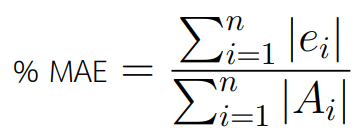
| วัตถุประสงค์ | ค่าเฉลี่ย | MAE | % MAE |
|---|---|---|---|
| ทำนายความสูงมนุษย์ | 1.5 m | 20 cm | 13.3% |
| ทำนายความสูงตึก | 10 m | 20 cm | 2% |
ในกรณีนี้ ผู้วิเคราะห์จะพบว่า เราสามารถหลีกเลี่ยงข้อจำกัดในการหา MAPE ในกรณีที่ค่าจริง (Actual Value) มีค่าใกล้ 0 ได้ โดยค่า %MAE นั้นสามารถตีความได้ว่าเป็นการคำนวณ ค่าความคาดเคลื่อนเฉลี่ยแบบถ่วงน้ำหนัก โดยที่ทำการถ่วงน้ำหนักของแต่ละค่าทำนาย ด้วยค่าจริงของค่าที่ต้องการทำนาย ในบางตำราจะถูกเรียกเป็นอีกชื่อว่า WMAPE (Weighted Mean Absolute Percentage Error) ซึ่งสามารถตีความได้ว่า เป็นการนำเอาเปอร์เซ็นต์ความคลาดเคลื่อน มาเฉลี่ยกันแบบถ่วงน้ำหนักด้วยค่าจริง
การสับสนระหว่าง MAPE และ %MAE
โดยในการใช้หลาย ๆ ครั้ง ผู้วิเคราะห์มักมีการใช้ค่าสองตัวนี้สลับกัน ดังนั้น เพื่อป้องกันความสับสนผู้เขียนจึงแนะนำให้เขียนสูตรแนบไว้ทุกครั้ง เพื่อป้องกันความสับสน
Root Mean Square Error (RMSE)
เป็นตัวชี้วัดที่ทำการทำนายที่นิยมใช้ในการวัดผล สามารถวัดได้โดยการนำค่ากำลังสองของความคลาดเคลื่อนมาเฉลี่ยกัน แล้วถอดรากที่ 2 ดังสมการ
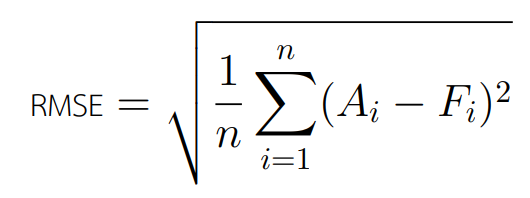
ตัวชี้วัด Root Mean Square Error (RMSE) นั้นมีความซับซ้อนมากกว่าการคำนวณ MAE (Mean Square Error) เล็กน้อย และจะให้น้ำหนักความเสียหาย (Penalize) กับกรณีที่ค่าความคลาดเคลื่อนมีความสุดโต่ง โดยตัวค่า RMSE นั้นสามารถหาเป็น % ได้เช่นเดียวกับ MAE ด้วยสูตร
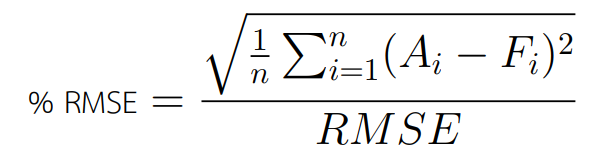
ค่า RMSE นั้นจะได้รับความนิยมสูงในการใช้เพื่อฝึกฝน และเลือกแบบจำลอง เนื่องจากตัวสูตรนั้นค่อนข้างง่ายต่อการหาค่าอนุพันธ์ (Derivative) ทำให้การปรับแบบจำลองนั้น สามารถทำได้อย่างเป็นธรรมชาติมากกว่า และเป็นค่าชี้วัดที่ใช้ในการแข่งขันสำหรับโจทย์ประเภท Regression จำนวนมากบน Platform Kaggle
ตัวชี้วัดตามบริบทของการใช้งาน
เราได้ทำการอธิบายถึงตัวชี้วัดความแม่นยำมาตรฐานไปแล้ว โดยส่วนใหญ่แล้วจะเป็นการคำนวณค่าเฉลี่ยของความคลาดเคลื่อนด้วยวิธีที่แตกต่างกันออกไป แต่ในบางกรณี ตัวชี้วัดมาตรฐานเหล่านี้ไม่สามารถนำมาปรับใช้เพื่อตัดสินใจในบริบททางธุรกิจได้ เช่น ในกรณีที่ทำนายความต้องการ (Demand Forecast)
การทำนายความต้องการสินค้ามากเกินจริง (Overestimate) อาจนำไปสู่การเพิ่มต้นทุนในการจัดเก็บสินค้าได้ แต่การทำนายสินค้าน้อยกว่าความเป็นจริง (Underestimate) ทำให้ไม่มีสินค้าขายและเสียโอกาสในการทำธุรกิจ ซึ่งการทำนายมากหรือน้อย มีน้ำหนักของความเสียหายทางธุรกิจไม่เท่ากัน ผู้ใช้อาจจำเป็นต้องใช้ความคิดสร้างสรรค์ในการคิดตัวชี้วัดให้เหมาะสม
โดยในบทความนี้จะนำเสนอเพิ่มอีก 2 วิธี ที่สามารถนำมาปรับใช้งานได้ คือ
- Error Tolerance Threshold คือ การกำหนดค่าความคลาดเคลื่อนที่ยอมรับได้ (เช่น +/- 20%) แล้วนำมาคำนวณสัดส่วนของจำนวนกรณีที่มีค่าความคลาดเคลื่อนอยู่ในเกณฑ์ที่ยอมรับได้หารด้วยจำนวนกรณีทั้งหมด และทำการรายงานเป็นค่าความแม่นยำ วิธีการนี้ถูกปรับใช้จากแนวคิด Factorize-MAPE (Lapiello, 2022)
- Potential Revenue Loss คือ เป็นวิธีการคำนวณมูลค่าความเสียหายที่เกิดขึ้นจากการทำนายที่คลาดเคลื่อน โดยมีกรณีศึกษาจากงานวิจัยของ Walmart (Ramakrishnan, et al., 2019) ที่ทำการทำนายความผิดปกติของการตั้งราคาสินค้าแบบอัตโนมัติ (Dynamic Pricing) โดยโปรแกรมจะทำการกรองสินค้าที่มีการตั้งราคาผิดปกติ และจัดลำดับความสำคัญของการตรวจสอบ โดยเรียงลำดับตามค่าความเสียหายที่อาจจะเกิดขึ้น เช่น กรณีตั้งราคาต่ำไป จะทำให้ขาดทุนเท่าไหร่ หรือการตั้งราคาที่สูงไป จะทำให้เสียโอกาสในการทำกำไรไปเท่าไหร่
บทสรุปแนวทางการคัดเลือกตัวชี้วัดไปใช้งาน
โดยสรุปแล้ว การเลือกตัวชี้วัดที่เหมาะสมควรคำนึงถึง
- ความยากง่ายในการตีความ
- การปรับใช้ให้เข้ากับบริบทของธุรกิจ
- ทฤษฎีเบื้องหลังตัวชี้วัดนั้น ๆ
ถ้าหากเราเลือกตัวชี้วัดได้อย่างเหมาะสม จะทำให้ผู้มีส่วนได้ส่วนเสีย (Stakeholders) สามารถตัดสินใจได้รวดเร็ว แม่นยำ และมั่นใจมากขึ้น นอกจากนี้ยังสามารถทำให้แบบจำลองของเรา มีโอกาสที่จะได้นำไปต่อยอดเพื่อใช้ประโยชน์ในวงกว้างได้มากขึ้นอีกด้วย
สามารถสรุปแนวทางการนำไปใช้ได้โดยสังเขปดังตารางนี้
| ชื่อตัวชี้วัด | ข้อสรุป |
|---|---|
| MAPE | ตีความง่าย เนื่องจากแสดงผลเป็นเปอร์เซนต์ถ้าค่าจริงมีค่าใกล้กับ 0 จะทำให้ค่า MAPE สูงจนดูไม่น่าเชื่อถือไม่ควรใช้กับโจทย์ที่มีความแปรปรวนสูง |
| % MAE, wMAPE | ตีความง่าย เนื่องจากแสดงผลเป็นเปอร์เซ็นต์สามารถใช้ให้เห็นภาพรวมสำหรับโจทย์ที่มีความแปรปรวนสูง |
| % RMSE | มีความอ่อนไหวต่อ Outlier เหมาะที่จะใช้เป็น Loss Function |
| Tolerance Threshold | สามารถเชื่อมโยงกับบริบททางธุรกิจได้ไม่อ่อนไหวต่อ Outlier |
| Potential Revenue Loss | สามารถเชื่อมโยงกับบริบททางธุรกิจได้แต่จำเป็นต้องมีความเข้าใจในธุรกิจ |
ซึ่งในบทความนี้จะพูดถึงเฉพาะตัวชี้วัดที่เกี่ยวข้องกับโจทย์การทำนายประเภท Regression (คำตอบเป็นตัวเลข) เท่านั้น สำหรับโจทย์ทำนายประเภท Classification (คำตอบเป็นหมวดหมู่) นั้นจะมีการวัดที่แตกต่างกันซึ่งผู้อ่านสามารถศึกษาเพิ่มเติมได้ที่ Top 3 Classification Machine Learning Metrics
เรียบเรียงโดย วีรภัทร สาธิตคณิตกุล
ตรวจทานและปรับปรุงโดย นววิทย์ พงศ์อนันต์
แหล่งอ้างอิง
- Lapiello, E., 2022. How good is your forecasting? Unpacking metrics to evaluate true business impact of your models.
- Lewinson, E., 2020. Choosing the correct error metric
- Ramakrishnan, J., Shaabani, E., Li, C. & Sustik, M. A., 2019. Anomaly Detection for an E-Commerce Pricing System.
- Vandeput, N., 2019. Forecast KPIs: RMSE, MAE, MAPE & Bias.
- ลดความเสี่ยงการให้บริการสินเชื่อด้วย machine learning
- Bayesian Trap: กับดักจากความแม่นยำ
- Logistic Regression ด้วย Microsoft Excel

Formal Senior Data Scientist at Big Data Institute (Public Organization), BDI