คงเถียงไม่ได้เลยว่าเวลานี้ ChatGPT เป็นที่พูดถึงกันอย่างมากตั้งแต่มีการเปิดตัวโดย OpenAI ให้คนเข้าไปทดลองเล่นกัน ซึ่งมีการทดลองนำไปประยุกต์ใช้ในงานด้านต่าง ๆ มากมาย ไม่ว่าจะเป็น การสรุปเนื้อหาที่สนใจ การสร้างตัวอย่างซอร์สโค้ดเพื่อตอบโจทย์งานต่าง ๆ ถ้าใครมีโอกาสได้เข้าไปลองเล่นแล้วก็จะพบว่า ChatGPT สามารถพูดคุยโต้ตอบกับเราได้อย่างเป็นธรรมชาติมากจนน่าตกใจ โดยเบื้องหลังของ ChatGPT ที่ทำให้ข้อความที่สร้างออกมานั้นดูสมเหตุสมผลและเป็นธรรมชาตินั้น ได้มีการใช้เทคนิคที่เรียกว่า Reinforcement Learning from Human Feedback (RLHF) ในกระบวนการฝึกฝนโมเดล ซึ่งบทความนี้จะพาท่านผู้อ่านไปรู้จักกับเทคนิค RLHF กันว่ามีหลักการการทำงานอย่างไร
RLHF คืออะไร
Reinforcement learning from Human Feedback หรือเรียกสั้น ๆ ว่า RLHF เป็นเทคนิคหนึ่งในการฝึกฝนโมเดล โดยมีการใส่ความคิดเห็นของมนุษย์เข้าไปเป็นส่วนหนึ่งในการฝึกฝนผ่านกระบวนการเรียนรู้แบบ Reinforcement Learning ซึ่งการฝึกฝนโมเดลรูปแบบนี้ค่อนข้างมีความซับซ้อน เนื่องจากเทคนิคนี้จะประกอบไปด้วยการฝึกฝนโมเดลย่อยหลายส่วนโดยอาจแบ่งกระบวนการฝึกฝนเป็น 3 ส่วนหลัก ดังต่อไปนี้
- การฝึกฝน Pretrained Language Models (LM) เพื่อใช้เป็นโมเดลตั้งต้นที่มีความเข้าใจโครงสร้างภาษาสำหรับสร้างชุดข้อมูลสำหรับฝึกฝน Reward Model
- การฝึกฝน Reward Model เพื่อใช้เป็นโมเดลสำหรับการให้คะแนนผลลัพธ์ที่ได้จาก Language Model
- การ Fine-tune Language Model เพื่อให้ได้โมเดลที่เข้าใจบริบทของเนื้อหาในโดเมนที่สนใจด้วย Reinforcement Learning
Pretraining Language Models
จุดเริ่มต้น RLHF จะใช้ Language Model ที่ได้มีจากฝึกฝนกับคลังข้อมูลภาษาบางอย่างไว้ก่อนหน้าแล้ว (pretrained model) ซึ่งในช่วงเริ่มต้นทาง OpenAI ได้ใช้ pretrained model ที่ชื่อว่า GPT-3 สำหรับใครที่อยากรู้รายละเอียดเพิ่มเติมเกี่ยวกับ GPT-3 สามารถเข้าไปอ่านได้ที่บทความ GPT-3 คืออะไร? ปัญญาประดิษฐ์ที่จะมาแย่งงานคนทั่วโลกในอนาคต
โดยโมเดลตั้งต้นนี้จะถูกนำมาฝึกฝนเพิ่มเติม (Fine-tune) กับข้อมูลที่เป็นข้อความ (text) ที่เราสนใจได้ เช่น OpenAI ที่มีการ Fine-tuned กับ ข้อความที่สร้างโดยมนุษย์ (human-generated text) เพิ่มเติม
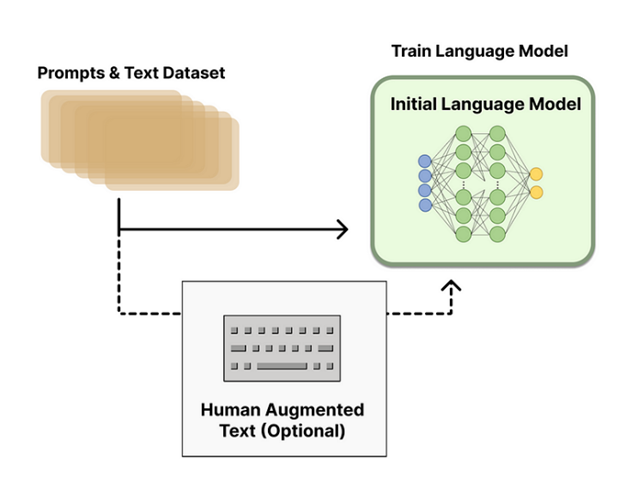
จากนั้น Language Model ที่ผ่านการ Fine-tune แล้ว จะถูกนำมาใช้ในการสร้างข้อมูลสำหรับการฝึกฝน Reward Model ซึ่งจะเป็นกระบวนการที่เริ่มมีส่วนของความคิดเห็นหรือการพิจารณาโดยมนุษย์ถูกผนวกรวมเข้าไปในระบบด้วย
Reward Model Training
Reward Model เป็นโมเดลย่อยอีกส่วนหนึ่งสำหรับการเรียนรู้แบบ RLHF โดยการฝึกฝน Reward Model นี้ มีวัตถุประสงค์เพื่อสร้างโมเดลที่สามารถจำลองการตัดสินใจการให้คะแนนของมนุษย์ เนื่องจากเราไม่สามารถให้มนุษย์มานั่งให้ Feedback ของผลลัพธ์ข้อความที่ถูกสร้างจาก Language Model ทั้งหมดได้ว่าคำตอบแบบไหนที่เป็นคำตอบที่ดี หรือแบบไหนเป็นคำตอบที่ไม่ดี โดยโมเดลนี้จะถูกนำไปใช้ในการให้คะแนนผลลัพธ์ที่ได้จาก Language Model ซึ่งจะเป็นค่า Reward ที่จะนำไปใช้ในการปรับพารามิเตอร์ของ Reinforcement Learning Model เพื่อให้ได้ Language Model ที่ได้ Reward มากขึ้น ซึ่งกลไกนี้เองจะทำให้โมเดลได้เรียนรู้ในการสร้างข้อความให้มีความถูกต้อง เหมาะสม และดูเป็นธรรมชาติตามการรับรู้ของมนุษย์
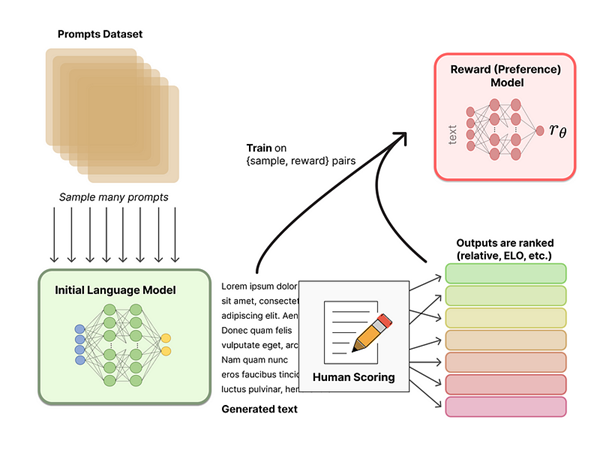
สำหรับชุดข้อมูลที่ใช้ในการฝึกฝน Reward Model นี้จะถูกสร้างมาจาก Language Model ที่ได้ทำการฝึกฝนในขั้นตอนก่อนหน้า โดยจะเริ่มจากใส่ input เป็นชุดข้อความให้กับ Language Model ตั้งต้น โดยในที่นี้ทาง OpenAI ได้ใช้ชุดข้อมูล prompts ที่รวบรวมมาจากการระบุโดยผู้ใช้ตอนเรียกใช้ API ของ GPT จากนั้น Language Model จะสร้างข้อความที่เป็นผลลัพธ์ออกมา ซึ่งข้อความที่ได้จาก Language Model นี้จะถูกใช้เป็น input สำหรับการฝึกฝน Reward Model ต่อไป
ในกระบวนการฝึกฝน Reward Model จะมีส่วนของการให้คะแนนโดยมนุษย์ (Human Annotators) เพื่อใช้ในการจัดอันดับ (ranking) ให้กับข้อความที่ถูกสร้างมาจาก Language Model ซึ่งค่า Ranking นี้จะถูกใช้เป็นผลลัพธ์สำหรับการฝึกฝน Reward Model โดยการให้คะแนนข้อความผลลัพธ์นั้นมีหลากหลายวิธี โดยหนึ่งในนั้นคือการให้ผู้ให้คะแนนเปรียบเทียบผลลัพธ์ข้อความที่ถูกสร้างจาก Language Model 2 โมเดล ว่าผลลัพธ์จากโมเดลไหนดีกว่ากัน แล้วใช้เทคนิคที่ชื่อว่า Elo System เพื่อทำการคำนวณ Ranking ของผลลัพธ์แต่ละแบบ ถึงจุดนี้สำหรับกระบวนการ RLHF เราจะได้ Language Model ตั้งต้นที่สามรถใช้ในการสร้างข้อความ และ Reward Model ที่รับข้อความใด ๆ และให้ค่าคะแนนสำหรับข้อความนั้น ๆ ขั้นตอนถัดไปจะเป็นการฝึกฝน Language Model เพิ่มเติมด้วยกระบวนการ Reinforcement Learning (RL) เพื่อปรับค่าพารามิเตอร์ต่างๆของ Language Model ให้สามารถสร้างข้อความที่ได้ Reward หรือคะแนนจาก Reward Model สูงสุดได้
Fine-tuning with Reinforcement Learning
ส่วนนี้เป็นการ Fine-tune หรือการปรับค่าพารามิเตอร์ของ Language Model ใหม่ที่ได้ทำการ Copy ค่าพารามิเตอร์ต่าง ๆ มาจาก Language Model ตั้งต้นให้เข้าใกล้จุดที่ดีทีสุดหรือได้ Reward มากที่สุด โดยใช้อัลกอริทึมที่ชื่อว่า Proximal Policy Optimization (PPO) โดยค่าพารามิเตอร์บางส่วนของ Language Model จะถูกบังคับไม่ให้เปลี่ยนแปลงค่า (Frozen) เนื่องจากการทำ Fine-tuning สำหรับพารามิเตอร์จำนวนมหาศาลนั้นค่อนข้างจะใช้ทรัพยากรค่อนข้างเยอะ จึงทำการลดให้เหลือจำนวนพารามิเตอร์ที่น้อยลงในการปรับค่า สำหรับเทคนิค PPO นั้นเป็นกระบวนการในการปรับค่าพารามิเตอร์เพื่อให้สามารถเข้าใกล้จุด Optimal ได้ดีที่สุด มีการพัฒนามานานแล้ว ถ้าใครอยากลองศึกษารายละเอียดเพิ่มก็สามารถเข้าไปอ่านหลักการได้ที่เว็บไซต์ของ Hugging Face
ก่อนอื่นลองมาทำความเข้าใจกระบวนการการทำ Fine-tune นี้ในรูปแบบของโจทย์ Reinforcement Learning (RL) กัน สำหรับในโจทย์นี้ Policy ของ Reinforcement Learning ก็คือตัว Language Model ที่มีหน้าที่รับข้อความเข้าและส่งผลลัพธ์ ออกมาเป็น Sequence ของข้อความ หรือข้อความที่น่าจะเป็นข้อความลำดับถัดไปออกมา โดยที่ Action Space ของ Policy นี้คือคำศัพท์ที่เป็นไปได้ทั้งหมดตามคลังคำศัพท์ที่มีใน Language Model ส่วน Observation Space คือ Token Sequence หรือข้อความ Input ที่เป็นไปได้ทั้งหมด ซึ่งแน่นอนว่าค่อนข้างมีขนาดใหญ่ (ตามจำนวนคำศัพท์ ยกกำลังด้วย จำนวนคำที่จะให้เป็น Input) และสุดท้าย Reward Function จะเป็นการรวมกันระหว่างผลจาก Reward Model และส่วนของการหักลบความต่างระหว่างผลลัพธ์ที่ได้จาก Language Model ตั้งต้น กับ Language Model ที่ผ่านการปรับค่าพารามิเตอร์แล้ว
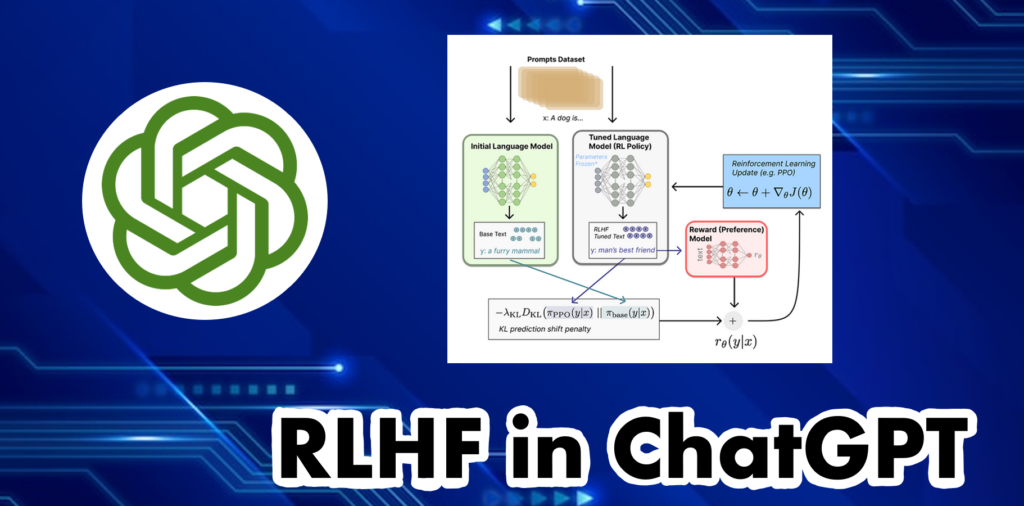
สำหรับ Reward Function คือส่วนที่ระบบจะทำการรวมโมเดลทั้งหมดที่กล่าวมาให้กลายเป็นกระบวนการ RLHF อันเดียว โดยการให้ Input เป็น ข้อความ (Prompt) x เข้าไป จากรูปตัวอย่างคือข้อความ “A dog is…” และสร้างข้อความใหม่อีก 2 ข้อความ ได้แก่ y1 และ y2 ซึ่ง y1 ถูกสร้างมาจาก initial language model และ y2 ได้มาจาก language model ที่ได้ทำการ tune ในแต่ละรอบ โดยจากตัวอย่างในที่นี้จะได้ y1 และ y2 เป็นข้อความ “a furry mammal” และ “man’s best friend” ตามลำดับ จากนั้นข้อความที่ถูกสร้างจาก Tuned Language Model (RL Policy) จะถูกส่งต่อไปยัง Reward Model ซึ่งจะได้ค่าคะแนนออกมา ข้อความที่ได้จาก Tuned Language Model จะถูกนำไปเปรียบเทียบกับข้อความที่ได้จาก Initial Language Model หรือ Language Model ตั้งต้น เพื่อคำนวณค่า penalty จากความต่างระหว่าง 2 ข้อความ โดยใช้วิธีการที่ชื่อว่า Kullback-Leibler (KL) Divergence ซึ่งเป็นเทคนิคในการคำนวณค่าความต่างระหว่างการกระจายตัวของความน่าจะเป็น (Probability Distribution) โดยค่าที่ได้จะใช้ในการปรับค่าพารามิเตอร์ (penalize) ให้กับ Tuned Language Model เพื่อไม่ให้โมเดลใหม่พยายามปรับพารามิเตอร์ให้ได้ Reward สูง แต่ผลลัพธ์ที่ได้มีความแตกต่างหรือแปลกไปจากโมเดลตั้งต้นมากเกินไป
สุดท้ายค่าที่ได้จาก reward function จะถูกนำไปคำนวณเพื่อหาการปรับค่าพารามิเตอร์ที่จะทำให้ผลลัพธ์เข้าใกล้จุดที่ได้ค่า reward สูงสุดได้ ซึ่งจะนำไปสู่การปรับ Language Model ให้สามารถสร้างผลลัพธ์ข้อความ ได้ตอบโจทย์ ถูกต้อง และมีความเป็นธรรมชาติมากที่สุด
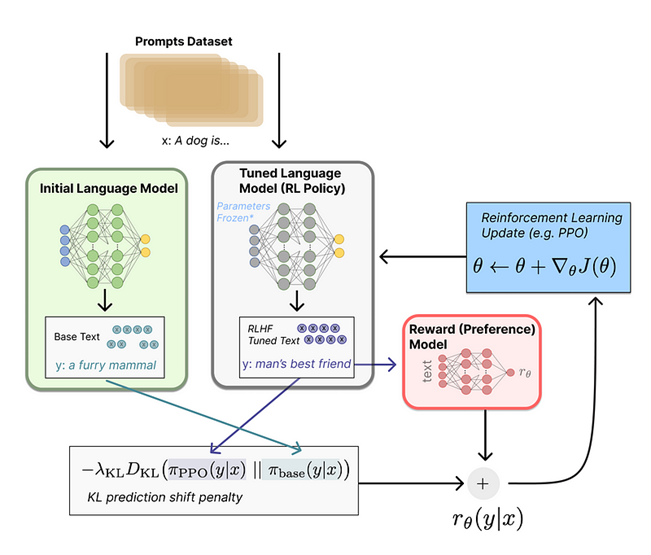
โดยสรุปจากที่กล่าวมาข้างต้น RLFH หรือ Reinforcement Learning from Human Feedback เป็นกระบวนการในการฝึกฝนโมเดลที่ถูกใช้เป็นเบื้องหลังการพัฒนา ChatGPT โดยประกอบไปด้วยองค์ประกอบโมเดลย่อยทั้งหมด 3 ส่วน ได้แก่ การฝึกฝน Pretrained Language Models (LM) สำหรับสร้างชุดข้อมูลสำหรับฝึกฝน การฝึกฝน Reward Model เพื่อใช้เป็นโมเดลสำหรับการให้คะแนนผลลัพธ์ที่ได้จาก Language Model และ การ Fine-tune Language Model ด้วย Reinforcement Learning ซึ่งจากกระบวนการ RLHF ทั้งหมดจะเห็นว่ามีส่วนที่รวมความคิดเห็นหรือการประเมินผลโดยมนุษย์เข้ามาอยู่ในขั้นตอนการฝึกฝน Reward Model เพื่อเป็นส่วนหนึ่งในการทำให้ผลลัพธ์ของโมเดลมีความสมเหตุสมผล ดูเป็นธรรมชาติ และไม่มีความแปลกจนเกินไป ด้วยเหตุผลนี้เองที่ทำให้ ChatGPT มีความแตกต่างและมีประสิทธิภาพเหนือกว่าโมเดลอื่น ๆ ที่ผ่านมา
เนื้อหาโดย กัญญาวีร์ พรสว่างดี
ตรวจทานและปรับปรุงโดย นววิทย์ พงศ์อนันต์
ที่มา:
https://huggingface.co/blog/rlhf
https://en.wikipedia.org/wiki/Reinforcement_learning_from_human_feedback
https://chatbotslife.com/reward-model-in-machine-learning-c19a790dace6
Project Manager & Data Scientist
Big Data Institute (Public Organization), BDI














