
ในปัจจุบันนี้ โลกอินเทอร์เน็ตเต็มไปด้วยตัวอักษรมากมายจากหลายภาษาทั่วโลก ผู้อ่านเคยสงสัยไหมครับ ว่าคอมพิวเตอร์จัดเก็บตัวอักษรเหล่านี้ได้อย่างไร จึงสามารถเก็บข้อมูลตัวอักษรต่าง ๆ นี้ได้อย่างเป็นระเบียบ ไม่ตีกันระหว่างตัวอักษรภาษาจีน (เช่น “你”), ตัวอักษรภาษาอังกฤษ (เช่น “k”), ตัวอักษรภาษาไทย (เช่น “ช”), หรือแม้กระทั่ง emojis (เช่น “?”) ทั้ง ๆ ที่ภายในคอมพิวเตอร์นั้น จริง ๆ แล้วรู้จักข้อมูลอยู่แค่สองแบบ คือ “1” กับ “0”?
ในบทความนี้ เราจะมาทำความรู้จักกับ Unicode ซึ่งเป็นมาตรฐานอุตสาหกรรมในการจัดระเบียบ เข้ารหัส และแสดงผลตัวอักขระที่มีอยู่ทั่วโลก เราจะมาศึกษาความแตกต่างระหว่างมาตรฐานที่ใช้แพร่หลายมากที่สุดสองมาตรฐาน คือ Unicode กับ ASCII, หลักการทำงานของ Unicode, วิธีที่คอมพิวเตอร์เก็บข้อมูลข้อความด้วย Unicode ผ่านการเข้ารหัส (encoding), และวิธี “เล่น” กับ text ในรูปแบบ Unicode ในสถานการณ์จริงต่าง ๆ ใน Python เพื่อเป็นพื้นฐานกับผู้อ่านในการวิเคราะห์ด้าน Big Data ที่เกี่ยวข้องกับข้อมูลภาษาไทยต่อไปครับ
[latexpage]
แต่ก่อนนั้นมีเพียง ASCII
ในสมัยที่คอมพิวเตอร์ถูกสร้างขึ้นมายุคแรก ๆ นั้น ได้มีการรองรับเพียงตัวอักษรภาษาอังกฤษเป็นหลัก มาตรฐาน ASCII จึงเกิดขึ้นเพื่อ “แปลง” (convert) ระหว่างตัวอักขระต่าง ๆ เป็นรหัสคอมพิวเตอร์ที่ไม่ซ้ำกันระหว่างอักขระ ในสมัยนั้นใช้เนื้อที่เพียง 7 bits หรือประมาณ 1 byte ซึ่งสามารถรับรองการเก็บอักขระต่าง ๆ กันได้ $2^7 = 128$ อักขระ ซึ่งในอดีตนั้นพอเพียงเหลือเฟือ (ตัวอักษรภาษาอังกฤษ 52 ตัวรวมตัวพิมพ์ใหญ่และตัวพิมพ์เล็ก, ตัวเลข 10 ตัว, สัญลักษณ์พิเศษและคำสั่งพิเศษต่าง ๆ อีกหลักสิบตัว)
ตัวอย่างเช่น ในรูปที่ 1 นั้น ตัวอักษร “k” สามารถถูกจัดเก็บในคอมพิวเตอร์ได้ ด้วยการเข้ารหัสเป็น “1101011” (ตัวเลขฐานสอง หรือ binary) หรือ “6B” (ตัวเลขฐานสิบหก หรือ hexadecimal) จัดเป็นอักขระตัวที่ 107 ใน 128 ตัว (นับในเลขฐานสิบ และเริ่มนับตัวแรกจากศูนย์ตาม indexing convention ของระบบคอมพิวเตอร์)
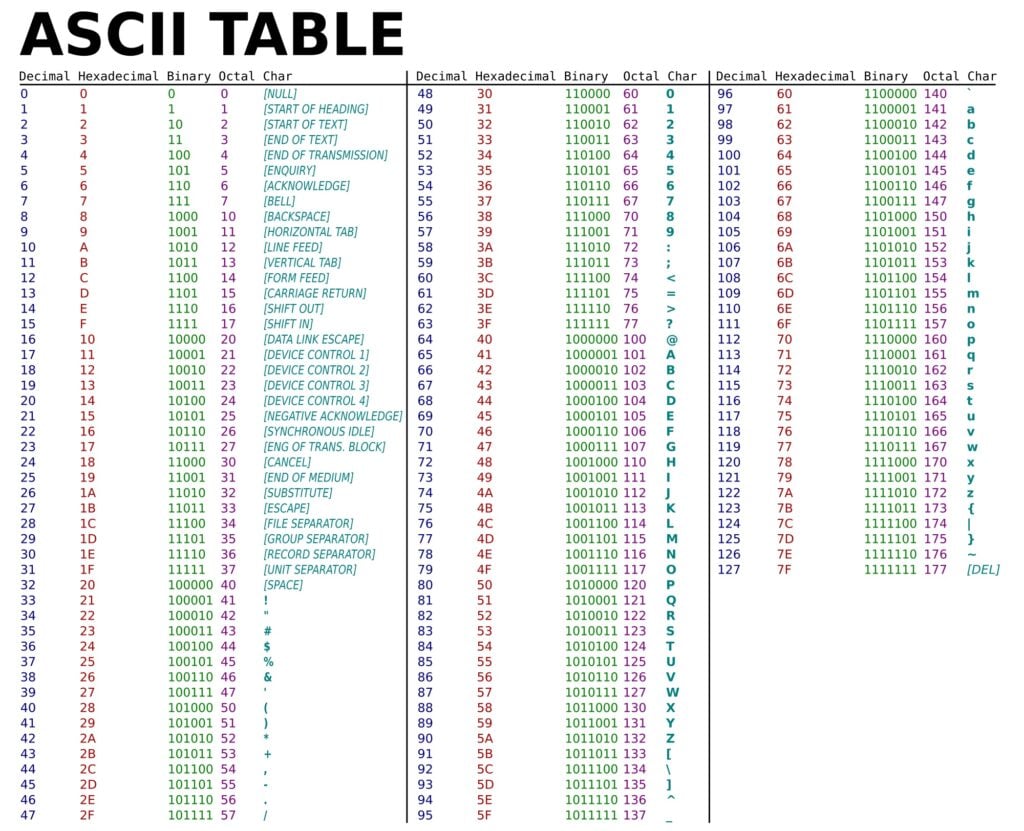
แต่เมื่อโลกของคอมพิวเตอร์ขยายตัวขึ้น และมีการเชื่อมต่อผ่านอินเทอร์เน็ตเพื่อรองรับการใช้งานจากผู้ใช้ทั่วโลก การเข้ารหัสในรูปแบบ ASCII ที่รองรับตัวอักขระต่าง ๆ ได้เพียง 128 ตัว ดูจะน้อยไปเสียแล้ว
สื่อสารกันทั่วโลกด้วย Unicode
Unicode เป็นมาตรฐานสากลเพื่อการเข้ารหัส จัดระเบียบ และแสดงผลตัวอักขระข้อความที่ใช้กันอย่างแพร่หลายมากที่สุดในปัจจุบัน รองรับภาษาทั่วโลกกว่า 154 ภาษา และสามารถแสดงผลตัวอักขระแบบต่าง ๆ ได้มากกว่า 143,000 ตัว (ข้อมูล ณ เดือนมีนาคม พ.ศ. 2563)

Unicode ทำงานอย่างไร?
ตัวอักขระในมาตรฐาน Unicode แต่ละตัวจะถูกกำหนดค่า code point ซึ่งเป็นตัวเลขอัตลักษณ์ หรือเลขที่ประจำตัว (identifier) ที่ไม่ซ้ำกันระหว่างตัวอักขระ เป็นเลขฐานสิบหก (hexadecimal) ที่มีค่าได้ตั้งแต่ 0 ถึง 0x10FFFF การออกแบบเช่นนี้ทำให้ Unicode นั้นสามารถขยายฐานการใช้งานได้อย่างยั่งยืน (scalable) มาก เพราะสามารถรองรับอักขระได้มากถึง 1.1 ล้านความเป็นไปได้ (ปัจจุบันใช้ไปแล้วประมาณ 13%)
| ตัวอักขระ | Unicode code point |
|---|---|
| 你 | U+4F60 |
| k | U+006B |
| ช | U+0E0A |
| ? | U+1F604 |
สังเกตอะไรจากตารางข้างต้นนี้ไหมครับ? ตัวอักษร “k” นั้น มี Unicode code points ที่มีค่าตัวเลขอัตลักษณ์ “6B” ซึ่งเป็นค่าเดียวกันกับที่ใช้กำหนดในมาตรฐาน ASCII ซึ่งนั่นหมายความว่า Unicode มี backward compatibility กับ ASCII นั่นเอง กล่าวคือ ตัวอักษรภาษาอังกฤษที่เดิมอาจเคยถูกเก็บไว้ด้วยการเข้ารหัสแบบ ASCII ก็สามารถแปลง (convert) ข้อความเหล่านั้นมาใช้ Unicode ได้อย่างง่ายดาย (ต้องปรบมือให้กับความละเอียดของผู้ออกแบบ Unicode ?)
มาตรฐานการแทนตัวอักขระด้วย Unicode นั้นถูกใช้อย่างแพร่หลายมาก ทำให้ใน Python 3 ได้กำหนดให้ตัวแปรข้อความ str เป็นการเก็บแบบ Unicode by default ครับ (ต่างจาก Python 2 ซึ่งใช้ ASCII by default)
Unicode ถูกจัดเก็บในคอมพิวเตอร์ได้อย่างไร?
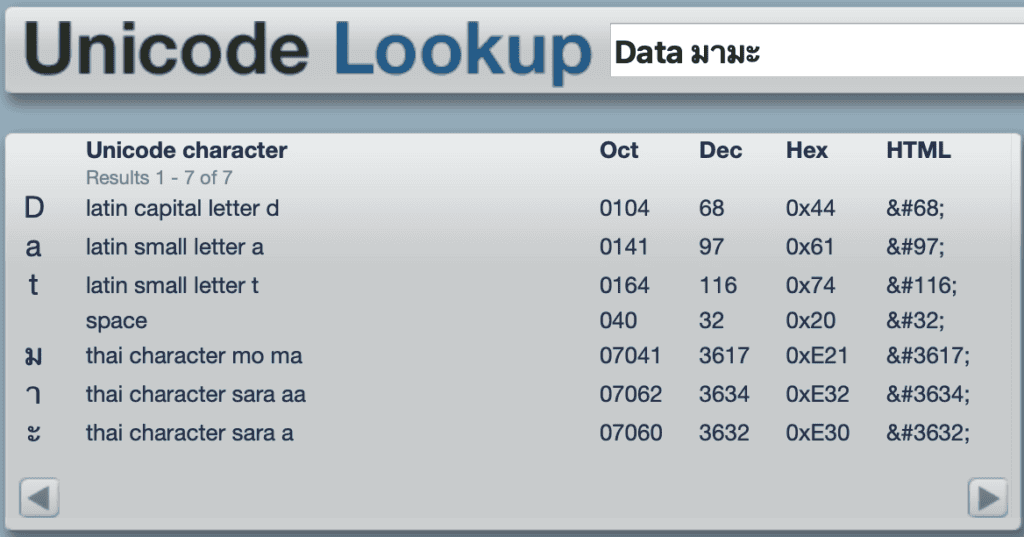
เราลองมาคิดดูกันเล่น ๆ นะครับว่าคอมพิวเตอร์ที่รู้จักเพียง “1” กับ “0” นั้นจะเก็บข้อมูล Unicode ได้อย่างไร สมมติว่าเราอยากเก็บข้อความภายใต้มาตรฐาน Unicode ต่อไปนี้ในคอมพิวเตอร์ :
“Data มามะ ?”
การที่เราจะเก็บข้อความนี้ได้ ผ่านมาตรฐาน Unicode เราก็ต้องรู้ก่อนว่าตัวอักษรแต่ละตัว มีเลขอัตลักษณ์อะไร ผู้อ่านสามารถลองเล่นเว็บไซต์ unicodelookup.com เพื่อหาเลขอัตลักษณ์ของอักขระ Unicode ได้ (รูปที่ 3) จากนั้นเราก็ต้องแปลงเลขอัตลักษณ์เหล่านี้ เป็นเลขฐานที่คอมพิวเตอร์เข้าใจ คือ เลขฐานสอง ในกรณีนี้สมมติว่าเรากำหนดให้หนึ่งตัวอักษรใช้เนื้อที่เก็บเท่า ๆ กัน (fixed-length encoding) อยู่ที่ 32 bits (4 bytes) ผู้อ่านสามารถใส่โค้ดตาม Code Block 1 ลง Python ผลที่ออกมาก็จะได้ดังตารางที่ 2 ครับ
def convertToBinary(hexStr):
return bin(int(hexStr, 16))[2:].zfill(32)
u = "Data มามะ ?"
for i, c in enumerate(u):
hexadecimal = '%04x' % ord(c)
print(c, hexadecimal, convertToBinary(hexadecimal))| อักขระ | Unicode code point | แปลงเป็นเลขฐานสอง (fixed 32 bits) |
|---|---|---|
| D | U+0044 | 00000000000000000000000001000100 |
| a | U+0061 | 00000000000000000000000001100001 |
| t | U+0074 | 00000000000000000000000001110100 |
| a | U+0061 | 00000000000000000000000001100001 |
| space | U+0020 | 00000000000000000000000000100000 |
| ม | U+0E21 | 00000000000000000000111000100001 |
| า | U+0E32 | 00000000000000000000111000110010 |
| ม | U+0E21 | 00000000000000000000111000100001 |
| ะ | U+0E30 | 00000000000000000000111000110000 |
| space | U+0020 | 00000000000000000000000000100000 |
| ? | U+1F60A | 00000000000000011111011000001010 |
จากนั้น คอมพิวเตอร์ก็จะจัดเก็บเลขฐานสองเหล่านี้ได้ ไม่ยากใช่ไหมครับ? จริง ๆ แล้ว นี่เป็นไอเดียที่คล้ายคลึงกับ “UTF-32” ซึ่งเป็นมาตรฐานอุตสาหกรรมการเข้ารหัส Unicode แบบหนึ่ง โดยทุก ๆ ตัวอักษรใช้เนื้อที่ 32 bits หรือ 4 bytes ในการจัดเก็บเท่ากันหมด
ผู้อ่านที่ช่างสังเกต คงจะเห็นข้อเสียของ fixed-length encoding อย่างตัวอย่างในตารางที่ 2 หรือ UTF-32 แล้วตรงที่ว่า มันเปลืองที่มาก ตัวอักษรจำนวนมาก โดยเฉพาะข้อความภาษาอังกฤษ หากจะเก็บกันจริง ๆ ใช้ไม่เกิน 8 bits ต่ออักขระก็พอแล้ว ไม่จำเป็นต้องเก็บเลขศูนย์นำหน้าจำนวนมากเช่นนี้ ด้วยสาเหตุนี้ ทำให้ระบบหลาย ๆ ระบบนิยมใช้ “UTF-8” สำหรับการเข้ารหัส Unicode มากกว่า ซึ่งเป็นการเข้ารหัสที่มีการ optimize ให้เนื้อที่เก็บต่อตัวอักขระที่ไม่เท่ากัน (variable-length encoding) คือ ใช้ 8, 16, 24, หรือ 32 bits (1 – 4 bytes) ทำให้ประหยัดเนื้อที่ในการจัดเก็บข้อมูลข้อความจำนวนมากได้ แม้กระทั่ง Python ก็เลือกใช้การเข้ารหัส UTF-8 by default ควบคู่กับการสนับสนุน Unicode by default สำหรับตัวแปร str อีกด้วยครับ
กระบวนการเข้ารหัสของ UTF-8 มีความซับซ้อนเกินจากขอบเขตของบทความนี้ ผู้อ่านที่สนใจสามารถศึกษาเพิ่มเติมได้จาก Wikipedia ครับ
ทำความคุ้นเคยกับข้อมูลภาษาไทย และ Unicode support ใน Python 3
เราทราบแล้วว่า Python 3 สนับสนุน Unicode by default สำหรับตัวแปรชนิดข้อความ str เราลองมาเล่นกับตัวอย่างจริงใน Python 3 กันดีกว่าครับ หากผู้อ่านลองใส่โค้ดต่อไปนี้ใน Jupyter Notebook แล้วศึกษาผลลัพธ์ :
s = "มามะ"
s_e = s.encode()
# 'มามะ'
print(s)
# b'xe0xb8xa1xe0xb8xb2xe0xb8xa1xe0xb8xb0'
print(s_e)
# Same as `s.encode()`
print(s.encode("utf-8"))
# b'\u0e21\u0e32\u0e21\u0e30'
print(s.encode("raw_unicode_escape"))
# 'มามะ'
print(s_e.decode())
# str and bytes, respectively
print(type(s))
print(type(s_e))
# 4 and 12, respectively
print(len(s))
print(len(s_e))เราจะพบว่า s เป็น Python string ที่สามารถแสดงผลตัวอักขระ Unicode ได้ปกติ เมื่อแสดงผลใน console และมีชนิดตัวแปรเป็น str
เมื่อเราเข้ารหัส s เพื่อให้สามารถจัดเก็บข้อมูลนี้ในคอมพิวเตอร์ได้ เราจะใช้ฟังก์ชัน encode ซึ่งจะทำการเข้ารหัส s (ไอเดียคือการแปลงข้อความเป็น machine-readable numbers เหมือนกับตัวอย่างที่ผมได้นำเสนอไปข้างต้นในตารางที่ 2) โดย Python จะใช้ UTF-8 encoding by default แต่เราสามารถเลือก encoding ได้เองในพารามิเตอร์ของฟังก์ชันนี้ จากตัวอย่างข้างต้น ที่เราใส่พารามิเตอร์ "raw_unicode_escape" หรือ "utf-8" ลงไปในฟังก์ชัน encode
เราจะพบว่า คำว่า “มามะ” ใน Unicode ถูกเข้ารหัสแบบ UTF-8 เป็น b'xe0xb8xa1xe0xb8xb2xe0xb8xa1xe0xb8xb0' มีชนิดตัวแปร bytes สังเกตจาก b marker ที่อยู่ข้างหน้าลำดับของ byte objects ซึ่งแต่ละอักขระภาษาไทย จะใช้ 3 bytes ในการเข้ารหัสตามหลัก UTF-8 ทำให้เมื่อเราใช้คำสั่ง len เราจะพบว่า ความยาวของข้อมูลข้อความเดิมเป็น 4 ตัวอักษร แต่ความยาวของจำนวน bytes ที่ใช้คือ 12 bytes นั่นเอง
เราสามารถลองเข้ารหัสแบบ "raw_unicode_escape" ซึ่งใน bytes form จะแสดงผลเป็น Unicode code points ได้อีกด้วย ในที่นี่ “มามะ” ถูกแปลงเป็น code points ได้เป็น b'\u0e21\u0e32\u0e21\u0e30'
เราสามารถแปลงข้อมูลประเภท bytes กลับเป็น str ได้ด้วยฟังก์ชัน decode ตามตัวอย่างข้างต้น (อย่าลืมว่าต้องเลือก decoding ที่เข้าคู่กับ encoding ที่ใช้ด้วยนะครับ)
ความน่าสนใจอย่างหนึ่ง ก็คือ ตัวอักษรภาษาอังกฤษ เมื่อถูก encoded แล้ว ก็ยังอ่านออกเหมือนเดิม แถมยังความยาวเท่าเดิมด้วยระหว่าง ความยาวข้อความ กับความยาวจำนวน bytes :
s = "Data"
s_e = s.encode()
# 'Data'
print(s)
# b'Data'
print(s_e)
# 4
print(len(s))
# 4
print(len(s_e))ผู้อ่านเดาออกไหมครับว่าเป็นเพราะอะไร? ถูกต้องแล้วครับ เพราะตัวอักษรภาษาอังกฤษใน Unicode ทุกตัว มี backward compatibility กับ ASCII และใช้เพียง 1 byte ต่อตัวอักษร ทำให้ความยาวเท่ากัน และที่แสดงผลแบบอ่านออกได้นั้น เพราะ Python ออกแบบให้ข้อมูลชนิด bytes แสดงผลแต่ละ byte เป็นอักขระ ASCII เท่านั้น (ซึ่งไม่น่าแปลกใจอะไร เพราะ 1 byte ไม่สามารถแสดงผลตัวอักษรอะไรได้อีกมากนักนอกเหนือจากอักขระ ASCII)
พักยกกันก่อน
ไม่ยากเลยใช่ไหมครับ? ในภาคถัดไปของบทความนี้ เราลองมาดูว่าความรู้เรื่อง ASCII and Unicode representations, Unicode code points, encoding and decoding สามารถช่วยเราแก้ปัญหาต่าง ๆ ในสถานการณ์จริงได้อย่างไรกันครับ ?

Former-Editor-in-Chief at BigData.go.th and Senior Data Scientist at Government Big Data Institute (GBDi )









