
[latexpage]

เคยคิดดูไหมว่า “หากเราจะจัดชั้นวางของในห้างสรรพสินค้า จะวางอะไรไว้ใกล้กับอะไรดี”, “หากเรามี online shopping application เราจะแนะนำสินค้าอะไรต่อไปให้ลูกค้าดี” หรือ “หากเราต้องการจะทำโปรโมชั่นแนะนำสินค้า เราจะแนะนำสินค้าอะไรคู่กันดี”
Association rule หรือ กฎความสัมพันธ์ เป็นหนึ่งในเครื่องมือเพื่อการวิเคราะห์ตะกร้าตลาด (Market basket analysis) ที่สามารถเข้ามาช่วยตอบคำถามเหล่านี้ได้
Market Basket Analysis หรือ การวิเคราะห์ตะกร้าตลาด เป็นการวิเคราะห์เพื่อค้นหากลุ่มสิ่งของที่น่าจะปรากฎร่วมกันในตะกร้าซื้อขาย โดยผลลัพธ์ที่ได้จะแสดงในรูปของกฎที่บ่งบอกถึงความเป็นไปได้ในการซื้อสินค้าต่าง ๆ ร่วมกัน
ในบทความนี้ เราจะมาทำความเข้าใจคำศัพท์ที่สำคัญ และตัววัดประสิทธิภาพที่ใช้กับกฎของความสัมพันธ์กันค่ะ
สมมติว่าในร้านค้าของเรามีสินค้าอยู่ 5 ชนิด ได้แก่ ขนมปัง ไข่ เนย น้ำเปล่า และข้าว โดยมีการซื้อขายทั้งหมด 4 ตะกร้า ดังต่อไปนี้
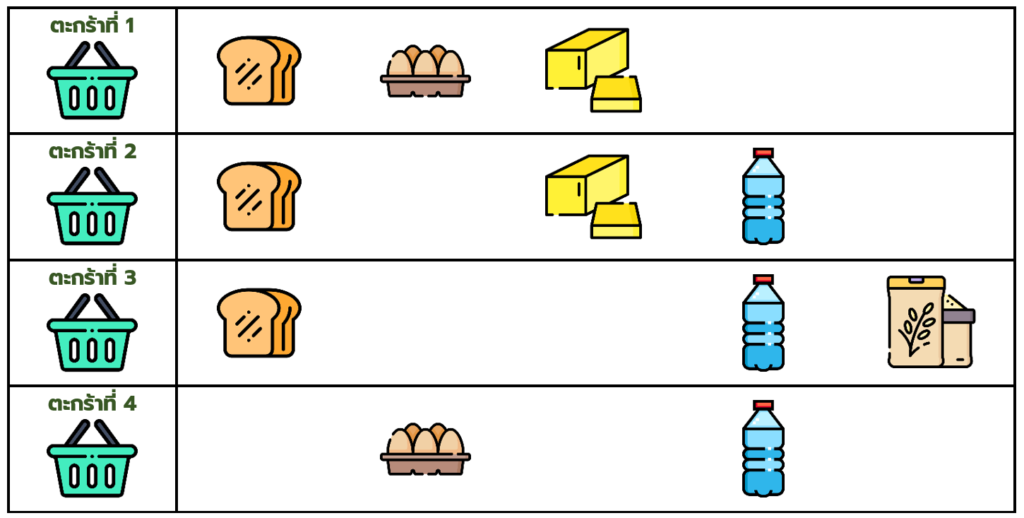
ซึ่งสามารถเขียนแทนด้วยตารางข้างล่าง
| สินค้า | ตะกร้าที่ (Transaction ID) | |||
| 1 | 2 | 3 | 4 | |
| ขนมปัง | 1 | 1 | 1 | |
| ไข่ | 1 | 1 | ||
| เนย | 1 | 1 | ||
| น้ำเปล่า | 1 | 1 | 1 | |
| ข้าว | 1 | |||
คำศัพท์สำคัญ (Key terms)
เป้าหมายของการทำ Market basket analysis คือ เพื่อค้นหากลุ่มของสินค้าที่มีความสัมพันธ์กัน จึงเป็นการดีหากเราสามารถแทนคำศัพท์สำคัญที่เกี่ยวข้องนี้ (กลุ่มของสินค้า และ ความสัมพันธ์ระหว่างกลุ่มของสินค้า) ด้วยสัญลักษณ์ทางคณิตศาสตร์
- Itemset = กลุ่มของสินค้า ตั้งแต่ 1 ชนิดขึ้นไป เขียนแทนด้วยสัญลักษณ์ เซต {X}
เช่น {น้ำเปล่า} {ขนมปัง, ไข่} {ขนมปัง, เนย, น้ำเปล่า}
จะเห็นว่า หากเรามีสินค้าจำนวน N ชนิด เราสามารถเขียนกลุ่มของสินค้าที่แตกต่างกันได้ถึง 2N-1 รูปแบบเลยทีเดียว
- Association rule = กฎของความสัมพันธ์ ระหว่างกลุ่มของสินค้า 2 กลุ่ม มีรูปแบบการเขียน คือ
Itemset LHS (Left-hand side) => Itemset RHS (Right-hand side)
แสดงถึง การที่ลูกค้าซื้อกลุ่มของสินค้า LHS แล้วจะซื้อกลุ่มของสินค้า RHS ร่วมด้วย หรือ การพบกลุ่มของสินค้า RHS ในตะกร้าที่มีกลุ่มของสินค้า LHS
ตัวอย่างเช่น {ขนมปัง} => {เนย} แสดงถึง การที่ลูกค้าซื้อขนมปังแล้วจะซื้อเนยร่วมด้วย หรือ การพบเนยในตะกร้าที่มีขนมปัง
- การสร้างกฎของความสัมพันธ์ จากกลุ่มของสินค้า
สำหรับกลุ่มของสินค้า (itemset) ที่มีจำนวนสินค้าตั้งแต่ 2 ชนิดขึ้นไป เราสามารถสร้างกฎของความสัมพันธ์ได้โดยการแบ่งสินค้าเป็นสองกลุ่ม (binary partition)
ตัวอย่างเช่น หากเรามี itemset = {ขนมปัง, เนย, ไข่} กฎที่เป็นไปได้ ได้แก่- {ขนมปัง => เนย, ไข่}
- {เนย => ขนมปัง, ไข่}
- {ไข่ => ขนมปัง, เนย}
- {ขนมปัง, เนย => ไข่}
- {ขนมปัง, ไข่ => เนย}
- {เนย, ไข่ => ขนมปัง}
ตัววัดประสิทธิภาพ (Metrics)
จะเห็นได้ว่าสินค้าที่มีในร้านเพียงไม่กี่ชนิด สามารถสร้าง itemsets และ rules ได้หลากหลายรูปแบบ (สินค้าเพียง 5 ชนิดสามารถสร้าง itemsets ได้ถึง 31 รูปแบบ และสร้าง rules ได้ถึง 180 รูปแบบ) อันที่จริงจำนวนรูปแบบของ itemsets และ rules ที่เป็นไปได้ทั้งหมดเติบโตแบบ exponential เมื่อเทียบกับจำนวนสินค้าภายในร้านเลยทีเดียว [Tan, Steinbach & Kumar, 2006]
อย่างไรก็ตาม ไม่ใช่ว่าทุกรูปแบบของ itemsets หรือ rules ที่มีความสำคัญ ตัววัดประสิทธิภาพที่ใช้ในการค้นหาความสัมพันธ์ (association mining) ที่มีความสำคัญจริง ๆ มีอยู่ด้วยกัน 3 ตัว
1 Support
Support เป็นตัววัดประสิทธิภาพสำหรับ itemset โดยเป็นตัวเลขที่แสดงสัดส่วนของจำนวนตะกร้าการซื้อขายที่มี itemset ต่อจำนวนตะกร้าการซื้อขายทั้งหมด หรือกล่าวได้ว่า “มีการซื้อขายที่มี itemset อยู่ด้วยเป็นสัดส่วนเท่าไหร่ ในการซื้อขายทั้งหมด”
หากเขียนในรูปแบบสมการทางคณิตศาสตร์จะได้ว่า
| Support(Itemset) | $=$ | จำนวนตะกร้าซื้อขายที่มี itemset |
| จำนวนตะกร้าซื้อขายทั้งหมด |
ในตัวอย่างร้านค้าของเรา หากพิจารณา Itemset = {ขนมปัง} จะได้ว่า Support({ขนมปัง}) = 3/4 = 0.75

Support เป็นปราการด่านแรกที่ช่วยตัดจำนวน rules ที่จะเกิดขึ้นให้น้อยลง โดยจะคัดเลือกเฉพาะ itemsetที่มีค่า support มากกว่า minimum support threshold (ตัวเลขนี้ขึ้นอยู่กับโจทย์ปัญหาและประสบการณ์ของนักวิทยาศาสตร์ข้อมูล)
ทั้งนี้ เนื่องจาก การที่กลุ่มของสินค้า (itemset) ใด ๆ มีสัดส่วนการปรากฏตัวในตะกร้าซื้อขายน้อยเกินไป ทำให้เรามีข้อมูลไม่เพียงพอที่จะสรุปความสัมพันธ์ของสินค้าภายในกลุ่มนั้น ๆ จึงตัดกลุ่มของสินค้า (itemset) นั้นออกจากการพิจารณาที่จะนำไปสร้าง rules
จากกรณีตัวอย่าง หากเรากำหนด minimum support threshold = 0.5 และคัดเลือกเฉพาะ itemsets ที่มีค่า support มากกว่าหรือเท่ากับค่านั้น
พิจารณากรณี itemset ที่มีสมาชิก 1 ตัว ข้าวจะถูกตัดออกไป เนื่องจาก support({ข้าว}) = 0.25 ซึ่งน้อยกว่า 0.5
| สินค้า | ตะกร้าที่ (Transaction ID) | Support | |||
| 1 | 2 | 3 | 4 | ||
| ขนมปัง | 1 | 1 | 1 | 3/4 = 0.75 | |
| ไข่ | 1 | 1 | 2/4 = 0.5 | ||
| เนย | 1 | 1 | 2/4 = 0.5 | ||
| น้ำเปล่า | 1 | 1 | 1 | 3/4 = 0.75 | |
| ข้าว | 1 | 1/4 = 0.25 | |||
หากนำสมาชิกที่เหลือมาพิจารณากรณี itemset ที่มีสมาชิก 2 ตัว จะพบว่าเหลือ itemsets {ขนมปัง, เนย} และ {ขนมปัง, น้ำเปล่า} เท่านั้น ที่มี support >= 0.5 และหากพิจารณาต่อไปยังกรณี itemset ที่มีสมาชิก 3 ตัว จะพบว่าไม่มี itemset ใดเลยที่มี support >=0.5
| สินค้า | ตะกร้าที่ (Transaction ID) | Support | |||
| 1 | 2 | 3 | 4 | ||
| ขนมปัง, ไข่ | 1 | 1/4 = 0.25 | |||
| ขนมปัง, เนย | 1 | 1 | 2/4 = 0.5 | ||
| ขนมปัง, น้ำเปล่า | 1 | 1 | 2/4 = 0.5 | ||
| ไข่, เนย | 1 | 1/4 = 0.25 | |||
| ไข่, น้ำเปล่า | 1 | 1/4 = 0.25 | |||
| เนย, น้ำเปล่า | 1 | 1/4 = 0.25 | |||
Itemsets ที่ผ่านการคัดกรอง จะถูกเรียกว่า frequent itemsets และมีดังตารางข้างล่าง
| Frequent itemset | Support | Size |
| ขนมปัง | 0.5 | 1 |
| ไข่ | 0.5 | 1 |
| เนย | 0.5 | 1 |
| น้ำเปล่า | 0.75 | 1 |
| ขนมปัง, เนย | 0.5 | 2 |
| ขนมปัง, น้ำเปล่า | 0.5 | 2 |
2 Confidence
หลังจากที่ได้ frequent itemsets มาแล้ว ขั้นตอนถัดมาคือ การสร้างกฎของความสัมพันธ์จาก frequent itemsets ที่มีจำนวนสมาชิกตั้งแต่ 2 items ขึ้นไป ในรูปแบบ LHS => RHS และวัดประสิทธิภาพของกฎที่ได้ โดยใช้ตัววัดประสิทธิภาพของกฎ ที่ชื่อว่า confidence และ lift
Confidence เป็นตัววัดประสิทธิภาพสำหรับ association rule โดยเป็นตัวเลขที่แสดงความน่าจะเป็นที่กลุ่มของสินค้า RHS จะถูกหยิบเข้าตะกร้าด้วย หลังจากที่กลุ่มของสินค้า LHS ถูกหยิบเข้าตะกร้าไปแล้ว
จากกฎของความสัมพันธ์ LHS => RHS ค่าของ confidence ถูกเขียนด้วยสมการทางคณิตศาสตร์ คือ
| Confidence(LHS => RHS) | $=$ | Support(LHS, RHS) | $=$ | จำนวนตะกร้าซื้อขายที่มีทั้ง LHS และ RHS |
| Support(LHS) | จำนวนตะกร้าซื้อขายที่มี LHS |
หากแปลเป็นภาษาพูดจะได้ว่า “หากเราพิจารณาเฉพาะตะกร้าการซื้อขายที่มีกลุ่มสินค้า LHS มีตะกร้าการซื้อขายที่มี RHS อยู่ด้วยเป็นสัดส่วนเท่าไหร่”
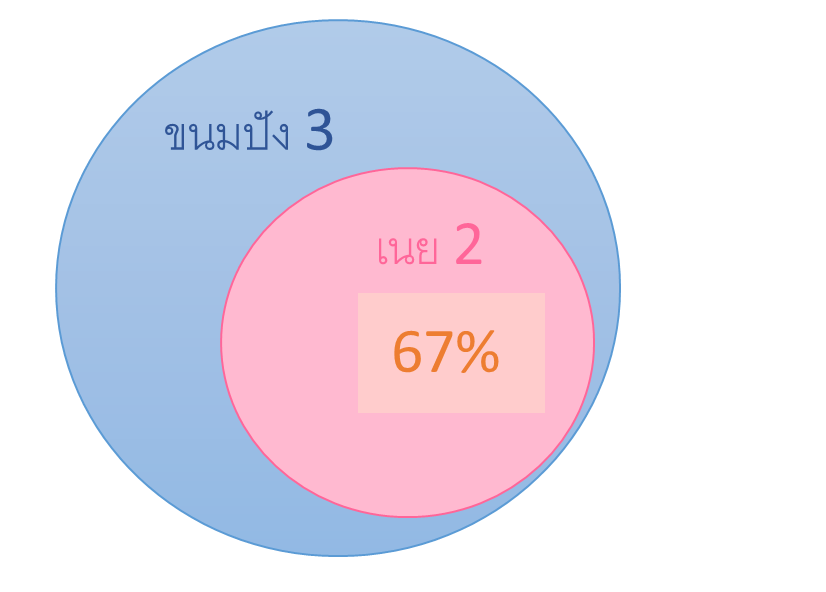
ในตัวอย่างร้านค้าของเรา หากพิจารณา LHS = {ขนมปัง} และ RHS = {เนย} จะได้ว่า Confidence( {ขนมปัง} => {เนย}) = 2/3 (“ภายใน 3 ตะกร้าที่มีการซื้อขายขนมปัง มีจำนวน 2 ตะกร้าที่มีการซื้อขายเนยด้วย”)
Confidence เป็นปราการด่านที่สองในการคัดเลือก rules ที่สำคัญ โดยเราจะคัดเลือกเฉพาะ rules ที่มีค่า confidence มากกว่า minimum confidence threshold (เฉกเช่นเดียวกับ minimum support threshold ตัวเลขนี้ขึ้นอยู่กับโจทย์ปัญหาและประสบการณ์ของนักวิทยาศาสตร์ข้อมูล)
ค่า confidence(LHS => RHS) ที่สูง แสดงความมั่นใจว่า หากในตะกร้ามีกลุ่มของสินค้า LHS อยู่ กลุ่มของสินค้า RHS ก็จะถูกหยิบไปด้วย
จากเคสตัวอย่างของเรา สามารถสร้าง association rules และคำนวณ confidence ได้ดังตารางที่แสดงข้างล่าง หากเราเลือกตัดที่ minimum confidence threshold = 0.5 จะเห็นว่า ไม่มีกฎไหนเลยที่ถูกตัดออกไป
| Rule | Confidence |
| ขนมปัง => เนย | 2/3 = 0.67 |
| เนย => ขนมปัง | 2/2 = 1 |
| ขนมปัง => น้ำเปล่า | 2/3 = 0.67 |
| น้ำเปล่า => ขนมปัง | 2/3 = 0.67 |
แต่ช้าก่อนการใช้ค่า confidence อย่างเดียวในการตัดสินใจ อาจนำไปสู่ข้อสรุปที่ผิดพลาดได้ ตัวอย่างเช่น Confidence({ขนมปัง} => {น้ำเปล่า}) = 0.67 หรือ Confidence({ข้าว}=>{น้ำเปล่า}) = 1 ต่างมีค่าความเป็นไปได้ที่สูง ทั้งนี้เนื่องจากว่าน้ำเปล่าเป็นสินค้าที่ถูกเลือกซื้อบ่อย ที่ปรากฏอยู่ในแทบทุกตะกร้าการซื้อขาย
หาก RHS เป็นกลุ่มของสินค้าที่พบเจอในแทบทุกตะกร้าการซื้อขาย (a very frequent itemset) ไม่ว่า LHS จะเป็นกลุ่มของสินค้าใดก็ตาม Confidence(LHS => RHS) จะมีค่าค่อนข้างสูงเสมอ
ด้วยเหตุนี้ จึงมีอีกหนึ่งตัววัดประสิทธิภาพที่พิจารณาความถี่ในการพบกลุ่มของสินค้า RHS ร่วมกับค่า confidence ด้วย
3 Lift
Lift เป็นตัววัดประสิทธิภาพสำหรับ association rule ที่ทำการเปรียบเทียบ ความน่าจะเป็นที่จะพบกลุ่มของสินค้า RHS ในตะกร้าที่มีการซื้อขายกลุ่มของสินค้า LHS กับ ความน่าจะเป็นที่จะพบกลุ่มของสินค้า RHS ในตะกร้าทั้งหมด
จากกฎของความสัมพันธ์ LHS => RHS ค่าของ Lift ถูกเขียนด้วยสมการทางคณิตศาสตร์
$$ Lift(LHS => RHS) = \frac{Support(LHS,RHS)}{Support(LHS)\times Support(RHS)} = \frac{Confidence(LHS => RHS)}{Support(RHS)}$$
หากลองพิจารณาดู จะพบว่า ค่า Lift เปรียบเทียบให้เราว่า “ความน่าจะเป็นที่ลูกค้าจะหยิบกลุ่มสินค้า RHS หลังจากที่ลูกค้าหยิบกลุ่มสินค้า LHS ลงตะกร้าไปแล้ว เพิ่มหรือลดเป็นจำนวนกี่เท่าของความน่าจะเป็นที่ลูกค้าจะซื้อกลุ่มสินค้า RHS โดยปกติ”
ซึ่งก็ตรงตามความหมายของคำว่า Lift กล่าวคือ หากค่า Lift > 1 (เท่า) แสดงว่า การที่ภายในตะกร้ามีกลุ่มสินค้า LHS อยู่ ทำให้ความน่าเป็นที่ลูกค้าจะหยิบ RHS มาใส่ตะกร้ามีค่าเพิ่มขึ้น
การมีอยู่ของกลุ่มสินค้า LHS ในตะกร้า ยก(lift) ค่าความน่าจะเป็นในการซื้อกลุ่มสินค้า RHS
หากค่า Lift = 1 แสดงว่า กลุ่มสินค้า LHS และ กลุ่มสินค้า RHS ไม่ขึ้นต่อกัน (independent)
ลองพิจารณาค่า Confidence และ Lift จากกรณีตัวอย่างของเรา
| Rule | Support(RHS) | Confidence | Lift |
| ขนมปัง => เนย | 0.5 | 0.67 | 0.67/0.5 = 1.34 |
| เนย => ขนมปัง | 0.75 | 1 | 1/0.75 = 1.34 |
| ขนมปัง => น้ำเปล่า | 0.75 | 0.67 | 0.67/0.75 = 0.9 |
| น้ำเปล่า => ขนมปัง | 0.75 | 0.67 | 0.67/0.75 = 0.9 |
จะเห็นว่า การมีขนมปังในตะกร้า เพิ่มความน่าจะเป็นที่ลูกค้าจะหยิบเนยด้วยจาก 0.5 ไป 0.67 (Lift = 1.34) ในทางกลับกัน การมีขนมปังในตะกร้าไม่ได้เพิ่มความน่าจะเป็นที่ลูกค้าจะหยิบน้ำเปล่าด้วย (Lift = 0.9)
ยิ่งค่า Lift มีค่ามากเท่าไหร่ ความน่าจะเป็นที่ลูกค้าจะหยิบสินค้า RHS ติดไปในตะกร้าที่มี LHS อยู่แล้ว ยิ่งมีค่ามากขึ้น
ค่า Lift นี้สามารถใช้ช่วยในการตัดสินใจเรื่อง การจัดวางตำแหน่งของสินค้าบนชั้นวางของ หรือ การแนะนำสินค้าเพิ่มเติมในระหว่างที่ลูกค้ากำลังซื้อสินค้าออนไลน์ หรือแม้แต่ การออกโปรโมชั่นกลุ่มสินค้าใหม่ ๆ ได้
What’s next?
ในบทความนี้ เราได้ทำความรู้จัก Association rule หรือกฎของความสัมพันธ์ ซึ่งประกอบด้วย itemsets และ rules พร้อมทั้งตัววัดประสิทธิภาพ (metrics) ที่ใช้เกี่ยวกับ association rule ทั้งสามอย่าง คือ support, confidence และ lift
จากที่เล่าไปในบทความ จำนวน itemset และ association rule แปรผันโดยตรงแบบ exponential กับจำนวนสินค้าที่มีในร้าน สินค้าเพียง 10 ชนิดก็สามารถสร้างกฎที่เป็นไปได้ถึง 57,000 กฎ ในโลกแห่งความเป็นจริง แต่ละร้านค้ามีสินค้าเป็นร้อยเป็นพันชนิด หากต้องคำนวณค่า lift ให้ครบทุกกฎคงเป็นการคำนวณที่มีต้นทุนสูงและใช้เวลาไม่น้อย (computationally expensive)
จะทำยังไงให้การค้นหา association rules ที่สำคัญ (Association rule mining) เป็นไปอย่างมีประสิทธิภาพ เพื่อน ๆ และผู้อ่านที่สนใจสามารถไปศึกษาเพิ่มเติมต่อได้ในหัวข้อเรื่อง Apriori algorithm ได้นะคะ
References:
Icons made by Freepik from www.flaticon.com
https://towardsdatascience.com/association-rules-2-aa9a77241654
http://www2.it.kmutnb.ac.th/teacher/FileDL/MissKanchana711256111164.pdf
เนื้อหาโดย ณัฐพัชร์ เศรษฐเสถียร ตรวจทานและปรับปรุงโดย นัทธมน มยุระสาคร













