
กล้องใหม่ ไซส์ Big เลยเอามาเล่าให้ชาว Big Data ฟัง
หลังจากที่นักดาราศาสตร์รอคอยกันมานาน ในที่สุดกล้องดูดาว Vera C. Rubin Observatory หรือที่เรียกว่า LSST ก็สร้างเสร็จและมีกำหนดการทดสอบใช้ครั้งแรกปลายปีนี้ (ในขณะที่ผู้เขียนกำลังเขียนอยู่นั้น ก็ได้ทราบข่าวร้ายว่าได้มีการเลื่อนเปิดไปเป็นปี 2023 เนื่องจากสถานการณ์โควิด-19)
แล้วกล้องดูดาวนี้พิเศษอย่างไร? กล้องดูดาวขนาดใหญ่จะมีส่วนประกอบสำคัญแบ่งได้เป็น 2 ส่วน ส่วนแรกคือส่วนรับแสงจากท้องฟ้า มีหน้าที่รวบรวมแสงอันริบหรี่ของดาวไกล ๆ ให้สว่างขึ้นจนมองเห็นได้บนภาพ ในส่วนนี้ LSST ใช้กระจกขนาดประมาณ 8 เมตรซึ่งถือว่าไม่ใหญ่มากเมื่อเทียบกับกล้องดูดาวชั้นนำแห่งอื่น แต่ความพิเศษของ LSST จะอยู่ในส่วนที่สอง ซึ่งก็คืออุปกรณ์รับภาพ เมื่อสร้างเสร็จ กล้อง LSST จะเป็นกล้องดิจิทัลที่มีขนาดใหญ่ที่สุดในโลก มีขนาดหน้ากล้องประมาณ 1.65 เมตร และมีอุปกรณ์รับภาพ 3.2-gigapixel CCD imaging camera หรือ 3,200 ล้านพิกเซล มากกว่ากล้องสมาร์ทโฟนที่เราใช้กันเป็นร้อยเท่า คาดการณ์ว่าจะเก็บข้อมูลแบบ raw ประมาณ 20 Terabyte ทุก ๆ คืน เก็บภาพแค่ชั่วโมงเดียวก็เต็มคอมพิวเตอร์ผู้เขียนแล้ว ? เรียกว่าเป็นกล้องดูดาวรุ่นใหม่ที่ให้ข้อมูลจำนวนมหาศาลแบบไม่เคยมีมาก่อนกับนักดาราศาสตร์
หากท่านที่คิดว่าข้อมูลทางดาราศาสตร์มันน่าจะใหญ่มากอยู่แล้วหรือเปล่า ผมขอยกตัวอย่างข้อมูลจากกล้องดูดาวที่มีชื่อเสียงมาเปรียบเทียบนะครับ
- Hubble Space Telescope เก็บข้อมูล raw 150 gigabit ต่อสัปดาห์ หรือประมาณ 1 TB ต่อปี (อ้างอิง: nasa.gov)
- VLT Survey Telescope ซึ่งเป็นกล้องที่มีวัตถุประสงค์คล้ายกันกับ LSST ที่ใช้งานอยู่ในปัจจุบัน เก็บข้อมูล raw ประมาณ 30 TB ต่อปี (อ้างอิง: Wikipedia)
พูดง่าย ๆ ก็คือ กล้อง LSST มีอัตราการเก็บข้อมูลที่สูงกว่ากล้องดูดาวที่มีอยู่ก่อน ถึง 200 – 8000 เท่าเลยทีเดียว!

Why big camera?
แล้วทำไมเราถึงต้องใช้กล้องขนาดใหญ่ขนาดนี้? ในส่วนแรก (ส่วนรับแสงจากท้องฟ้า) ขนาดหน้ากล้องดูดาวจะเป็นตัวกำหนดความสามารถในการรวมแสง และการแยกภาพของวัตถุสองชิ้นออกจากกัน ยิ่งกล้องมีขนาดใหญ่ ก็จะสามารถถ่ายภาพได้สว่างขึ้น และแยกภาพของวัตถุที่อยู่ใกล้กันได้มากขึ้น เนื่องจากวัตถุยิ่งอยู่ไกล ก็จะปรากฎบนภาพจางลง และมีรายละเอียดที่ใกล้กันมากขึ้น นั่นแปลว่ากล้องขนาดใหญ่จะทำให้เราศึกษาวัตถุได้ไกลมากขึ้น
ในส่วนที่สอง ขนาดของอุปกรณ์รับภาพ ยิ่งกล้องมีขนาดใหญ่ ก็จะทำให้สามารถถ่ายภาพได้กว้างขึ้น ซึ่งเมื่อเราได้ภาพกว้างขึ้นแต่ยังอยากให้มีรายละเอียดเท่าเดิม อุปกรณ์รับภาพก็ต้องมีจำนวนพิกเซลเยอะขึ้นตามไปด้วย ความสำคัญในส่วนนี้คือกล้องขนาดใหญ่จะสามารถถ่ายภาพครอบคลุมท้องฟ้าได้มากขึ้นในเวลาเท่าเดิม สมมติว่าเดิมเราต้องใช้เวลา 2 คืนเพื่อถ่ายภาพในบริเวณที่สนใจ ถ้าเราลดเวลาถ่ายภาพเหลือ 1 คืนได้ เราก็จะสามารถถ่ายภาพได้ถี่ขึ้น ซึ่งจะทำให้เราศึกษาการเปลี่ยนแปลงของท้องฟ้าได้ดีขึ้น
Data Science มีส่วนอย่างไรในการดูดาว
การจัดการข้อมูลมหาศาลขนาดนี้ ต้องมีการออกแบบ data pipeline และ architecture ที่ดีมาก นอกจากนี้แล้ว ยังมีปัญหาที่สำคัญอีกประการหนึ่งสำหรับนักดาราศาสตร์ คือ ข้อมูลที่ถูกสร้างจำนวนมหาศาลขนาดนี้ การใช้ “คน” มาเลือก “รูป” ที่น่าสนใจก่อนที่จะนำไปวิเคราะห์เชิงดาราศาสตร์ จะเป็นกระบวนการที่ใช้เวลามากตามไปด้วย จินตนาการเหมือนให้นักดาราศาสตร์มานั่งดูรูปด้วยตาทีละรูป นี่ยังไม่ได้เข้าสู่กระบวนการนำรูปไปวิเคราะห์เลย ก็อาจจะใช้เวลาเป็นเดือนหรือเป็นปีแล้ว การจะนำข้อมูล raw ขนาดมหาศาลนี้ไปส่งให้ถึงมือนักดาราศาสตร์ที่สนใจได้ ระบบจำเป็นที่จะต้องมีการวิเคราะห์ข้อมูลโดยอัตโนมัติ เพื่อที่จะเลือกภาพที่น่าสนใจให้คนไปศึกษาต่อ เป็นที่มาของการใช้ Data Science ในการดูดาว
ในบทความนี้ผู้เขียนจะกล่าวถึงกระบวนการทางดาราศาสตร์ที่ได้นำเทคนิคทาง Data Science มาประยุกต์ใช้ สองกระบวนการครับ คือ การเลือกรูปที่น่าสนใจจากข้อมูลมหาศาลมาวิเคราะห์ และการจำแนกเหตุการณ์ทางดาราศาสตร์ ครับ
ข้อมูลมหาศาล ทำอย่างไรให้ได้สิ่งที่นักดาราศาสตร์สนใจ
หลายคนอาจจะคิดไว้ในใจแล้วว่านี่เป็นโจทย์ Anomaly detection แต่สิ่งที่ทางนักดาราศาสตร์ของ LSST ทำนั้นง่ายกว่านั้นมาก เค้าแค่เลือกใช้เฉพาะจุดที่มีการเปลี่ยนแปลงของแสงเกินค่า threshold ที่ตั้งไว้ครับ
ก่อนอื่นก็ต้องอธิบายก่อนว่า LSST เป็นกล้องประเภท survey ซึ่งจะทำการถ่ายภาพท้องฟ้าทุกคืนเพื่อหาสิ่งที่เปลี่ยนแปลงไปในแต่ละคืน และแจ้งเตือนแบบ real-time เพื่อให้นักดาราศาสตร์สามารถใช้กล้องแบบเฉพาะทาง เช่น กล้อง X-Ray ศึกษาไปพร้อมกันกับข้อมูลการเปลี่ยนแปลงของแสงที่ได้จากกล้อง LSST ดังนั้นสิ่งที่นักดาราศาสตร์อยากได้ไม่ใช่ภาพสวย ๆ แบบนี้

แต่จะเป็นข้อมูล time-series ของการเปลี่ยนแปลงของความสว่างของวัตถุ หรือเหตุการณ์ (เรียกว่า light curve) แบบนี้
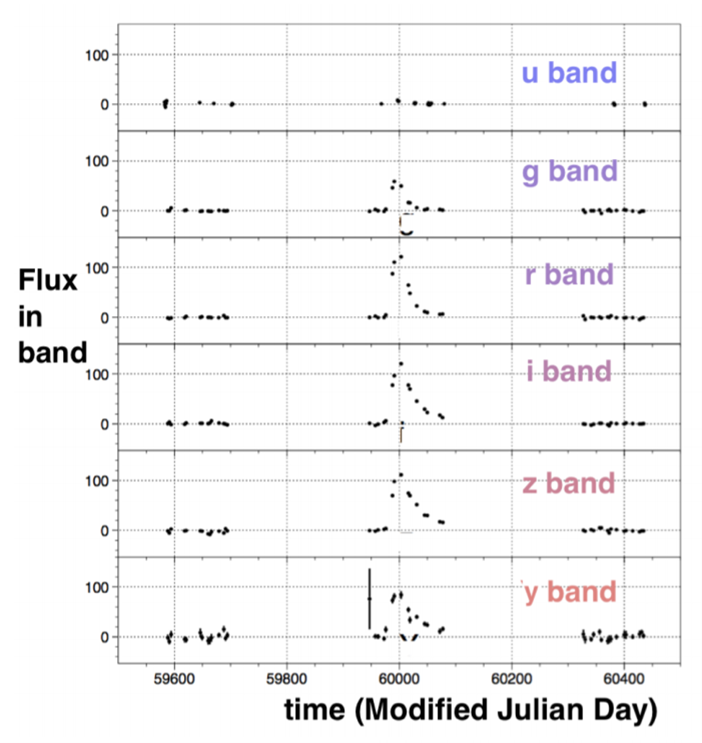
ข้อมูล light curve จากกราฟด้านบน จะเป็นข้อมูลของวัตถุเดียว หรือเหตุการณ์ในตำแหน่งเดียว ซึ่งก็คือข้อมูลเพียงพิกเซลเดียวบนกล้อง 3200 ล้านพิกเซล ที่ถูกเก็บมาตามช่วงเวลาที่ตั้งไว้ (เช่น หนึ่งวัน) แต่ก็คงไม่มีใครต้องการดูกราฟแบบนี้ 3200 ล้านกราฟด้วยตนเอง ดังนั้นเราจึงจำเป็นต้องให้คอมพิวเตอร์ทำการเลือกสิ่งที่น่าสนใจให้เราโดยอัตโนมัติ
สิ่งที่ต้องทำคือหาผลต่างของความสว่างในแต่ละพิกเซล เทียบกับภาพอ้างอิงของท้องฟ้าตำแหน่งเดียวกันในเวลาก่อนหน้า จากนั้นก็ทำการตั้ง threshold เพื่อเลือกพิกเซลที่มีการเปลี่ยนแปลงความสว่างเกินค่าที่กำหนด ในขั้นตอนนี้ทางนักวิจัยก็จะต้องศึกษา และตัดสินใจว่า threshold ควรเป็นเท่าไหร่ ซึ่งก็ต้องประเมินจาก noise ของภาพ ประกอบกับ false positive และ true negative rate ที่ต้องการ
สังเกตได้ว่าการทำ threshold ของแต่ละพิกเซล ไม่ได้นำข้อมูลโดยรอบมาคำนึงถึง จึงทำให้ไม่สามารถค้นพบและติดตามการเคลื่อนที่ของวัตถุบนภาพเช่น ดาวหาง หรือดาวเคราะห์ในระบบสุริยะของเราได้ แต่กล้องตัวนี้จะเน้นไปที่การค้นหาวัตถุหรือเหตุการณ์ที่เกิดขึ้นไกล ๆ ซึ่งภาพจากวัตถุไกล ๆ จะปรากฏเหมือนแทบไม่ขยับเลย
การเลือกตำแหน่งที่สนใจก็จะมีขั้นตอนเพียงเท่านี้ ซึ่งมันดูง่ายมาก ๆ จนเหมือนง่ายเกินไปหรือเปล่า? ถ้าเราต้องการความแม่นยำในการเลือกจุดสนใจ เรามีวิธีทางสถิติหรือ Data Science หลายวิธีที่ดีกว่าการทำ threshold แน่นอน แต่เหตุผลหลักของการทำ threshold คือเราไม่ได้ต้องการความแม่นยำมากขนาดนั้น เราทำขั้นตอนนี้เพื่อลดปริมาณข้อมูลที่ต้องใช้ประมวลผลในขั้นตอนถัดไป ดังนั้นวิธีที่ทำได้ง่าย ไว และไม่เปลืองทรัพยากรในการประมวลผล จึงเป็นวิธีที่เหมาะสมที่สุดครับ
จำแนกเหตุการณ์ทางดาราศาสตร์ด้วย Classification
หลังจากที่เราได้ตำแหน่งภาพที่มีการเปลี่ยนแปลงของความสว่าง และข้อมูล light curve ขั้นตอนถัดไปคือการใช้ Data Science ช่วยจำแนกข้อมูลที่ได้เป็นประเภทของเหตุการณ์ที่น่าสนใจทางดาราศาสตร์ด้วย classification ตัวอย่างเหตุการณ์ที่เกิดขึ้นในดาราศาสตร์ เช่น การระเบิดของดาวขนาดใหญ่เมื่อหมดอายุขัย (Supernova) ดาวแปรแสง (Cepheids) หรือดาวคู่ที่โคจรรอบกันและบังแสงกันเอง (Eclipsing Binaries) เป็นต้น โดยเหตุการณ์เหล่านี้ก็จะมีลักษณะของ light curve ที่แตกต่างกัน
เพราะฉะนั้น ข้อมูล light curve ที่แสดงการเปลี่ยนแปลงที่แสงสว่างตามช่วงเวลาที่ผ่านไป ประกบกับ label ว่า light curve ในลักษณะนี้จัดว่าเป็นปรากฎการณ์ทางดาราศาสตร์แบบใด (ซึ่ง LSST ก็มีการศึกษาไว้แล้วมากมาย) ก็ได้ถูกนำมาใช้เป็น training data เพื่อทำโจทย์นี้นั่นเองครับ

ทาง LSST จึงได้จัดการแข่งขัน The Photometric LSST Astronomical Time-Series Classification Challenge (PLAsTiCC) สำหรับโจทย์นี้ขึ้นมาบน Kaggle ครับ โดย LSST ได้จำแนกเหตุการณ์ออกเป็น 15 Class โดยจะมี 14 เหตุการณ์ และ 1 class สำหรับสิ่งที่ไม่เคยเห็นมาก่อน การแข่งขันก็จบลงไปแล้วเมื่อปี 2018 แต่ใครที่สนใจอยากลองนำข้อมูลไปเล่น ก็ยังสามารถดาวน์โหลดข้อมูลได้ที่ https://www.kaggle.com/c/PLAsTiCC-2018
วิธีจากการแก้โจทย์ classification นี้สามารถทำได้หลายวิธีเลย แต่ Kyle Boone ผู้ชนะการแข่งขันข้างต้น ได้ประยุกต์ใช้เทคนิค Gaussian processes เพื่อสร้าง smooth curve จากข้อมูล light curve ซึ่งเป็น time series และนำข้อมูลของ smooth curve นี้ ไปใช้ในการเทรนโมเดลในประเภท Neural Network ครับ เนื่องจาก Kyle ไม่ได้เขียนอธิบายตัวโมเดลชนะเลิศของเขาไว้ ผู้เขียนจึงขอข้ามรายละเอียดของโมเดลนะครับ

ต้องขอบอกไว้ก่อนเลยว่าทุกอย่างที่ผู้เขียนได้เล่ามานั้นยังขาดรายละเอียดปลีกย่อยที่สำคัญอีกมาก หากใครได้ลองดูข้อมูลจะพบว่าผู้เขียนได้ข้ามเรื่อง filter band ซึ่งคือการรับแสงในเฉพาะบางสี เพื่อให้เรามีข้อมูลแสงในหลายมิติ และข้ามเรื่อง Noise ไปทั้งหมดครับ ซึ่งเรื่องปลีกย่อยเหล่านี้ เป็นความรู้ที่ค่อนข้างเฉพาะทาง ทาง LSST ก็ได้เขียนอธิบายไว้ในเอกสารของการแข่งขันไว้แล้วครับ คนที่ไม่คุ้นเคยกับข้อมูลดาราศาสตร์ ก็ไม่ต้องกลัวว่าจะไม่เข้าใจครับ
และนี่ก็เป็นการใช้ data science เบื้องต้น เพื่อเลือกข้อมูลขนาดมหาศาลและนำส่งข้อมูลไปยังนักดาราศาสตร์ที่สนใจครับ โดย LSST จะให้นักดาราศาสตร์จากสถาบันที่เข้าร่วมโครงการ เลือก Subscribe การแจ้งเตือนจาก LSST ตามประเภทของเหตุการณ์ เมื่อระบบพบเหตุการณ์ประเภทที่สนใจ ก็จะส่งการแจ้งเตือนแบบ real-time ได้อย่างอัตโนมัติ
You can’t have people at every step of the process
– Kyle Boone ผู้ชนะการแข่งขัน PLAsTiCC
Learn more about LSST: https://www.lsst.org/ LSST Public code repository: http://dm.lsst.org/browse/
เนื้อหาโดย พชร วงศ์สุทธิโกศล ตรวจทานและปรับปรุงโดย ปพจน์ ธรรมเจริญพร




Former-Editor-in-Chief at BigData.go.th and Senior Data Scientist at Government Big Data Institute (GBDi )









