
ตั้งแต่การเรียนรู้เชิงลึก (Deep Learning) ถูกพัฒนาขึ้น ปัญญาประดิษฐ์ก็เข้ามามีบทบาทในชีวิตมนุษย์อย่างมาก ในหลายรูปแบบ ตั้งแต่ในแอปพลิเคชันบนสมาร์ตโฟน กล้องวงจรปิดที่ใช้ตามบ้าน แม้แต่โปรโมชันที่แบรนด์สินค้าเสนอให้กับเราในฐานะลูกค้าในหลายครั้งก็เป็นผลจากการใช้ปัญญาประดิษฐ์ เพื่อประมวลผลทางสถิติว่าโปรโมชันแบบไหนที่แต่ละคนจะตัดสินใจซื้อมากที่สุด ซึ่งในหลายครั้งมันก็ทำให้ลูกค้าจ่ายเงินซื้อสินค้าจากการแนะนำสินค้าได้ตรงใจ หรือแม้กระทั่งการแนะนำวิดีโอในแอปพลิเคชัน TikTok หรือ YouTube เพื่อดึงดูดความสนใจของผู้ใช้ให้รับชมคอนเทนท์ที่ชื่นชอบในระยะเวลาที่ยาวนานที่สุด โดยใช้เทคนิคต่าง ๆ อาทิเช่น Computer Vision เพื่อให้ระบบสามารถแยกแยะเนื้อหาของวีดีโอ และ Natural Language Processing ที่นำมาใช้แยกแยะเนื้อหาที่เป็นภาษา ( ai คือ อะไร )
ความสามารถของปัญญาประดิษฐ์ที่มนุษย์สร้างขึ้นถูกพัฒนาจนเริ่มที่จะเก่งกว่ามนุษย์ในหลายทักษะ หนึ่งในงานทดลองที่เป็นรู้จักคือการสอนให้คอมพิวเตอร์เล่นเกมเพื่อเอาชนะมนุษย์ หรือแม้กระทั่งในเกมที่ซับซ้อนอย่างหมากล้อม ก็สามารถเอาชนะมนุษย์ไปได้จนเป็นข่าวดังไปทั่วโลก จนในบางครั้งก็ทำให้เกิดความหวาดกลัวในปัญญาประดิษฐ์ว่ามันจะทำอะไรที่เป็นอันตรายต่อมนุษย์เหมือนกับในภาพยนตร์ชื่อดังหลายเรื่องหรือไม่ สื่อสังคมออนไลน์ถึงกับตื่นตระหนกกับข่าวที่ปัญญาประดิษฐ์ของ Facebook สร้างภาษาของตัวเองขึ้นมา และให้ความเห็นกันไปต่าง ๆ นานา
ในฐานะของผู้ที่มีประสบการณ์วิจัยเกี่ยวกับปัญญาประดิษฐ์มา ผู้เขียนสามารถบอกได้อย่างมั่นใจว่า “ปัญญาประดิษฐ์จะยังไม่ครองโลกในเร็ว ๆ นี้แน่นอน” เพราะความเก่งกาจจากการเรียนรู้ข้อมูลของปัญญาประดิษฐ์นั้นยังมีข้อจำกัดอย่างมาก ตัวอย่างหนึ่งที่เห็นได้ชัดเจนคือการที่เทคโนโลยี Self-Driving Car อย่างเต็มรูปแบบ (ไม่นับระบบช่วยเหลือในการขับอย่าง Cruise Control) ถูกเคยถูกพูดถึงกันมาอย่างยาวนานในวงการวิจัยนั้น ในขณะที่เขียนบทความนี้ (ตุลาคม 2565) เทคโนโลยีนี้ถูกใส่เข้ามาในรถยนต์ของผู้ให้บริการเพียงไม่กี่รายที่มีความสามารถในการวิจัยเทคโนโลยีที่ล้ำสมัยอย่างเช่น Tesla ซึ่งก็ยังมีข้อจำกัดอยู่ และก็ยังมีรายงานการเกิดอุบัติเหตุอยู่บ้างเช่นกัน
บทความนี้เราจะมาดูกันว่าข้อจำกัดอะไรบ้างที่ปัญญาประดิษฐ์ต้องก้าวข้ามไปให้ได้ และตัวอย่างของความอ่อนด้อยของปัญญาประดิษฐ์ในสิ่งที่เรื่องง่ายสำหรับมนุษย์
1. Domain Shift – โมเดลเรียนรู้และเก่งในเรื่องที่มีข้อมูลเท่านั้น และประสิทธิภาพลดลงอย่างมากเมื่อสภาพแวดล้อมเปลี่ยนไป
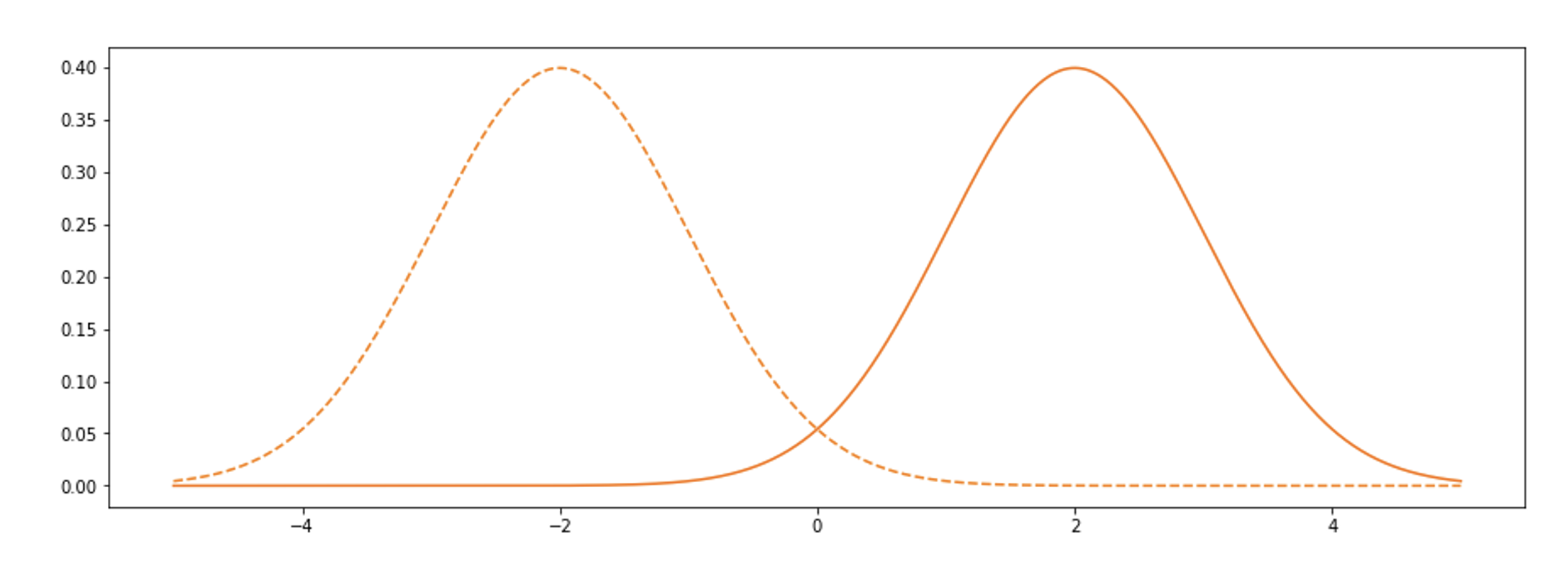
เป็นเรื่องจริงที่ปัญญาประดิษฐ์นั้นเรียนรู้จนเก่งในหลายเรื่อง แต่ความเก่งนั้นก็จำกัดอยู่กับสิ่งแวดล้อมที่มันเคยเรียนรู้มาเท่านั้น เมื่อสภาพแวดล้อมเปลี่ยนไปจากเดิม ประสิทธิภาพในการทำงานและการตัดสินใจก็จะเปลี่ยนไปอย่างมาก ปัญหานี้เป็นที่รู้จักกันในหลายชื่อเรียก เช่น Domain Shift, Distribution Shift, และ Data Drift เป็นต้น ซึ่งต่างก็มีความหมายที่คล้ายกัน คือการที่โดเมน (ขอบเขต) ของข้อมูลที่ปัญญาประดิษฐ์รับเข้าระบบ (Input) เปลี่ยนแปลงไปจากเดิม
Brostow, Shotton, Fauqueur, Cipolla (bibtex)
ตัวอย่างเช่นถ้าเราให้โมเดลเรียนรู้ข้อมูลที่มีการแจกแจงแบบหนึ่ง แต่พอนำโมเดลไปใช้จริงกลับมีการแจกแจงอีกแบบหนึ่ง ดังที่เห็นจากในตัวอย่างภาพการแจกแจงด้านบน ก็จะมีความเสี่ยงสูงที่การนำไปใช้จริงจะลดประสิทธิภาพของโมเดลนี้ หรือในกรณีของข้อมูลภาพที่เป็นถนนและสภาพจราจร การที่ข้อมูลที่ใช้สอนปัญญาประดิษฐ์ส่วนมากจะถูกเก็บมาจากช่วงเวลากลางวัน ซึ่งสภาพแสงต่างจากกลางคืนอย่างชัดเจน เมื่อนำมาใช้ประมวลผลกับภาพที่ได้ในเวลากลางคืนก็มีแนวโน้มที่ความถูกต้องในการทำงานจะลดลง การสอนระบบด้วยภาพในเมือง แต่นำไปใช้กับภาพถนนในชนบท หรือแม้แต่ในเงามืดที่แสงน้อยเองก็เช่นกันตามภาพที่ด้านล่าง

Pattern Recognition Letters (to appear)
Brostow, Fauqueur, Cipolla (bibtex)
2. Catastrophic Forgetting – เรียนเรื่องใหม่ ลืมเรื่องเก่า
การแก้ปัญหาในข้อที่ 1 แบบง่าย ๆ ก็คือการนำเอาข้อมูลในสิ่งแวดล้อมปัจจุบันที่ปัญญาประดิษฐ์พบเจออยู่ในขณะนั้นมาสอนระบบในทันที เพื่อให้มันสามารถปรับตัวกับสภาพแวดล้อมใหม่ ซึ่งก็สร้างปัญหาใหม่ขึ้นมาถึง 2 เรื่อง เรื่องแรกคือบริษัทที่เป็นผู้ให้บริการก็ต้องจ้างคนมาเพื่อสร้าง Label (หรือก็คือเฉลยของคำถาม) ในการสอนปัญญาประดิษฐ์ ซึ่งในงานประเภท Semantic Segmentation จะพบว่าการสร้าง Label นั้นค่อนข้างยาก ใช้เวลานาน และนำมาซึ่งต้นทุนที่สูงขึ้น
เรื่องที่สองที่จะเจอคือปัญหาที่เรียกว่า Catastrophic Forgetting หรือคือการเรียนเรื่องใหม่แล้วลืมเรื่องเก่า ปัญหานี้เกิดขึ้นเมื่อเรานำเอาข้อมูลใหม่เข้ามาสอนให้กับปัญญาประดิษฐ์เพื่อให้สามารถประมวลผลในโดเมนปัจจุบันได้ถูกต้อง แต่เมื่อนำโดเมนของข้อมูลเปลี่ยนกลับไปเป็นโดเมนเดิมในตอนต้น ความถูกต้องในการประมวลผลก็จะลดลง เพราะปัญญาประดิษฐ์ได้ทำการเรียนรู้กับข้อมูลในโดเมนใหม่และได้ลืมความรู้ในโดเมนเก่าไปแล้ว
3. Out-of-Distribution – ปัญญาประดิษฐ์มักไม่รู้ตัวว่าตนเองไม่มีความรู้
การใช้งานปัญญาประดิษฐ์ในโลกความเป็นจริงที่เป็นสิ่งแวดล้อมแบบเปิด (Open World) มักจะมีสิ่งที่ระบบไม่เคยเรียนรู้มาก่อนอยู่เสมอ โดยเฉพาะเมื่อพูดถึงโมเดลเพื่อการจำแนกประเภท (Classification Model) ที่ต้องระบุหมวดหมู่ (Class) ของการจำแนกที่ชัดเจนตั้งแต่ตอนที่นำข้อมูลมาเพื่อสอน ในขณะที่เมื่อนำเอาไปใช้จริงแล้วมักจะเจอกับข้อมูลที่อยู่ในหมวดหมู่ใหม่ที่ไม่เคยเรียนรู้มาก่อน สิ่งนี้เป็นเพราะในงานข้อมูลบางประเภท เช่น ภาพ หรือภาษา มีหมวดหมู่ที่ไม่แน่นอน เราไม่สามารถนำเอาทุกความเป็นไปได้ของข้อมูลมาสอนให้กับปัญญาประดิษฐ์ได้ หรือถ้าทำได้ เมื่อเวลาผ่านไปย่อมมีข้อมูลใหม่เกิดขึ้นอยู่เสมอ ดังนั้นการที่ระบบสามารถระบุได้เมื่อเจอข้อมูลที่แตกต่างออกไปจากเดิมนั้นเป็นสิ่งสำคัญมาก
ถ้าเป็นปัญญาประดิษฐ์ที่ใช้แยกแยะสายพันธุ์สุนัขจากภาพ เมื่อผู้ใช้นำภาพของแมวหรือนกมาให้จำแนกสายพันธุ์ ก็ควรจะต้องบอกได้ว่าสิ่งนั้นไม่ใช่สุนัข หรือถ้ามีสายพันธุ์ใหม่ที่ไม่เคยเจอ ก็ควรจะบอกผู้ใช้ได้ว่าไม่รู้จักสายพันธุ์นั้น ในกรณีของระบบที่เป็น Self-Driving Car อาจจะมีการใช้ปัญญาประดิษฐ์ที่เรียนรู้วัตถุต่าง ๆ จากภาพ เมื่อเจอวัตถุหรือสิ่งมีชีวิตบนท้องถนนที่ไม่เคยเจอมาก่อน ก็ควรจะออกแบบให้สามารถส่งต่อความไม่มั่นใจดังกล่าวให้กับมนุษย์ ให้คนขับเป็นผู้ตัดสินใจเองว่าจะขับต่อไป หรือเลี่ยงเส้นทาง
4. Calibration – ค่าความมั่นใจของคำตอบควรจะบอกความน่าจะเป็นที่คำตอบนั้นจะถูกต้อง
แน่นอนว่าไม่มีใครถูกเสมอ การทำนายหรือตอบคำถามของปัญญาประดิษฐ์นั้นก็เช่นเดียวกัน แต่ปัญหาก็คือ บ่อยครั้งที่พบว่าคำตอบของปัญญาประดิษฐ์ในงานจำแนกหมวดหมู่ (Classification) มักมาพร้อมกับค่าความมั่นใจที่มากเกินควร (ค่าความมั่นใจ หรือ Predicted Probability เป็นค่าที่คำนวณออกมากับคำตอบ)
ถ้าค่าความมั่นใจถูกต้อง เมื่อจำเอาตัวอย่างที่โมเดลมีค่าความมั่นใจที่ 0.8 หรือ 80% ทั้งหมดมา เราควรจะพบว่าคำตอบควรจะถูกต้องอยู่ที่ 80% จากข้อมูลทั้งหมดด้วยเช่นกัน ตัวอย่างเช่นปัญญาประดิษฐ์ที่ใช้จำแนกสายพันธุ์สุนัขจากภาพ ถ้าเราพบว่ามีภาพสุนัขทั้งหมด 1,000 ภาพที่ถูกจำแนก พร้อมกับมีค่าความมั่นใจที่ 0.8 ทั้งหมด เราก็ควรจะคาดหวังได้ว่าการจำแนกจะถูกต้องประมาณ 800 ภาพ หรือก็คือ 80%
ค่าความมั่นใจดังกล่าวย่อมส่งผลต่อการตัดสินใจเชื่อหรือไม่เชื่อคำตอบนั้น และการกระทำต่าง ๆ ที่ตามมาจากข้อสรุปนั้นทั้งหมด ถ้าโมเดลทำนายหุ้นบอกว่าหุ้น A จะขึ้นด้วยความมั่นใจ 70% เราก็อาจจะลงทุนด้วยจำนวนเงินที่น้อย แต่ลงเงินกับหุ้น B ที่โมเดลบอกว่าขึ้น 95% เป็นต้น อย่างไรก็ดีจากการศึกษาพบว่าปัญญาประดิษฐ์สมัยใหม่ที่ใช้ Deep Neural Network ที่มีชั้นและความซับซ้อนมาก มักพบว่าให้ค่าความมั่นใจที่ไม่ตรงกับอัตราความถูกต้องของคำตอบจริง
5. Explainability – ตัดสินใจแล้วควรจะต้องอธิบายได้ว่าเพราะอะไร
เมื่อเราใช้ปัญญาประดิษฐ์ตัดสินใจบางอย่างแล้วเกิดผลที่ตามมา ซึ่งอาจเป็นสิ่งที่ไม่พึงประสงค์สำหรับบางคน เช่น เมื่อสแกนใบหน้าไม่ผ่านทำให้เข้าประตูไม่ได้ หรือปัญญาประดิษฐ์ประเมินราคารถยนต์จากภาพถ่ายตีราคาออกมาต่ำกว่าที่ผู้เสนอขายคาดหวัง เป็นต้น สิ่งเหล่านี้ควรสามารถอธิบายเหตุผลของการทำนายนั้นได้ด้วย การสแกนใบหน้าที่ไม่ผ่านอาจเป็นเพราะผู้ใช้ลืมถอดแว่นกันแดด ระบบก็อาจจะบอกเหตุผลเพื่อให้ปรับปรุงและลองอีกครั้ง
ยิ่งความซับซ้อนมีมากขึ้นเท่าไหร่ ความยากในการอธิบายเหตุผลก็มีมากขึ้นเรื่อย ๆ ในความเป็นจริงแล้วระบบสามารถอธิบายออกมาได้เพียงระดับเบื้องต้น เช่นในกรณีของข้อมูลภาพ อาจจะมีการทำ Heatmap บอกว่าส่วนไหนของภาพที่ส่งผลต่อการตัดสินใจ แต่ก็ไม่สามารถบอกเป็นเหตุผลมาอย่างชัดเจนได้ว่าเพราะอะไร

[bibtex]
ในกรณีที่ระบบมีการตัดสินใจที่ส่งผลต่อความปลอดภัยของผู้ใช้อย่าง Self-Driving Car การตัดสินใจบางอย่างที่นำมาซึ่งความผิดพลาดและอาจทำให้เกิดการสูญเสียทรัพย์สิน หรืออาจถึงขั้นเสียชีวิต การอธิบายได้ว่าระบบตัดสินใจอะไร เพราะอะไร ช่วยเพิ่มความมั่นใจของผู้ใช้ระบบ เพราะจะทำให้มั่นใจได้ว่าการตัดสินใจต่าง ๆ นั้นอยู่บนหลักการและเหตุผลที่ถูกต้อง และมีส่วนสำคัญอย่างมากเมื่อต้องสืบหาสาเหตุของอุบัติเหตุที่อาจเกิดขึ้นอย่างไม่คาดคิด
ปัญหาทั้งหมดที่เล่ามาทำให้การใช้งานปัญญาประดิษฐ์ในชีวิตจริงยังไม่แพร่หลายเท่ากับการที่นักวิเคราะห์เทรนด์ของอนาคตบอกไว้ นักวิจัยยังคงต้องใช้เวลาอีกสักพักเพื่อที่จะเข้าใจการทำงานของมันให้มากขึ้น และนำเสนอวิธีการที่จะทำให้ได้ผลลัพธ์ตามที่ต้องการ ซึ่งวิธีการนั้นอาจนำมาซึ่งการใช้ทรัพยากรมนุษย์ในการพัฒนาปัญญาประดิษฐ์ที่มากขึ้น หรือทรัพยากรคอมพิวเตอร์เพื่อการประมวลผล ซึ่งอาจต้องใช้เงินจำนวนมหาศาลในการเอาชนะปัญหาเหล่านี้
ผู้เขียนในฐานะอดีตนักวิจัยก็ยังติดตาม เอาใจช่วย และคาดหวังให้เทคโนโลยีปัญญาประดิษฐ์นั้นก้าวหน้าขึ้นในทุกวัน ด้วยความเชื่อที่ว่ามันจะมาช่วยทำให้ชีวิตมนุษย์ดีขึ้นได้ในอนาคต
เนื้อหาโดย อิงครัต เตชะภาณุรักษ์
ตรวจทานและปรับปรุงโดย พีรดล สามะศิริ

Engkarat Techapanurak, PhD
Senior Data Scientist at DataX
Senior Project Manager & Data Scientist
at Big Data Institute (Public Organization), BDI








