ปัจจุบันมีนักวิจัยและนักประดิษฐ์มากมายทำงานกันอย่างหนักเพื่อสร้างผลงานวิจัยและสิ่งประดิษฐ์ใหม่ๆ หลายครั้งผลงานเหล่านี้หากเป็นผลงานใหม่ที่ไม่เคยมีมาก่อน สามารถนำไปสู่การขอสิทธิบัตร (Patent) ได้ โดยสิทธิบัตรนั้นถือเป็นเครื่องแสดงทรัพย์สินทางปัญญารูปแบบหนึ่งที่ให้ความคุ้มครองการประดิษฐ์ ไม่ให้ผู้อื่นใดทำการลอกเลียนหรือจำหน่ายสิ่งประดิษฐ์นั้นๆ หากยังอยู่ในระยะเวลาการคุ้มครอง
กรมทรัพย์สินทางปัญญา นำโดย กองสิทธิบัตร เป็นหน่วยงานหลักที่มีภารกิจในการกำกับและให้บริการจดทะเบียนสิทธิบัตร โดยมีการตรวจสอบคำขอรับสิทธิบัตรที่ยื่นเข้ามาใหม่ว่ามีความซ้ำซ้อนหรือใกล้เคียงกับผลงานหรือสิ่งประดิษฐ์ที่มีมาก่อนหน้านี้หรือไม่ ซึ่งกระบวนการตรวจสอบนี้อาจต้องใช้เจ้าหน้าที่ที่มีประสบการณ์ในการแยกความแตกต่างของรายละเอียดการประดิษฐ์ รวมถึงอาจต้องใช้เวลาในการอ่านค่อนข้างมาก
กระบวนการตรวจสอบคำขอรับสิทธิบัตรแบบเดิม
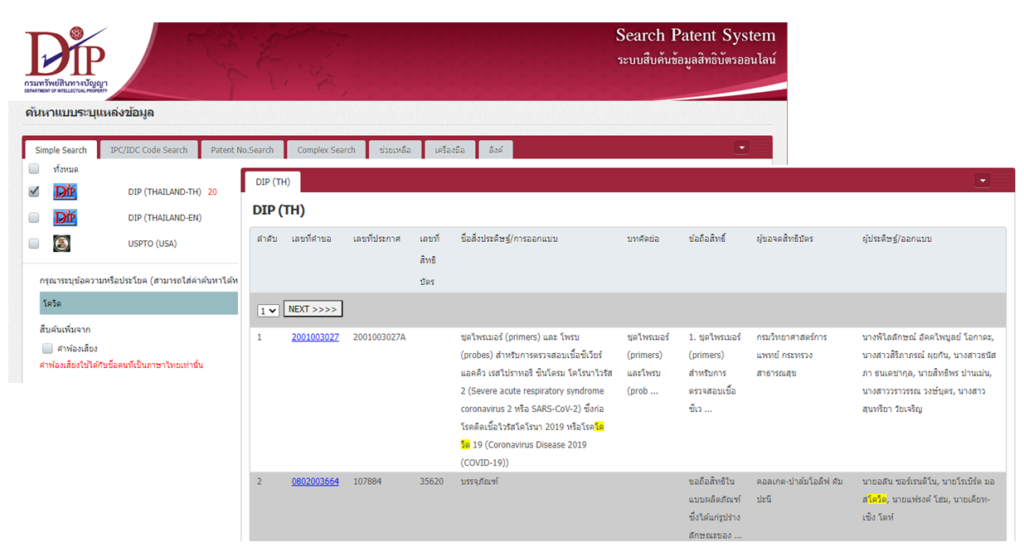
เดิมทีนั้นการตรวจสอบคำขอรับสิทธิบัตรสามารถทำได้โดยผ่านการสืบค้นด้วยคำค้นหาผ่านระบบสืบค้นข้อมูลสิทธิบัตรออนไลน์ (Search Patent System) หรือเว็บไซต์สืบค้นข้อมูลสิทธิบัตรสากลอื่นๆ ซึ่งวิธีการเหล่านี้มีข้อจำกัดในการค้นหา เนื่องจากรายการคำขอรับสิทธิบัตรที่ถูกเลือกมานำเสนอจะเป็นรายการที่จำเป็นต้องมีข้อความที่ตรงกับข้อความค้นหาอยู่ภายในรายละเอียดของคำขอนั้นในลักษณะที่ต้องตรงตามทุกตัวอักษร นอกจากนี้การค้นหาด้วยวิธีนี้จะไม่สามารถค้นหาข้อความหรือคำขอที่มีความใกล้เคียงเชิงบริบทได้ เช่น ในการค้นหาด้วยคำว่า “โควิด” นั้น คำขอรับสิทธิบัตรที่มีคำว่า “ไวรัสโคโรนา” หรือคำอื่นๆที่เกี่ยวข้อง ก็จะไม่ถูกนำเสนอขึ้นมาในผลลัพธ์ เนื่องจากในรายละเอียดไม่มีคำที่ตรงกับคำค้นหา
ด้วยเหตุนี้จึงได้มีแนวคิดในการพัฒนาเครื่องมือที่จะมาช่วยคัดกรองคำขอรับสิทธิบัตรที่มีความคล้ายกันเพื่อแก้ไขข้อจำกัดที่กล่าวมาข้างต้น โดยเครื่องมือนี้มีจุดประสงค์เพื่อช่วยสนับสนุนให้ขั้นตอนการพิจารณาคำขอรับสิทธิบัตรสามารถทำได้สะดวก รวดเร็ว และมีประสิทธิภาพมากขึ้น ผลที่ได้จากเครื่องมือนี้จะเป็นรายการคำขอสิทธิบัตรที่มีเนื้อหาคล้ายคลึงกับคำขอสิทธิบัตรที่สนใจมากที่สุดเรียงลำดับจากมากไปน้อยเพื่อนำเสนอประกอบการตัดสินใจของผู้ตรวจสอบ
กระบวนการใหม่ที่มีการประยุกต์ใช้เทคนิคการประมวลผลภาษา (Natural Language Processing)
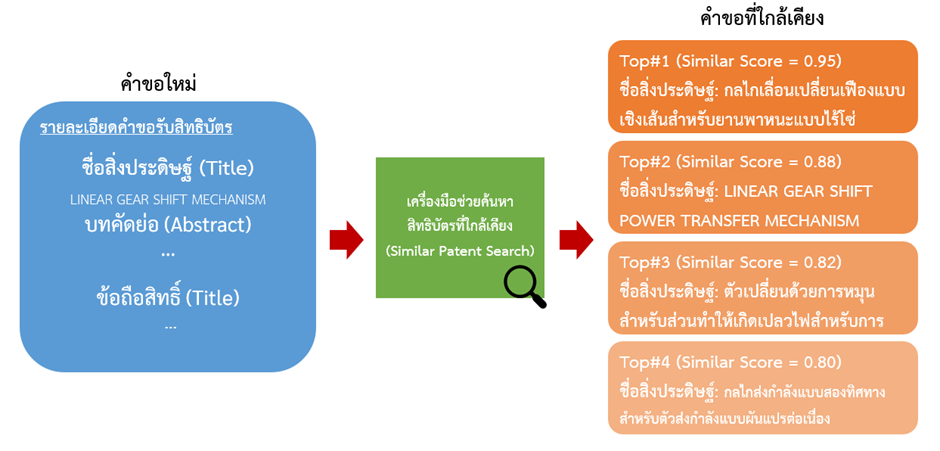
ในปี 2564 ที่ผ่านมา สถาบันส่งเสริมการวิเคราะห์และบริหารข้อมูลขนาดใหญ่ภาครัฐ (GBDi) ได้มีความร่วมมือกับ กองสิทธิบัตร ภายใต้กรมทรัพย์สินทางปัญญา ในการนำข้อมูลคำขอรับสิทธิบัตรที่มีการรวบรวมไว้มาทำการศึกษาและพัฒนาแบบจำลองสำหรับช่วยค้นหาคำขอรับสิทธิบัตรที่ใกล้เคียงกัน โดยการศึกษาในครั้งนี้ได้มีการประยุกต์ใช้เทคนิคการประมวลผลภาษา (Natural Language Processing: NLP) ในการวิเคราะห์ความใกล้เคียง (Similarity Matching) ของเนื้อหาและบริบทของคำที่เกิดขึ้นในรายละเอียดเอกสารคำขอรับสิทธิบัตรกับฐานข้อมูลสิทธิบัตรที่มีอยู่ โดยข้อมูลรายละเอียดที่นำมาใช้ในการพิจารณาประกอบไปด้วย ชื่อการประดิษฐ์ (Title) บทคัดย่อ (Abstract) และ ข้อถือสิทธิ (Claims) ซึ่งข้อมูลเหล่านี้เป็นข้อมูลประเภทข้อความ (text) ในข้อมูลจะมีข้อความบางส่วนไม่ได้เป็นเนื้อหาหลักของเอกสาร เราจึงต้องมีการทำความสะอาดข้อมูลเหล่านี้ก่อน เช่น การจัดการอักขระพิเศษ การจัดการคำที่ไม่มีนัยสำคัญกับความหมาย (stop words) และอื่นๆ ก่อนนำไปเข้าสู่กระบวนการตัดคำ (word tokenization)
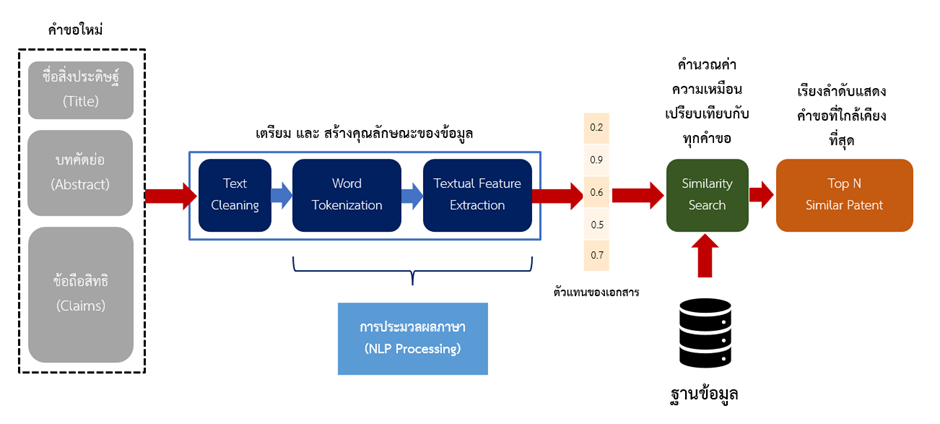
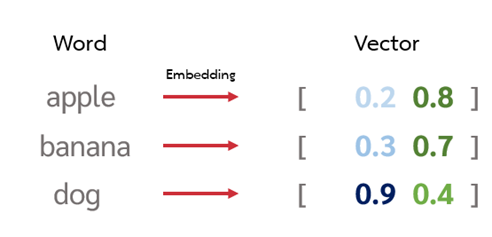
หลังจากนั้นจะเป็นขั้นตอนของการสร้างเวกเตอร์ตัวแทนของเอกสาร ด้วยเหตุผลที่ว่าข้อมูลที่ใช้มีรูปแบบเป็นข้อความ (text) ทำให้เราไม่สามารถนำมาเปรียบกันได้โดยตรงว่ามีความคล้ายคลึงกันมากน้อยเท่าใด จึงจำเป็นต้องแปลงข้อมูลเอกสารที่มีรูปแบบเป็นข้อความให้เป็นตัวเลขที่สามารถนำมาเปรียบเทียบได้ก่อน ผลลัพธ์จากขั้นตอนนี้จะได้ออกมาเป็นลำดับของตัวเลขที่แสดงถึงคุณลักษณะของเอกสารนั้นๆ ว่ามีเนื้อหาที่เกี่ยวข้องในเรื่องต่างๆ มากน้อยเพียงใด โดยวิธีการที่ใช้ในการสร้างเวกเตอร์ตัวแทนเอกสารจะประยุกต์ใช้การสร้างเวกเตอร์ด้วยการพิจารณาคุณลักษณะเชิงบริบทของคำ ซึ่งได้มาจากการเฉลี่ยของเวกเตอร์ตัวแทนของคำทุกคำที่เกิดขึ้นในเอกสารนั้นๆ เทคนิคในการสร้างเวกเตอร์ตัวแทนของคำนี้ จะเรียกว่าการทำ Word Embedding เป็นการแปลงคำที่เป็นตัวอักษรให้กลายเป็นเวกเตอร์ตัวแทนของคำในรูปแบบของค่าตัวเลขที่สามารถนำมาเปรียบเทียบความใกล้เคียงเชิงบริบทได้ ดังเช่นตัวอย่างด้านล่าง จะเห็นว่าคำว่า “apple” และ คำว่า “banana” จะมีค่าตัวเลขในเวกเตอร์ที่ใกล้เคียงกันมากกว่า การเปรียบเทียบ คำว่า “apple” กับ “dog” เนื่องจาก “apple” กับ “banana” มีความใกล้เคียงเชิงบริบทในแง่ของการเป็นคำที่แสดงถึงผลไม้เหมือนกัน ถ้าอยากทราบรายละเอียดเพิ่มเติมเกี่ยวการทำ Word Embedding สามารถเพิ่มเติมได้ที่บทความ การค้นหาตัวแทนเชิงความหมายของข้อความ: Word2Vec Word Embedding, Part I
ลำดับถัดไปคือการคำนวณค่าความเหมือนของเอกสาร โดยการนำเวกเตอร์ตัวแทนเอกสารของคำขอใหม่มาเปรียบเทียบกับเวกเตอร์ตัวแทนเอกสารของคำขอทั้งหมดที่มีในฐานข้อมูล และทำการเรียงลำดับคำขอที่มีความใกล้เคียงกับคำขอใหม่ที่ต้องการตรวจสอบมากที่สุด เพื่อแสดงให้ผู้ตรวจสอบทำการพิจารณาในรายละเอียดอีกครั้ง โดยผลสุดท้ายทาง GBDi ได้ทำการพัฒนาเครื่องมือต้นแบบ (Prototype) ให้กับทางกองสิทธิบัตรได้ทดลองใช้งานเพื่อดูผลลัพธ์การแสดงรายการคำขอที่ใกล้เคียงที่ได้จากการค้นหา โดยเรียงลำดับตามค่าคะแนนความเหมือน เครื่องมือนี้จะมีประโยชน์ต่อเจ้าหน้าที่ตรวจสอบคำขอรับสิทธิบัตรซึ่งช่วยลดภาระงานในการสืบค้นและอ่านคำขอรับสิทธิบัตรจำนวนมาก ทำให้เจ้าหน้าที่สามารถทำงานได้อย่างมีประสิทธิภาพมากยิ่งขึ้น
สำหรับความร่วมมือในการพัฒนาเครื่องมือต้นแบบในการค้นหาเอกสารคำขอรับสิทธิบัตรที่ใกล้เคียงกันของทางกองสิทธิบัตร กรมทรัพย์สินทางปัญญา และ GBDi ในครั้งนี้ นับว่าเป็นตัวอย่างที่แสดงให้เห็นถึงการนำข้อมูลที่มีอยู่มาใช้ประโยชน์เพื่อพัฒนาประสิทธิภาพการดำเนินงานของหน่วยงานให้สามารถทำงานได้อย่างสะดวก รวดเร็ว และตอบโจทย์การให้บริการประชาชนมากยิ่งขึ้น และหวังว่าตัวอย่างนี้จะเป็นประโยชน์แนวทางให้กับหน่วยงานอื่นๆ ในการส่งเสริมการใช้ประโยชน์ข้อมูลที่มีอยู่ภายในหน่วยงานต่อไปในอนาคต
เนื้อหาโดย กัญญาวีร์ พรสว่างดี
ตรวจทานและปรับปรุงโดย นววิทย์ พงศ์อนันต์
Project Manager & Data Scientist
Big Data Institute (Public Organization), BDI