
โดยทั่วไปแล้วเมื่อกล่าวถึง Machine Learning พวกเรามักนึกไปถึงการนำเอาข้อมูลจำพวกตัวเลข (numerical data) หรือข้อมูลที่เป็นหมวดหมู่ (categorical data) ซึ่งถูกจัดเก็บไว้ในฐานข้อมูลหรือถูกเก็บรวบรวมไว้แล้ว มาทำการ (1) วิเคราะห์เพื่อทำนายถึงสิ่งที่จะเกิดขึ้นในอนาคต (predictive analytics) เช่น การพยากรณ์ปริมาณน้ำฝน การทำนายราคาหุ้น การคำนวณความเป็นไปได้ที่ลูกค้าจะซื้อสินค้าตามโปรโมชั่นหรือจะยกเลิกสัญญาเครือข่ายโทรศัพท์มือถือ หรือ (2) วิเคราะห์เพื่อศึกษาและอธิบายสิ่งที่เกิดขึ้น (descriptive analytics) เช่น การจัดกลุ่มลูกค้าโดยพิจารณาจากพฤติกรรมการเลือกซื้อสินค้า (customer segmentation) เพื่อที่จะจัดโปรโมชันได้ตรงกับความต้องการของลูกค้าในแต่กลุ่ม เป็นต้น
แล้วถ้าหากว่าข้อมูลที่เรามีอยู่ ไม่ได้อยู่ในรูปแบบข้างต้น แต่เป็นรูปแบบข้อความ เช่น บทความจำนวนมาก เราจะสามารถนำมาวิเคราะห์ในลักษณะใดได้บ้าง สิ่งหนึ่งที่เราสามารถลองทำได้ คือลองหาดูว่าในบทความจำนวนมากนั้นมีหัวข้อ (topics) อะไรอยู่บ้าง ซึ่งเทคนิคที่ใช้ในการทำสิ่งนี้เรียกว่า Topic Modelling Algorithms
Topic Modelling เป็นการวิเคราะห์หาหัวข้อที่ซ่อนอยู่ภายใต้กลุ่มของบทความ ประกอบไปด้วยหลากหลายอัลกอริทึม เช่น LDA, NMF, LSI, ฯลฯ
ในบทความนี้ เราจะไม่ได้ลงลึกถึงเนื้อหา algorithm (ซึ่งจะมีบทความแยกโดยเฉพาะในภาคต่อไป) แต่จะมาเล่าถึงตัวอย่างผลการวิเคราะห์หาหัวข้อบทความจากข้อมูลจริงของภาครัฐ
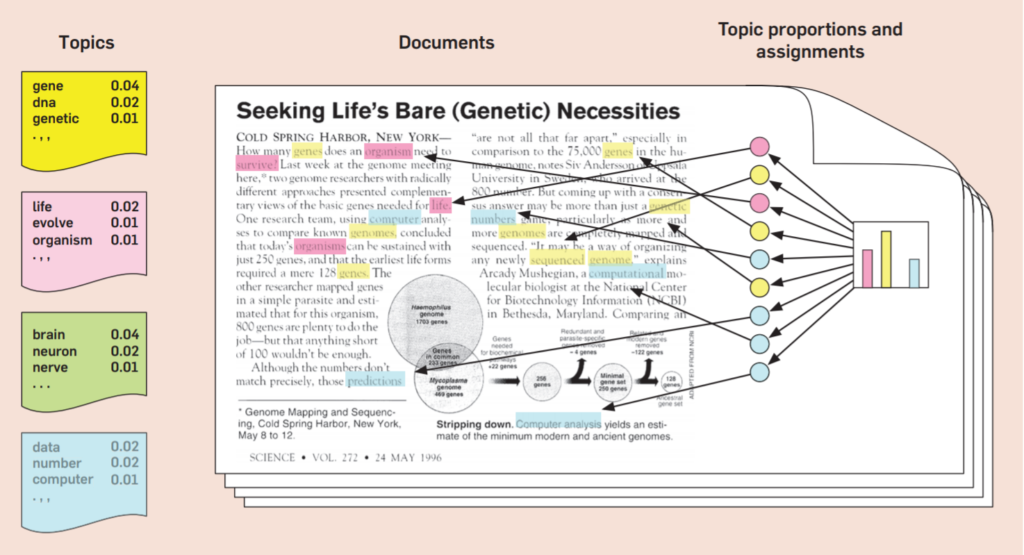
วิเคราะห์หาหัวข้องานวิจัยจากบทคัดย่อ
ในช่วงปี 2562-2563 ที่ผ่านมา Government Big Data institute (GBDi) ได้มีโอกาสร่วมมือกับสำนักงานการวิจัยแห่งชาติ (วช.) ที่มีการจัดเก็บผลงานวิจัยภายในประเทศจำนวนไม่น้อยในแต่ละปี ผลงานวิจัยเหล่านั้นถูกแยกย่อยตามสาขาวิชาหลักทั้งหมด 7 สาขา เช่น เกษตรศาสตร์ สังคมศาสตร์ วิศวกรรมและเทคโนโลยี เป็นต้น การแบ่งสาขาเหล่านี้ถูกใช้เป็นข้อมูลช่วยวางแผนนโยบายต่าง ๆ เกี่ยวกับงานวิจัย แต่เนื่องด้วยจำนวนงานวิจัยที่มากขึ้นเรื่อย ๆ ในแต่ละปี จึงเกิดความต้องการที่จะใช้ข้อมูลในระดับที่ละเอียดกว่า 7 สาขาวิชาหลัก จึงต้องนำ Topic Modelling Technique มาช่วยวิเคราะห์เพื่อหาหัวข้องานวิจัยที่ซ่อนอยู่ภายใต้แต่ละสาขาวิชา
ในการศึกษาครั้งนี้ เราได้ตัวอย่างบทคัดย่อภาษาอังกฤษที่ถูกแบ่งเป็น 7 ประเภทตามสาขาวิชาหลัก โดยข้อมูลประกอบด้วยไฟล์หลากหลายประเภท ไม่ว่าจะเป็น Microsoft word, text file, pdf และไฟล์รูปภาพ ก่อนที่จะนำข้อมูลเข้าโมเดลเพื่อทำการวิเคราะห์นั้น จึงต้องมีการจัดเตรียมบทคัดย่อที่ได้รับมาให้อยู่ในรูปแบบที่เหมาะสมก่อน

ในส่วนการจัดเตรียมข้อมูลนั้น ประกอบด้วย 2 ขั้นตอนหลัก คือ (1) ทำการอ่านตัวอักษรออกมาจากไฟล์และดึงเอาเฉพาะส่วนเนื้อหาของบทคัดย่อออกมา และ (2) ใช้เทคนิคทาง Natural Language Processing (NLP) มาจัดเตรียมเนื้อหาบทคัดย่อ โดยประกอบด้วย การแยกคำที่ติดกัน, tokenization, lemmatization, และการตัดคำที่เป็นตัวเลขหรือ stop words ออก
หลังจากนั้น บทคัดย่อที่ถูกจัดเตรียมแล้ว จะถูกนำเข้าโมเดลเพื่อวิเคราะห์หาหัวข้อ (Topic Modelling) โมเดลที่ใช้ในการวิเคราะห์หาหัวข้อนั้นมีอยู่หลายโมเดลด้วยกัน เช่น Latent Dirichlet Allocation (LDA), Non-negative Matrix Factorization (NMF), Latent Semantic Analysis (LSA) ฯลฯ ในการศึกษาครั้งนี้ LDA เป็นโมเดลที่ถูกนำมาประยุกต์ใช้ เนื่องด้วยมีการทดลอง [2] พบว่า LDA ให้ผลลัพธ์ที่ดีกว่าในกรณีข้อมูลที่เป็นประโยค (full sentence scenario) อีกทั้ง LDA ยังมี library [3] ที่มี multicore functionality LDA จึงเป็นตัวเลือกแรกที่ทำมาใช้ในการศึกษา
การวิเคราะห์หาหัวข้องานวิจัยนั้น จะทำแยกกันโดยแยกตามรายสาขา กล่าวคือ กลุ่มของบทคัดย่อในสาขาวิชาเดียวกันจะถูกส่งเข้าโมเดลวิเคราะห์เพื่อหาหัวข้องานวิจัยภายในสาขานั้น ระบบจะทำงานเช่นนี้ซ้ำทั้งหมด 7 ครั้งสำหรับ 7 สาขาวิชา
ตัวอย่างผลวิเคราะห์หาหัวข้องานวิจัย
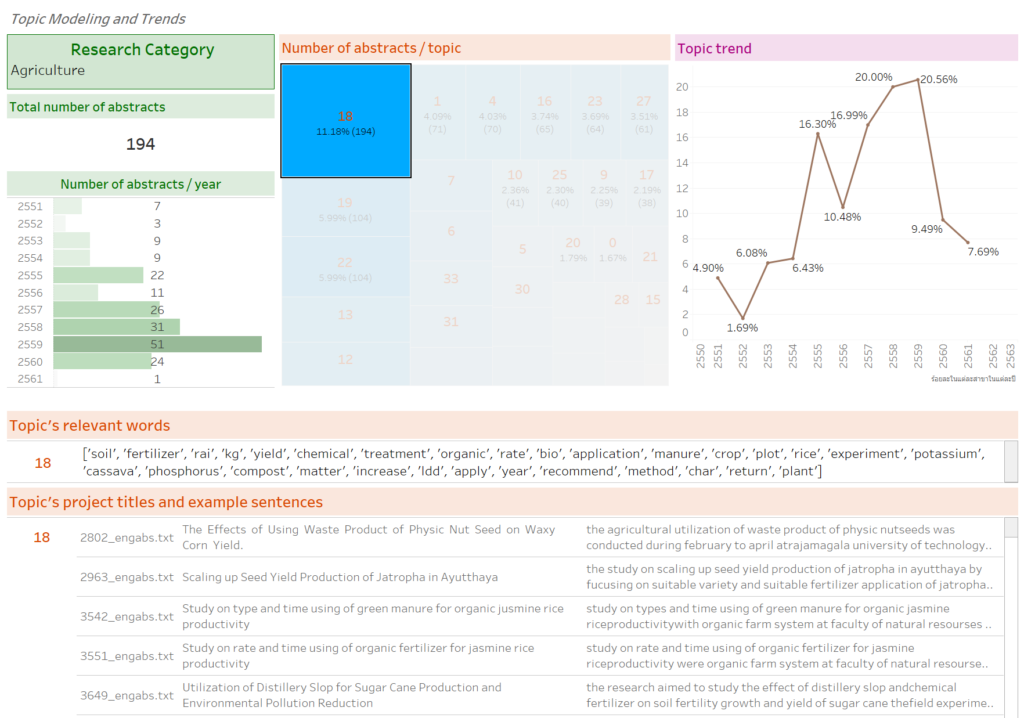
ผลลัพธ์หัวข้อที่ได้จาก LDA model นั้น แต่ละหัวข้อจะถูกแสดงด้วยกลุ่มคำสำคัญของหัวข้อ ซึ่งผู้ดูแลข้อมูลผลงานวิจัย ต้องเป็นผู้ตีความหมายร่วมกับผู้เชี่ยวชาญในด้านนั้น ๆ ว่าหัวข้อนั้นเกี่ยวข้องกับเรื่องอะไร ภายในรูปภาพแสดงตัวอย่างการนำเอาผลลัพธ์จากโมเดลมาแสดงผลบน dashboard เพื่ออำนวยความสะดวกในการแปลผล

ในหัวข้อที่ 18 ของสาขาเกษตรศาสตร์มีคำสำคัญ เช่น soil, fertilizer, yield, chemical, treatment, และ bio เมื่อนำเอาคำสำคัญเหล่านั้นมาสร้างเป็นแผนภาพที่เรียกว่า word cloud และตรวจดูคำสำคัญประกอบกับรายชื่อโครงการวิจัย จะพบว่าหัวข้อที่ 18 นี้ เกี่ยวกับการพัฒนาที่ดิน ซึ่งสอดคล้องกับคำสำคัญ อาทิ soil treatment, chemical fertilizer, และ bio fertilizer การตีความหมายของหัวข้อที่เหลือก็สามารถกระทำในลักษณะเช่นเดียวกัน

ลองมาดูอีกตัวอย่างจากสาขาสังคมศาสตร์ ในหัวข้อประกอบด้วยคำสำคัญ เช่น school, learn, teacher, และ development เมื่อนำเอาคำสำคัญเหล่านั้นมาสร้างเป็นแผนภาพที่เรียกว่า word cloud และตรวจสอบคำสำคัญร่วมกับรายชื่อโครงการ พบว่าเป็นหัวข้อที่เกี่ยวกับการพัฒนาด้านการศึกษา เช่น การพัฒนาหลักสูตร แพลตฟอร์มการสอนออนไลน์ และทักษะการคิดเชิงวิพากษ์ (critical thinking) ของผู้บริหารโรงเรียน เป็นต้น
ผลลัพธ์หัวข้อที่ได้จากการทำ model นั้น แต่ละหัวข้อจะถูกแสดงด้วยกลุ่มคำสำคัญของหัวข้อ ซึ่งผู้ดูแลข้อมูลผลงานวิจัย ต้องเป็นผู้ตีความหมายร่วมกับผู้เชี่ยวชาญในด้านนั้น ๆ ว่าหัวข้อนั้นเกี่ยวข้องกับเรื่องอะไร
ต่อยอดจากโมเดล
หลังจากที่เราค้นพบหัวข้องานวิจัยที่ซ่อนอยู่ภายใต้สาขาวิชาต่าง ๆ แล้ว ข้อมูลเหล่านี้สามารถนำไปช่วยในการวางแผนนนโยบายเกี่ยวกับงานวิจัย เช่น หาหัวข้องานวิจัยที่กำลังเป็นที่นิยม ซึ่งอาจจะเพิ่มกระบวนการตรวจสอบที่เข้มงวดขึ้นในการให้ทุน หรือดูแนวโน้มของการวิจัยในหัวข้อต่าง ๆ ซึ่งอาจจะหาทางกระตุ้นกลุ่มหัวข้องานวิจัยที่ไม่เป็นที่นิยมแต่ต้องการสนับสนุน เป็นต้น
References
[1] Probabilistic Topic Models https://mimno.infosci.cornell.edu/info6150/readings/Blei2012.pdf
[2] เปรียบเทียบระหว่าง LDA และ NMF https://hal.archives-ouvertes.fr/hal-01370853/document
[3] Gensim’s LDA model https://radimrehurek.com/gensim/models/ldamodel.html





