

ในช่วงที่มีการระบาดของโรคโควิด-19 นี้ เราอาจจะได้เห็นหลาย ๆ คนได้ลองพยายามนำข้อมูลของผู้ป่วยที่เพิ่มขึ้นทุก ๆ วันมาพยากรณ์ว่ามันจะมีแนวโน้มไปในทิศทางไหน โมเดลที่นิยมนำมาใช้ก็คือ SEIR model (ลองอ่าน การจำลองสถานการณ์ COVID-19 ผ่านตัวแบบเชิงคณิตศาสตร์) ที่สามารถอธิบายการระบาดโดยใช้สมการอนุพันธ์ต่าง ๆ แต่พอเข้าไปอ่านดูแล้วพวกเราบางคนอาจจะคิดในใจว่า ทำไมมันยากอย่างนี้!! ? วันนี้ผมจึงเอาอีกเทคนิคที่ง่ายขึ้นและซับซ้อนน้อยลงมานำเสนอนั่นก็คือการ fit curve แบบง่าย ๆ เลย (คำเตือน: วิธีนี้ไม่ใช่วิธีที่เหมาะสมที่สุดสำหรับการพยากรณ์โรคระบาด ผลจากการพยากรณ์ด้วยวิธีนี้อาจป็นไม่ตรงกับความเป็นจริง)
มารู้จักกับ library Scipy
SciPy (อ่านว่า ไซ-พาย) เป็น library ที่ใช้ใน python สำหรับการคำนวณทางวิทยาศาสตร์ ซึ่งมีฟังก์ชันหลากหลายไม่ว่าจะเป็น linear algebra, calculus หรือ optimization ทุกคนอาจจะได้เคยใช้ NumPy มาก่อน SciPy สามารถนำมาใช้ควบคู่และเติมเต็ม NumPy ได้อย่างดีเยี่ยม
ฟังก์ชัน curve_fit จาก SciPy
สำหรับบทความนี้ ฟังก์ชันที่เราจะใช้กันก็คือ curve_fit จาก library scipy.optimize ที่สามารถใช้ในการปรับสมการให้เข้ากับข้อมูลที่เรามีมากที่สุด โดยเราจะต้องกำหนดหน้าตาของสมการตัวนั้นมาก่อน แล้วฟังก์ชัน curve_fit จะพยายามหาค่า parameter ที่จะทำให้สมการของเรานั้นใกล้เคียงกับข้อมูลจริงที่สุด อ่านถึงตรงนี้อาจจะยังไม่เข้าใจ มาเริ่มจากการลองใช้เลยดีกว่า
เริ่มต้นจากการ import library เราจะใช้ matplotlib มาสำหรับการสร้างกราฟและ SciPy ในการ fit curve
import numpy as np
import matplotlib.pyplot as plt
from scipy.optimize import curve_fit สมมติฟังก์ชันขึ้นมาตัวนึงสำหรับสมการที่จะใช้ เป็นสมการเอกซ์โพเนนเชียล (Exponential): [math]f(x)=ae^{-bx}+c[/math] ที่มี parameter ที่ไม่รู้ค่าคือ a, b และ c โดยใช้ฟังก์ชัน np.exp จาก NumPy
def func(x, a, b, c):
return a * np.exp(-b * x) + cเรายังไม่มีข้อมูลจริงมาใช้ ดังนั้นเราก็สร้างมันขึ้นมาก่อน โดยตั้งให้ คือ a = 2.5, b = 1.3 และ c = 0.5 แต่ใส่ noise ขึ้นมาเพื่อให้ข้อมูลกระจัดกระจาย
xdata = np.linspace(0, 4, 50)
y = func(xdata, 2.5, 1.3, 0.5)
np.random.seed(1729)
y_noise = 0.2 * np.random.normal(size=xdata.size)
ydata = y + y_noise
plt.scatter(xdata, ydata, s = 2) 
พอเรามีตัวฟังก์ชันและข้อมูลแล้ว ก็สามารถเรียก curve_fit ได้
popt, pcov = curve_fit(func, xdata, ydata)output ของ curve_fit นั้นมีสองตัวคือ
poptเป็นค่าที่ดีที่สุดสำหรับ parameter จากสมการของเราpcovเป็นค่าทางสถิติที่บอกถึงการกระจายตัวของข้อมูลและความคลาดเคลื่อนของค่า parameter ที่หามาได้
เราจะสนใจแค่ popt ซึ่งจะบอกค่า a, b และ c ที่เราหามาได้ และ นำมาสร้างกราฟเทียบกับข้อมูลจริง
plt.scatter(xdata, ydata, label='data', s = 2)
plt.plot(xdata, func(xdata, *popt), 'r-',
label='fit: a=%5.3f, b=%5.3f, c=%5.3f' % tuple(popt))
plt.legend() 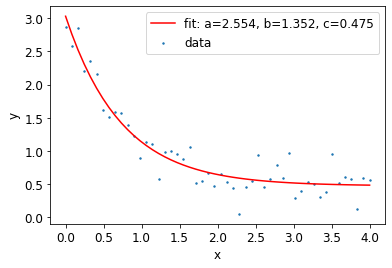
เท่านี้เราก็ได้สมการและเส้นโค้งสำหรับข้อมูลที่มีและเราก็ยังสามารถใช้พยากรณ์ข้อมูลต่อไปได้อีกด้วย

อย่างไรก็ตามข้อจำกัดของ curve_fit ก็คือเราต้องรู้รูปแบบของสมการที่จะใช้ก่อน ไม่งั้นจะไม่สามารถทำอะไรได้ แต่ข้อดีคือรูปแบบของสมการนั้นเป็นอะไรก็ได้ที่เป็นฟังก์ชันทางคณิตศาสตร์ที่สามารถเขียนเป็นฟังก์ชันใน python ได้ และจะมี parameter กี่ตัวก็ได้
พยากรณ์การระบาดของโรคในประเทศเกาหลี
ทีนี้ลองมาดูกันว่าเรากันว่าเราจะใช้ฟังก์ชันนี้มาช่วยในการพยากรณ์การระบาดของโรคได้อย่างไร ก่อนอื่นเราต้องรู้ก่อนว่าข้อมูลที่เราจะพยากรณ์หน้าตาเป็นอย่างไร และควรจะสมการรูปแบบไหนมาอธิบายข้อมูลพวกนี้
เราจะใช้ข้อมูลผู้ป่วยในประเทศเกาหลีใต้จาก ชุดข้อมูลบน github โดยเราจะใช้ข้อมูลในช่วงเดือนกุมภาพันธ์มาใช้ในการคำนวนและนำมาพยากรณ์การระบาดในเดือนมีนาคม
สำหรับรูปแบบของสมการนั้นโดยปกติแล้วหากเราดูกรณีศึกษาของการระบาดโรคนั้นจะเห็นว่าจำนวนผู้ป่วยในข่วงแรกจะเพิ่มขึ้นแบบเอกซ์โพเนนเชียล (Exponential) ก่อนที่จะชะลอตัวเพิ่มขึ้นช้าลงจนหยุดเพิ่มขึ้นในที่สุด ลักษณะของกราฟแบบนี้มีชื่อเรียกว่าซิกมอยด์ (Sigmoid)
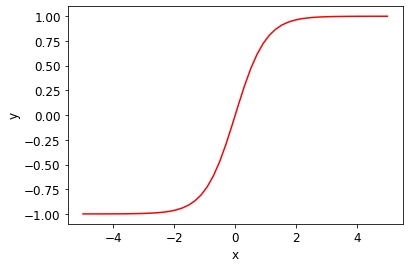
มีสมการหลายสมการที่มีลักษณะแบบซิกมอยด์ ไม่ว่าจะเป็น
- สมการ logistic : [math]f(x) = \frac{1}{1+e^{-x}}[/math]
- สมการ tanh: [math]f(x) = \tanh(x) = \frac{e^{x} – e^{-x}}{e^{x}+e^{-x}}[/math]
- สมการ arctan: [math]f(x) = \tan^{-1}(x)[/math]
- สมการ error: [math]f(x) = \textrm{erf}(x) = \frac{2}{\sqrt{\pi}} \int_0^x e^{{-t}^2}dt[/math]
- หรือ สมการพีชคณิตทั่วไปอย่าง [math]f(x) = \frac{x}{\sqrt{1+x^2}}[/math]
สำหรับบทความนี้ผมจะใช้สมการ [math]textrm{erf}(x)[/math] เนื่องจากมีอยู่ใน library scipy.special สามารถเรียก scipy.special.erf มาใช้ได้เลย โดยฟังก์ชันที่ผมใช้มีหน้าตาแบบนี้
def func(x, a, b, c):
return a*(1+scipy.special.erf((x-m)/s))
จากนั้นจึงใช้ฟังก์ชัน curve_fit เพื่อหาค่า parameter a, b และ c เพื่อที่จะ match กับข้อมูลที่ใช้ ซึ่งได้ผลออกมาตามภาพ
เมื่อเราได้ตัวสมการของเราออกมาแล้วเรากฎนำมาพยากรณ์ดูซิว่าถ้าเทียบกับข้อมูลจริงแล้วจะแม่นยำแค่ไหน (สีเขียวคือข้อมูลช่วงเดือนกุมภาพันธ์นำมาใช้คำนวณ สีแดงข้อมูลจริงในช่วงเดือนมีนาคมที่เอามาใช้เทียบ)
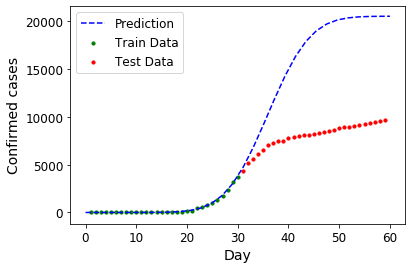
จะเห็นได้ว่าสมการของเราสามารถฟิตกับข้อมูลช่วงแรกที่นำมาคำนวณได้ดีมาก แต่หลังจากนั้นการทำนายก็ไม่ได้แม่นยำสักทีเดียว ซึ่งเกิดจาก
- สมมติฐานของสมการที่เราใช้ เส้นโค้งซิกมอยด์อาจจะไม่ได้เหมาะสมหรือแม่นยำ อย่างในกรณีของประเทศเกาหลีจะเห็นว่าช่วงหลังจำนวนผู้ป่วยเพิ่มขึ้นแบบเป็นเส้นตรง ซึ่งจะต่างจากโค้งซิกมอยด์
- การเปลี่ยนแปลงของการกักกันโรค เมื่อมีการเปลี่ยนแปลงมาตรการต่าง ๆ นั่นหมายความว่าสมการที่จะใช้อธิบาย อาจจะเปลี่ยนไปด้วย ทำให้การใช้สมการเดียวสำหรับทุกสถานการณ์นั้นอาจไม่ถูกต้อง
- การตรวจโรค จำนวนผู้ป่วยที่รายงานอาจจะไม่เท่ากับจำนวนผู้ป่วยที่แท้จริง แต่เป็นจำนวนผู้ป่วยที่ตรวจเจอโรค ดังนั้นตัวเลขผู้ป่วยที่เพิ่มขึ้นในแต่ละวัน อาจจะขึ้นกับความสามารถในการตรวจโรคของประเทศนั้นด้วย
พยากรณ์การระบาดของโรคในประเทศไทย
เมื่อได้ลองของเกาหลีแล้ว เรามาลองของประเทศไทยกันบ้าง โดยจะเริ่มใช้ข้อมูลหลังจากที่มีผู้ป่วยมากกว่า 100 คน (15 มีนาคม 2563) เพราะการระบาดเริ่มแพร่ในวงกว้าง โดยผมจะลองใช้ทั้งสมการซิกมอยด์และเอกซ์โพเนนเชียล เพราะสถานการณ์การระบาดในไทยยังอยู่ในช่วงเริ่มต้นอยู่ดังนั้นตัวเส้นกราฟอาจจะใช้เอกซ์โพเนนเชียลได้ถ้าดูในระยะสั้น ๆ


จะเห็นได้ว่าในสองกรณีผลที่ได้ค่อนข้างแตกต่างกันมากทีเดียว นั่นเป็นเพราะว่าสมการที่เราใช้เป็นสมมติฐานนั้นส่งผลอย่างมากผลการวิเคราะห์ ซึ่งก็อาจจะเป็นจุดอ่อนของการใช้วิธีนี้ในการพยากรณ์ตัวเลขผู้ป่วยเพราะเราไม่รู้ว่าสมการที่ใช้ควรมีหน้าตาอย่างไร ต้องเอาเองโดยดูจากการระบาดในอดีตซึ่งก็อาจจะแตกต่างกับการระบาดในปัจจุบัน วิธีการที่มีที่มาที่ไปมากกว่าอย่างเช่น SEIR model ซึ่งสามารถทำนายจำนวนผู้ป่วยตามหลักระบาดวิทยาจึงมักจะเป็นที่นิยมใช้มากกว่าครับ
สรุปได้ว่าการใช้ curve_fit ก็เป็นอีกทางเลือกที่ดี ในการหาสมการที่จะมาอธิบายข้อมูลของเราเพราะทำได้ง่าย และอาจจะสามารถใช้พยากรณ์แนวโน้มของข้อมูลในอนาคตแบบรวดเร็วอีกด้วย









