ในบทความนี้ ผมจะมาพาผู้อ่านทุกท่านทำความรู้จักกับ Box Plot แผนภาพอันทรงพลังที่ใช้ในการวิเคราะห์การกระจายตัวของข้อมูล บอกได้เลยว่าสามารถใช้วิเคราะห์ได้ดีไม่แพ้ Histogram เลยครับ!
การวิเคราะห์การกระจายตัวของข้อมูล
คำถามที่เกี่ยวข้องกับการวิเคราะห์การกระจายตัวของข้อมูล มีอยู่ในชีวิตประจำวันของเราทุกคน ยกตัวอย่างเช่น
- “ความเข้มข้นของสารเคมีในดินบริเวณนี้ มีการกระจายตัวอย่างไร?”
- “จำนวนชั่วโมงการนอนทุกคืนของเรา ส่วนใหญ่มีค่าเท่าไหร่?”
- “รายได้ส่วนใหญ่ของประชากรมีการเบ้ซ้ายหรือขวาไหม?”
- “คะแนนที่นักเรียนสอบได้จากการสอบ มีค่าสุดโต่งไหม? เท่าไหร่?”
ซึ่งหลาย ๆ คน จะคุ้นเคยกับการตอบคำถามด้านบนด้วย Histogram ซึ่งก็ถือว่าเป็นตัวเลือก “คลาสสิก” เพราะทุกคนจะเคยเรียนรู้สิ่งนี้มาก่อนในวิชาคณิตศาสตร์ โดย Histogram เป็นการนำข้อมูลเชิงปริมาณ (Numerical Data) มา “นับจำนวนครั้ง” ที่พบค่าของข้อมูล ตามช่วงข้อมูลหรืออันตรภาคชั้น (Bins) และเมื่อเราสร้าง Histogram แล้ว เราสามารถตอบคำถามด้านบนได้หลากหลาย เช่น
- หากเราต้องการรู้ว่าข้อมูลส่วนใหญ่อยู่ช่วงไหน เพียงดูบริเวณที่ “ภูเขาสูง” แล้วก็เอาช่วงค่าในแกนนอนมาตอบ
- หากเราต้องการดูการเบ้ซ้ายหรือขวา ให้ใช้หลักการที่ว่า หาก “ภูเขา” อยู่ค่อนไปทางขวาของช่วงข้อมูลทั้งหมด เราก็ตอบได้ทันทีว่า ข้อมูลมีการกระจายตัวแบบเบ้ซ้าย (Left Skewed Distribution) แล้วก็กลับกันสำหรับเบ้ขวา (Right Skewed Distribution)
- หากเราต้องการเห็นค่าสุดโต่ง ก็ดูบริเวณที่มีข้อมูลปรากฏห่างไกลข้อมูลส่วนใหญ่ แล้วมีความถี่เกิดขึ้นน้อย (ซึ่งบางครั้งอาจสังเกตได้ยาก)
บทความนี้จะขอนำเสนอ 4 เหตุผลที่จะทำให้ผู้อ่านตกหลุมรัก Box Plot โดยจะมีการอธิบายรายละเอียดวิธีการทำงานของ Box Plot ภายในเนื้อหาด้วย เริ่มต้นที่เหตุผลข้อที่หนึ่งในส่วนถัดไปกันเลยครับ ?
เหตุผลข้อ 1: Box Plot ประหยัดพื้นที่
ในยุคดิจิทัลทุกวันนี้ Business Intelligence, Visual Analytics, และ Data Visualization ได้เข้ามามีบทบาทในองค์กรต่าง ๆ ทั้งเรื่องการบริหารจัดการ การดูสถานะ การวางแผน และการตัดสินใจ ทำให้พื้นที่บนหน้าจออุปกรณ์พกพาต่าง ๆ ของเรากลายเป็น Real Estate ยุคใหม่ แน่นอนว่า การนำเสนอข้อมูลอะไรที่ใช้เนื้อที่เยอะเกินไป ดูจะไม่ค่อยคุ้มเสียแล้ว
ซึ่งในการแสดงข้อมูลชุดเดียวกัน Box Plot สามารถย่อส่วนพื้นที่ที่จำเป็นต่อการแสดงข้อมูลจากแผนภาพสองมิติ (2D) เหลือเพียงมิติเดียว (1D) ทำให้เป็นแผนภาพที่เหมาะกับยุคดิจิทัลที่พื้นที่บนหน้าจอของเรามีจำกัด
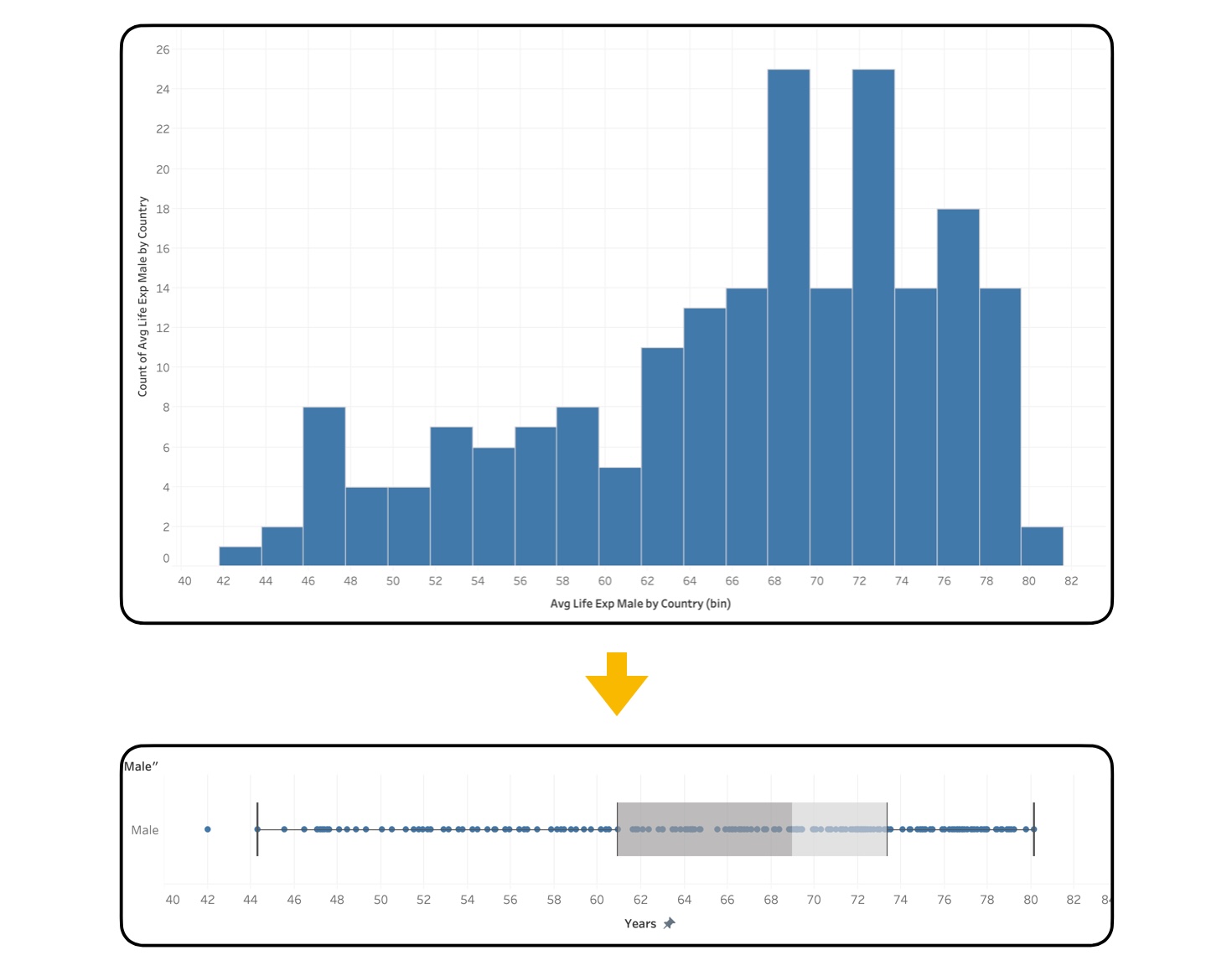
แต่ Box Plot ที่ถูกย่อส่วนลงมาแล้ว จะยังตอบคำถามหลาย ๆ คำถามได้เหมือน Histogram หรือไม่? เรามาดูเหตุผลข้อถัดไปกันครับ
เหตุผลข้อ 2: Box Plot อัดแน่นไปด้วยข้อมูล
แผนภาพ Box Plot ได้ชดเชยขนาดที่เล็ก ด้วยหลักการวาดส่วนสำคัญต่าง ๆ ของกล่องด้วยปริมาณที่สำคัญทางสถิติ ทำให้ Box Plot ยังคงให้ข้อมูลและข้อสังเกตได้หลากหลายประการ แต่ก่อนอื่นเราลองมาทำความรู้จักกับส่วนประกอบต่าง ๆ ของ Box Plot กันก่อนครับ
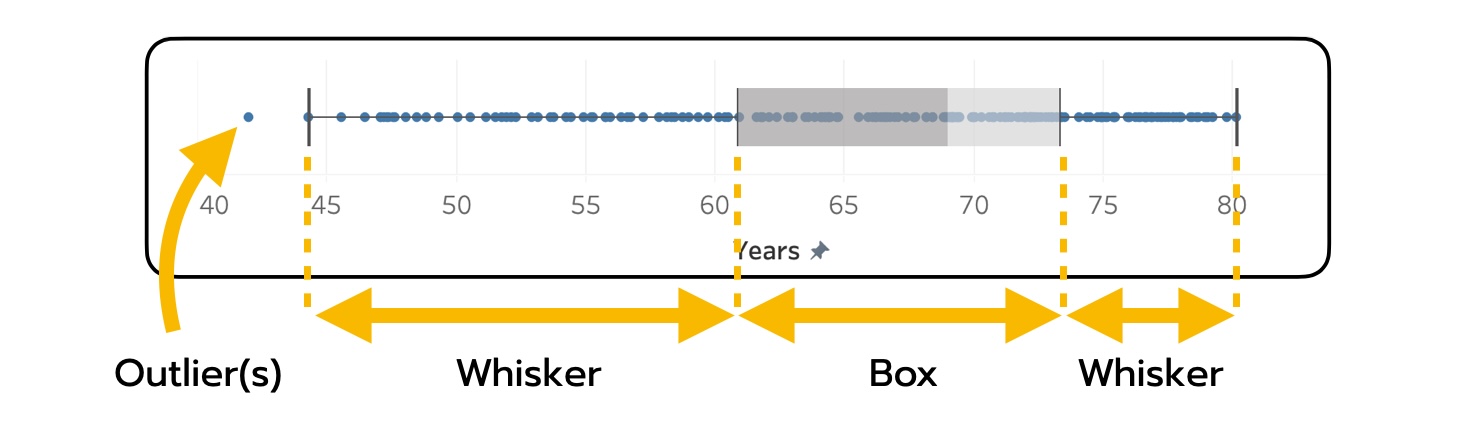
Box Plot ประกอบไปด้วยส่วนของ “กล่อง” (Box) กับส่วนของ “หนวด” (Whiskers) และมีจุด ๆ แสดงข้อมูลจริง โดยอาจอยู่ได้ทั้งในและนอกหนวด (บางครั้งเราจะเห็นบางเวอร์ชันของแผนภาพที่โชว์จุดข้อมูลนอก Whiskers อย่างเดียว ก็ยังนับเป็น Box Plot อยู่) ซึ่งตำแหน่งของ Box และ Whiskers ถูกสร้างขึ้นมาได้ โดยตัวเลขทางสถิติทั้งหมดถึง 5 ตัวด้วยกัน เรียกรวมกันว่า The Five-Number Summary ประกอบไปด้วย:
- ค่าต่ำสุด (Minimum)
- Q1 (The First Quartile): ค่าของข้อมูลที่แบ่งข้อมูลออกเป็นสัดส่วน 25-75 โดยมีจำนวนข้อมูลที่น้อยกว่าค่า Q1 อยู่ 25%
- ค่ามัธยฐาน (Median): ค่ากลางที่แบ่งประชากรออกเป็นสองข้างเท่า ๆ กัน ข้างละ 50%
- Q3 (The Third Quartile): ค่าของข้อมูลที่แบ่งข้อมูลออกเป็นสัดส่วน 75-25 โดยมีจำนวนข้อมูลที่น้อยกว่าค่า Q3 อยู่ 75%
- ค่าสูงสุด (Maximum)
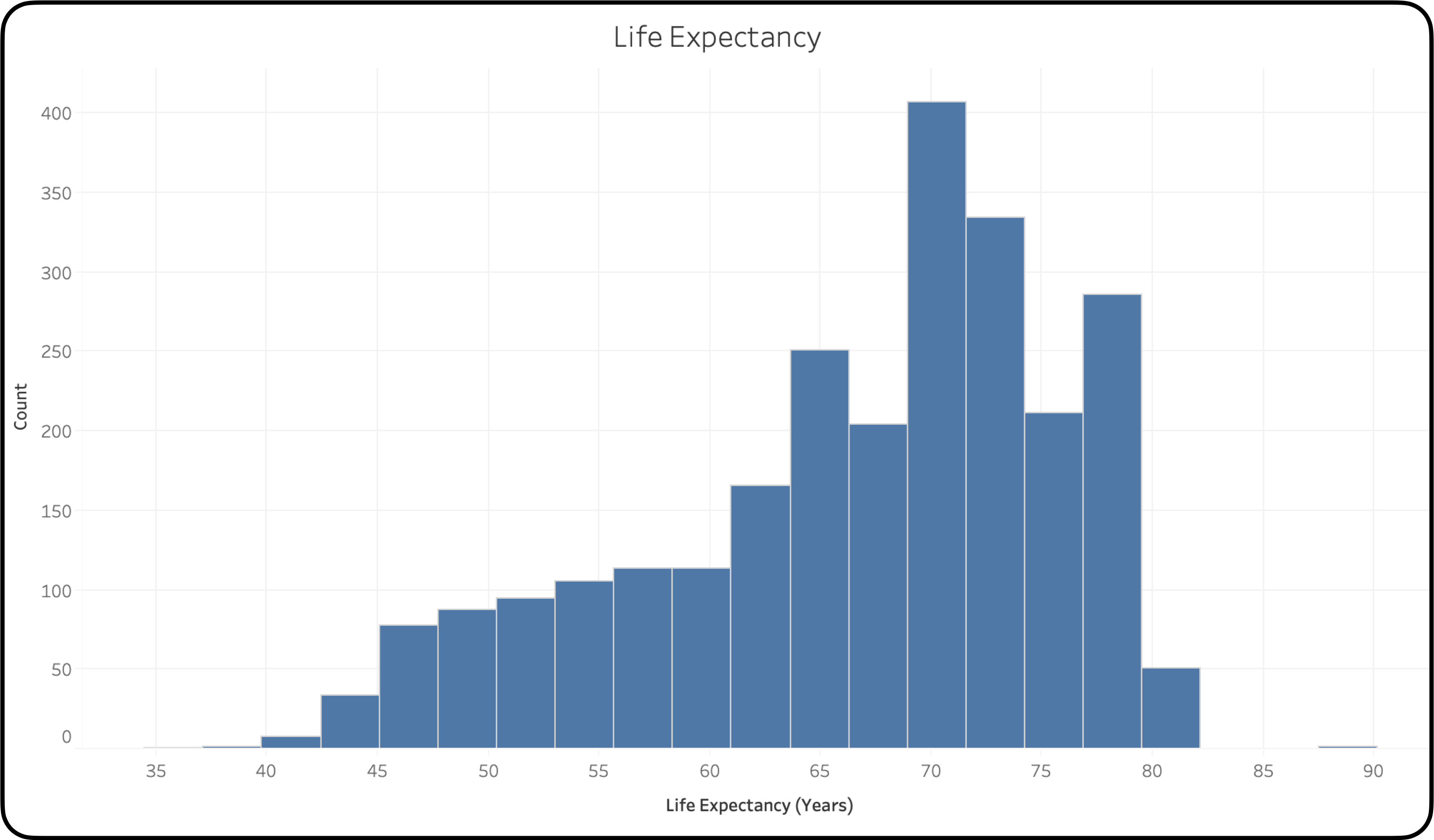
เพื่อยกตัวอย่างให้เห็นภาพ สมมติว่าเรานำข้อมูลอายุขัยของประชากรเพศชาย (Life Expectancy for Males) มาวางเรียงกัน จากน้อยไปหามาก แล้วหาค่าตามหลัก The Five-Number Summary แล้วคำนวณได้ว่า
- ค่าต่ำสุด (Minimum) = 42 years
- Q1 (The First Quartile) = 61.5 years
- ค่ามัธยฐาน (Median) = 69 years
- Q3 (The Third Quartile) = 73 years
- ค่าสูงสุด (Maximum) = 80 years
ค่าเหล่านี้ถูกนำไปใช้ทำจุดสำคัญต่าง ๆ บน Box Plot เป็นกล่องและหนวดนั่นเอง ดังภาพด้านล่าง ซึ่งมีข้อสังเกตว่า
- ค่าตรงกลางกล่อง ใช้ Median แบ่งกล่องเป็นสองซีก (สังเกตว่าไม่จำเป็นต้องแบ่งช่วงของข้อมูลเท่า ๆ กัน เพราะที่ Median ต้องแบ่งให้เท่ากันคือ จำนวนของข้อมูล ในที่นี้คือ จำนวนประชากรชาย)
- ค่าขอบกล่องทั้งสองข้าง ใช้ Q1 และ Q3
- ส่วนค่าต่ำสุดและค่าสูงสุด ใช้แสดงเป็นจุดที่อยู่สุดขอบ Box Plot
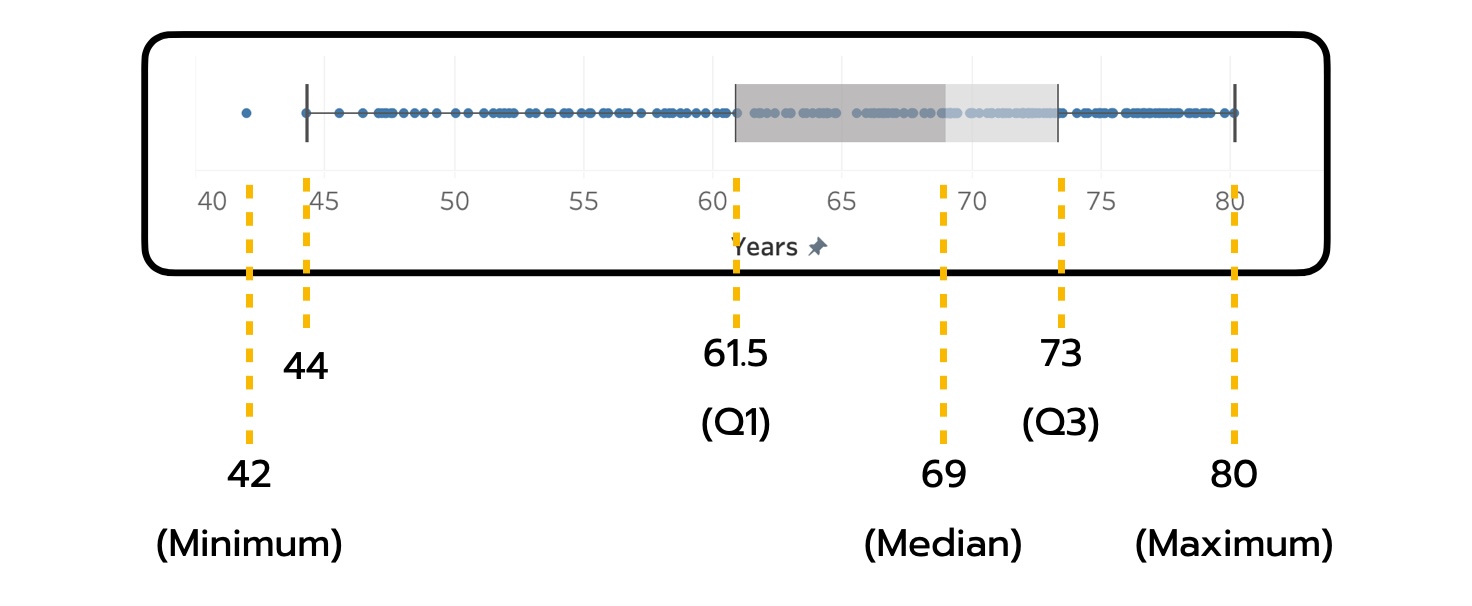
หากเราลองมาใช้ตัวเลข 5 ตัวนี้ แปลผล Box Plot เบื้องต้นกัน เราจะได้ข้อสังเกตหลาย ๆ อย่างได้ไม่ด้อยไปกว่า (หรือในบางมิติ เหนือกว่า) Histogram เช่น
- ประชากรชายทั่วไป มีอายุขัยอยู่ที่ 69 ปี โดยวัดจากค่ามัธยฐานเป็นค่ากลาง สังเกตจากขีดกลางของกล่อง
- ประชากรชายกว่า 25% มีอายุขัยไม่เกิน 61.5 ปี และประชากรชายกว่า 75% มีอายุขัยไม่เกิน 73 ปี สังเกตจาก Q1, Q3 ที่บริเวณขอบกล่องทั้งสองด้าน
- ประชากรชายส่วนใหญ่ (อย่างน้อยกึ่งหนึ่ง) มีอายุขัยเฉลี่ย อยู่ในช่วงประมาณ 61.5 – 73 ปี
- เรายังรู้อีกด้วยว่า ข้อมูลนี้ มีการกระจายตัวแบบเบ้ซ้าย (Left Skewed Distribution) เพราะข้อมูลส่วนใหญ่กระจุกตัวอยู่ทางขวามือของช่วงข้อมูลทั้งหมด ทั้งนี้ ถ้าชุดข้อมูลไม่มีการเบ้ ค่ากลางมัธยฐานควรจะอยู่ที่ประมาณ (42 + 80) / 2 = 61 ปี
ท่านที่ช่างสังเกตจะพบว่ามีตำแหน่งสำคัญที่ผมยังไม่ได้อธิบายใน Box Plot คือตัวเลข 44 บนหนวด Whisker ข้างซ้าย และสิ่งที่น่าสงสัยอีกประการหนึ่งคือ เหตุใดค่า 80 ที่เป็น Maximum จึงไปอยู่บนปลายหนวดข้างขวาพอดี? เป็นความบังเอิญหรือไม่? ข้อสังเกต เหล่านี้สามารถถูกอธิบายได้ว่า จริง ๆ แล้ว จาก Five-Number Summary เราจะต้องมีการคำนวณปริมาณทางสถิติเพิ่มบางประการ กล่าวคือ:
- Interquartile Range (IQR): นิยามโดย IQR = Q3 – Q1
เราเอาค่า IQR มาคำนวณค่าปลายหนวดทั้งสองข้าง ดังนี้:
- Lower Whisker: max(Minimum, Q1 – 1.5 * IQR)
- Upper Whisker: min(Maximum, Q3 + 1.5 * IQR)
เสมือนว่าเป็นการ “ขยาย” ตัวกล่องออกไปด้านข้างด้วยความกว้าง 1.5 เท่าของกล่อง แต่ขยายไม่เกินข้อมูลสูงสุดหรือข้อมูลต่ำสุดที่มีอยู่จริง ซึ่งกฎ 1.5 * IQR ได้รับการยอมรับอย่างแพร่หลาย โดยนิยามข้อมูลที่อยู่นอกช่วง [Q1 – 1.5 * IQR, Q3 + 1.5 * IQR] ได้ว่าเป็น ค่าสุดโต่ง หรือ Outliers (คือค่าเหล่านี้ นับว่าหายากมาก ๆ) ยกตัวอย่างเช่น ถ้าข้อมูลมีการกระจายตัวแบบปกติ (Normal Distribution) ข้อมูลที่อยู่นอกช่วง Lower Whisker และ Upper Whisker จะมีเพียง 0.7% เท่านั้น จึงถูกจัดเป็น Outliers
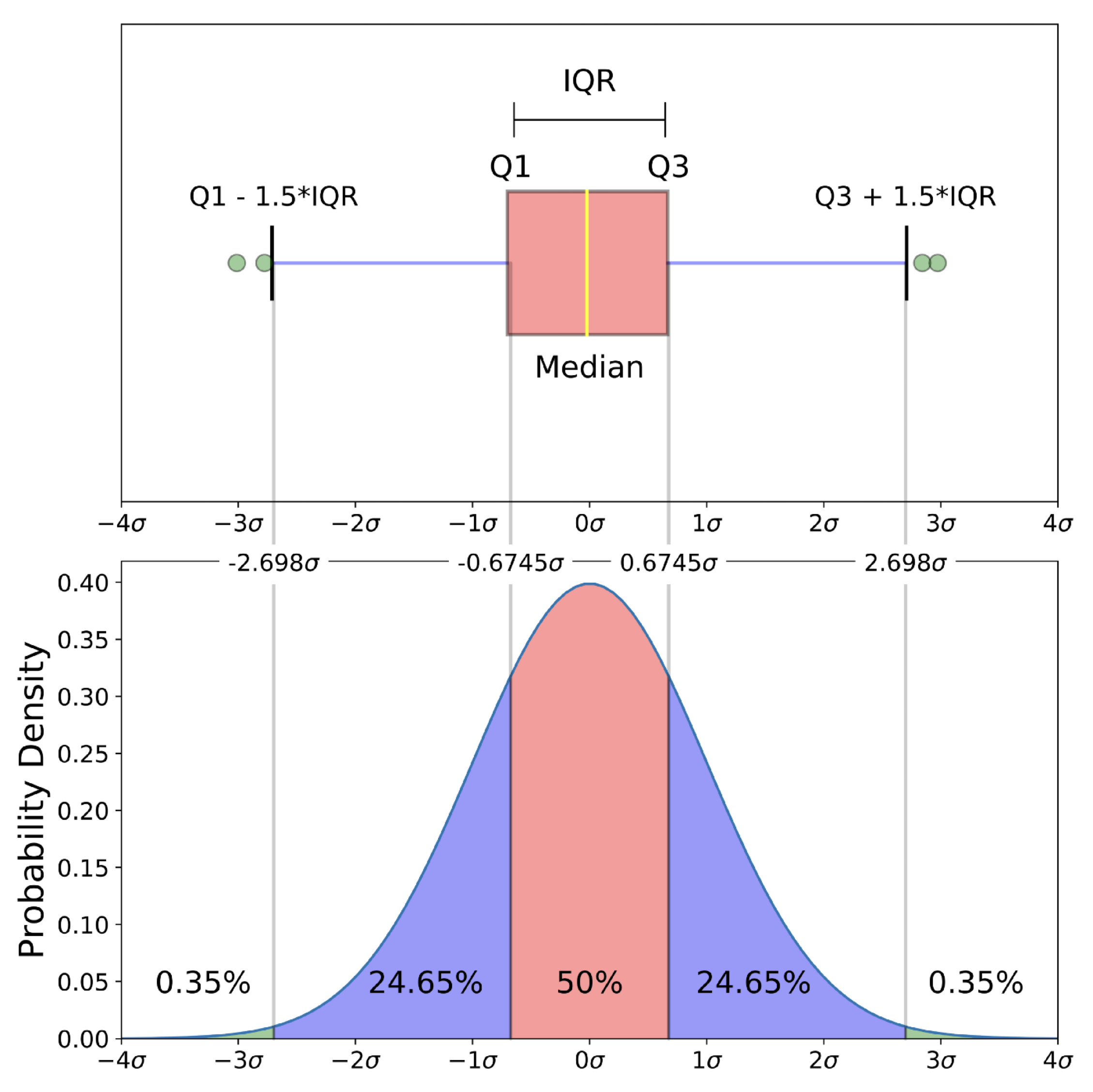
ได้รับอนุญาตเพื่อเผยแพร่จาก Michael Galarnyk
เราจะเห็นได้ว่าแผนภาพ Box Plot ถึงแม้จะมีขนาดเล็กมากเมื่อเทียบกับ Histogram แต่ให้ข้อมูลและข้อสังเกตได้น่าสนใจหลายประการ ไม่ว่าจะเป็นลักษณะการกระจายตัว เช่น ข้อมูลเบ้ซ้ายหรือเบ้ขวา, ค่ากลางของข้อมูล, ช่วงของข้อมูลส่วนใหญ่, ช่วงของข้อมูลเกือบทั้งหมด, และค่าสุดโต่ง ซึ่งข้อสังเกตหลายข้ออาจสังเกตได้ง่ายกว่า Histogram ไม่ว่าจะเป็นค่ากลางมัธยฐาน, ค่าสุดโต่ง, ช่วงของข้อมูลส่วนใหญ่ เพราะมีตำแหน่งสำคัญต่าง ๆ ที่ถูกคำนวณและถูกกำกับอยู่ในแผนภาพอย่างชัดเจน
หากท่านผู้อ่านได้อ่านมาถึงจุดนี้แล้วเริ่มรู้สึกหลงรัก Box Plot ผมขอเสนอเหตุผลอีกสองข้อที่จะทำให้ Box Plot น่าใช้งานมากขึ้นไปอีก เรามาดูข้อถัดไปกันเลยครับ
เหตุผลข้อ 3: Box Plot ยืดหยุ่นในการนำเสนอ
เนื่องจาก Box Plot เป็นแผนภาพ 1D ทำให้มีความยืดหยุ่นและสามารถถูกนำเสนอในรูปแบบแนวนอนหรือแนวตั้งก็ได้ ผมได้แสดงตัวอย่าง Box Plot ในแนวนอนด้านบนแล้ว เรามาดูตัวอย่างการนำเสนอ Box Plot ในแนวตั้ง ซึ่งผมจะนำเสนอพร้อมกับเหตุผลข้อสุดท้ายครับ
เหตุผลข้อ 4: Box Plot เปรียบเทียบการกระจายตัวระหว่างข้อมูลเชิงคุณภาพได้ง่าย
ข้อมูลเชิงคุณภาพ (Qualitative Data) ซึ่งในบางครั้งเราก็เรียกค่าของข้อมูลเหล่านี้ว่า Categorical Values เป็นข้อมูลที่ปกติจะไม่สามารถนำมาใช้คำนวณ บวก ลบ คูณ หาร เหมือนกับข้อมูลเชิงปริมาณ (Quantitative Data หรือ Numerical Values) ได้ และค่าทางสถิติเช่น “ค่าเฉลี่ยเลขคณิตระหว่างเพศชายกับเพศหญิง” จะไม่มีนิยามที่มีความหมายชัดเจน เหมือนกับ “ค่าเฉลี่ยเลขคณิตระหว่าง 10 กับ 20 คือ 15” ตัวอย่างของข้อมูลเชิงคุณภาพ เช่น
- สี (แดง, ส้ม, เขียว)
- ชื่อประเทศ (ไทย, จีน, สเปน)
- ชนิดยานพาหนะ (รถยนต์, รถจักรยานยนต์, เครื่องบิน)
- เพศ (ชาย, หญิง)
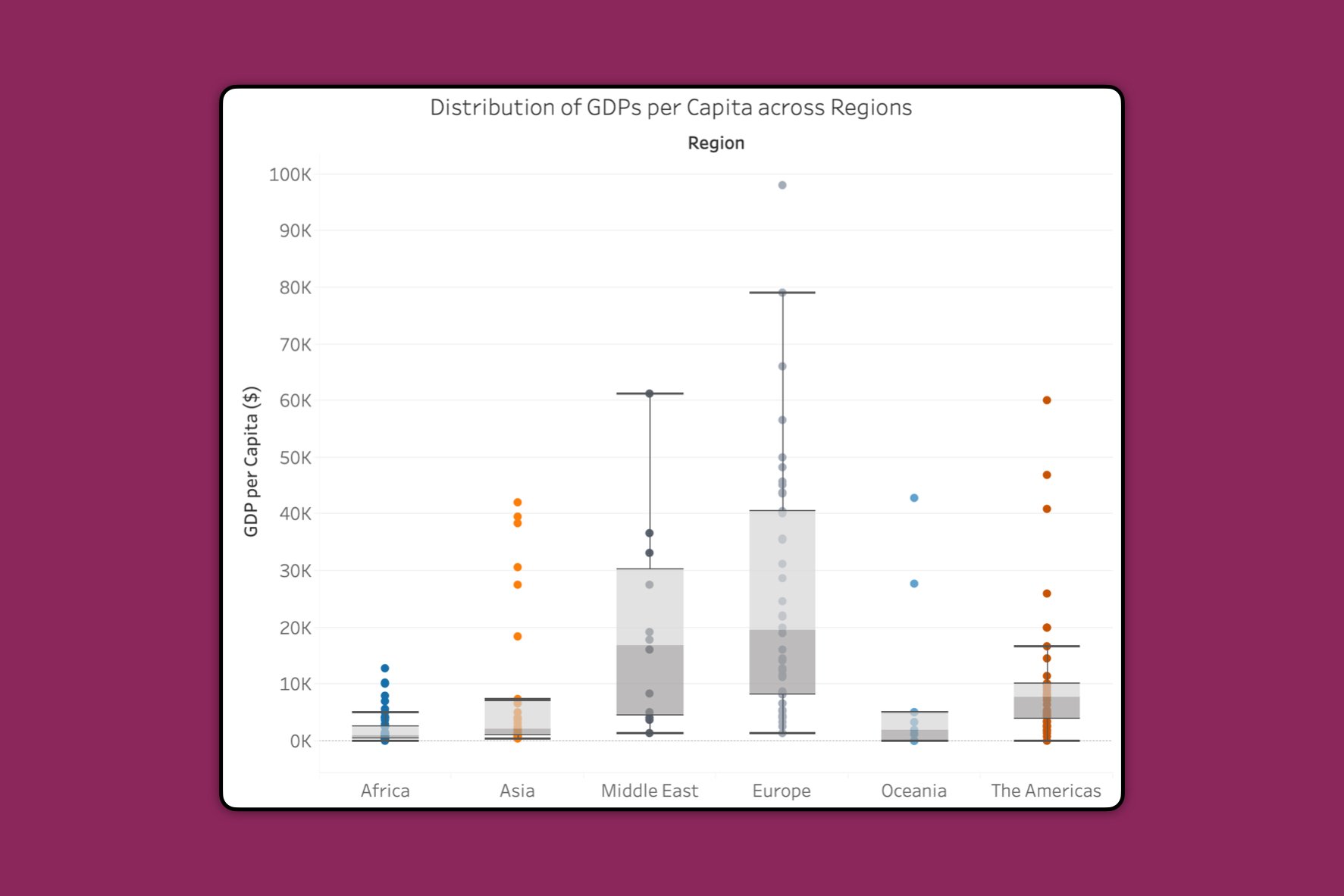
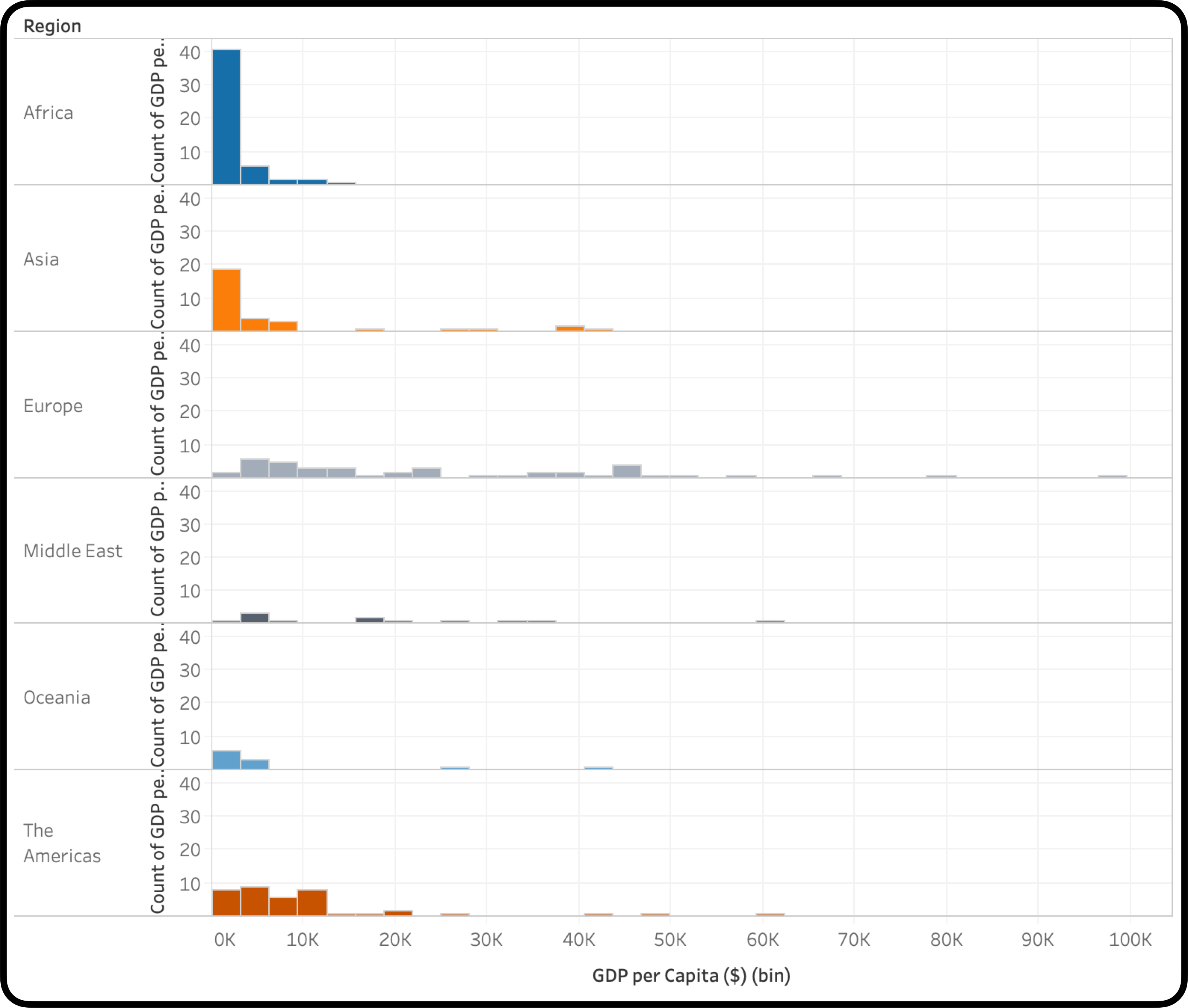
แต่ข้อมูลเชิงคุณภาพเหล่านี้จะมีประโยชน์อย่างสูงหากเราใช้ร่วมกับข้อมูลเชิงปริมาณเพื่อทำการเปรียบเทียบการกระจายตัวของข้อมูลหลาย ๆ ชุด ดังในตัวอย่างด้านล่างนี้ สมมติว่าเรามีข้อมูลผลิตภัณฑ์มวลรวมในประเทศต่อหัว (GDPs per Capita) ของแต่ละประเทศต่าง ๆ ซึ่งสามารถจำแนกได้เป็นรายทวีป และเราอยากรู้ว่า มีความแตกต่างกันอย่างมีนัยสำคัญ ระหว่าง GDPs per Capita ของประเทศในทวีปเอเชีย และประเทศในทวีปอื่น ๆ หรือไม่?
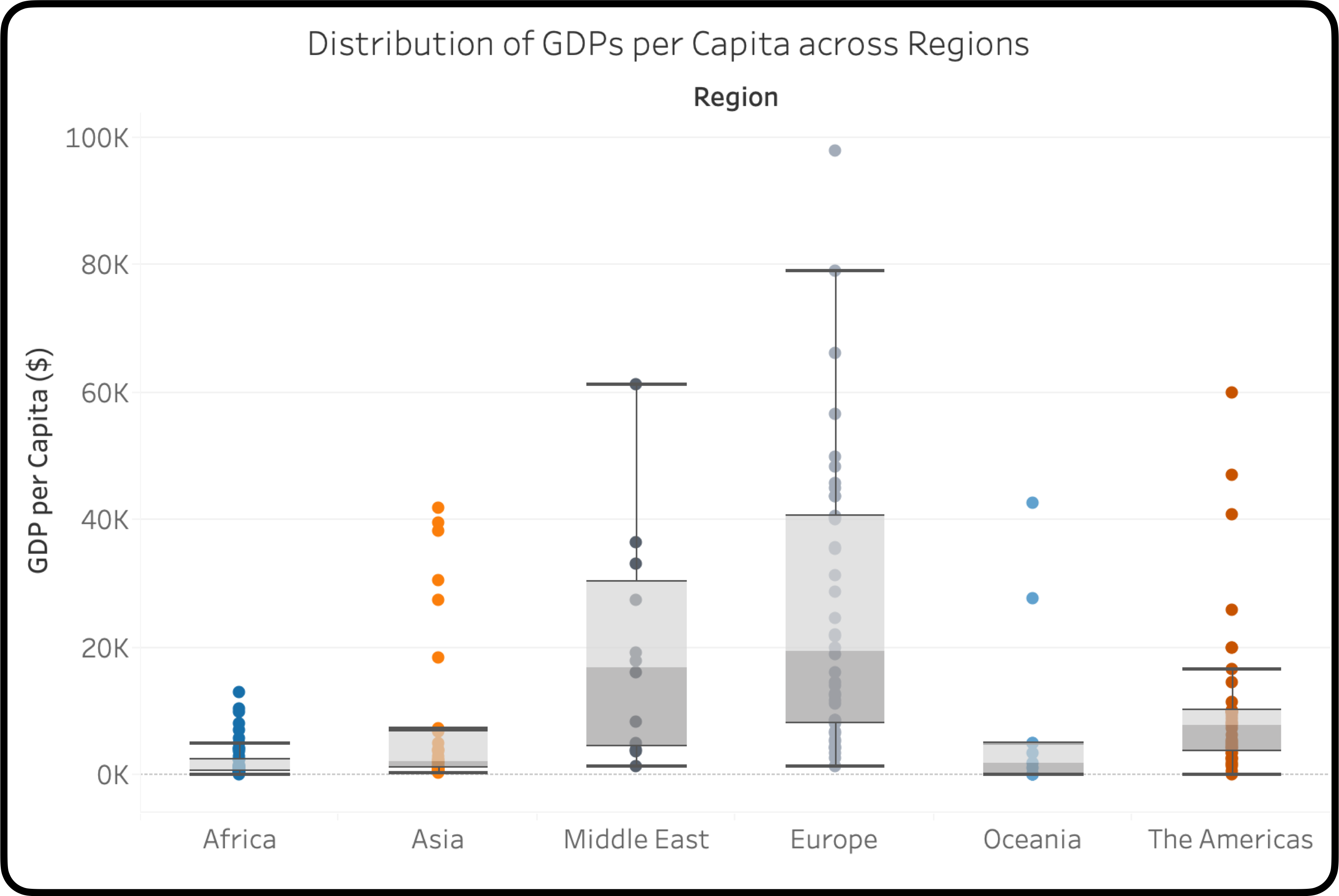
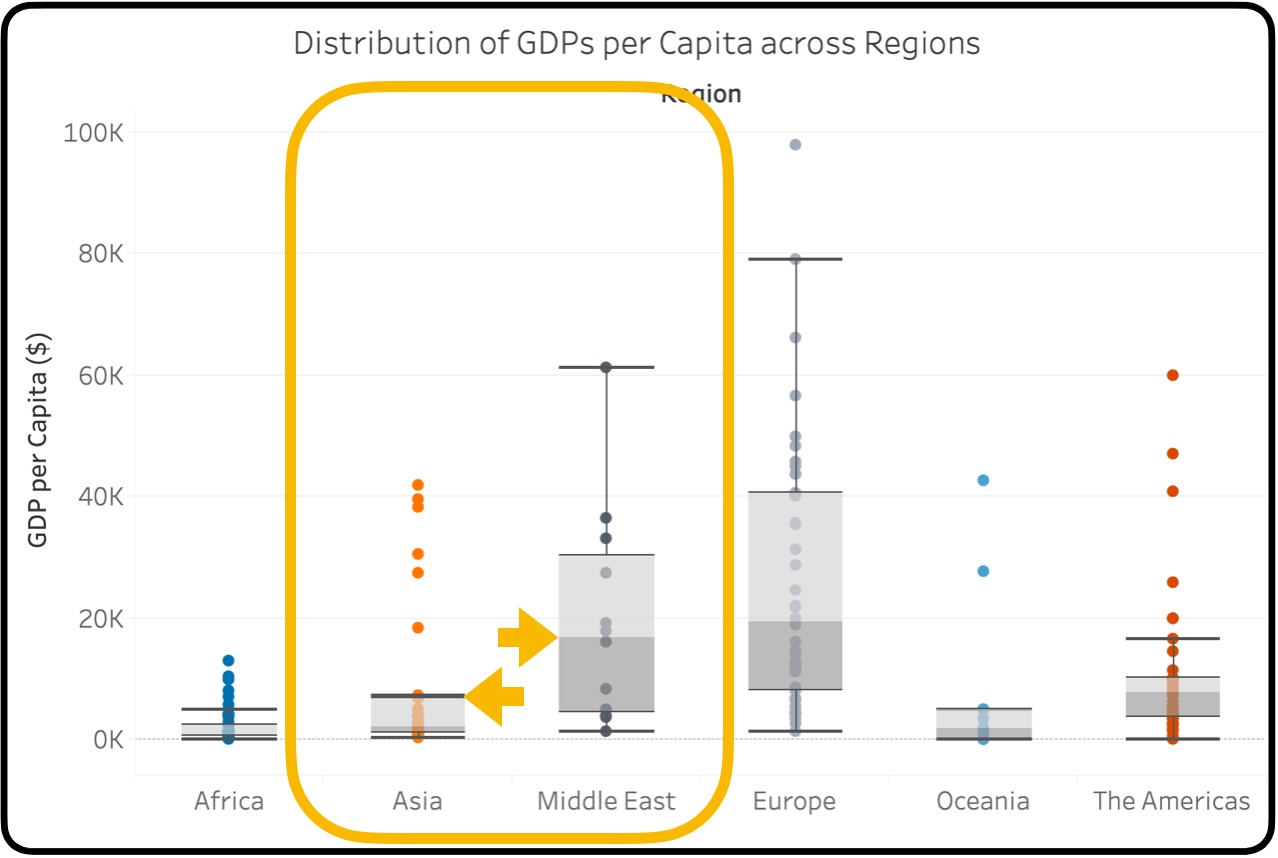
เราสามารถนำ Box Plots หลาย ๆ กัน มาเทียบกันได้ โดยแกนหนึ่งเป็นข้อมูลเชิงปริมาณ (GDPs per Capita) และอีกแกนหนึ่งเป็นข้อมูลเชิงคุณภาพ (ทวีป หรือ Regions) แต่ละจุดคือ หนึ่งประเทศ ซึ่งสิ่งแรกที่เราสามารถสังเกตได้ทันที คือความยืดหยุ่นของ Box Plot ที่สามารถนำเสนอเป็นแบบตั้งได้ นอกจากนี้ เรายังสามารถตอบคำถามเชิงการกระจายตัวของข้อมูลพร้อม ๆ กับการเปรียบเทียบ GDPs per Capita ระหว่างทวีปได้ เช่น ระหว่างทวีปเอเชีย กับทวีปตะวันออกกลาง ข้อมูลเกือบทั้งหมดของประเทศแถบเอเชีย ดูจากหนวดบน (Upper Whisker) ของทวีปเอเชีย ที่อยู่ต่ำกว่าค่ากลางมัธยฐาน (Median) ของประเทศแถบตะวันออกกลางอย่างชัดเจน จากข้อมูลตัวอย่างนี้ ทำให้เราสรุปได้อย่างหนึ่ง คือ ประเทศแถบเอเชียเกือบทั้งหมด ร่ำรวยไม่เท่าประเทศ “ฐานะปานกลาง” ในแถบตะวันออกกลาง ในขณะที่จุดที่ส้มที่อยู่นอก Whisker ของทวีปเอเชีย ถึงแม้จะดูเหมือนมีอยู่เยอะ แต่ก็เป็นเพียงค่าสุดโต่ง (Outliers) ที่หายากมากกว่า
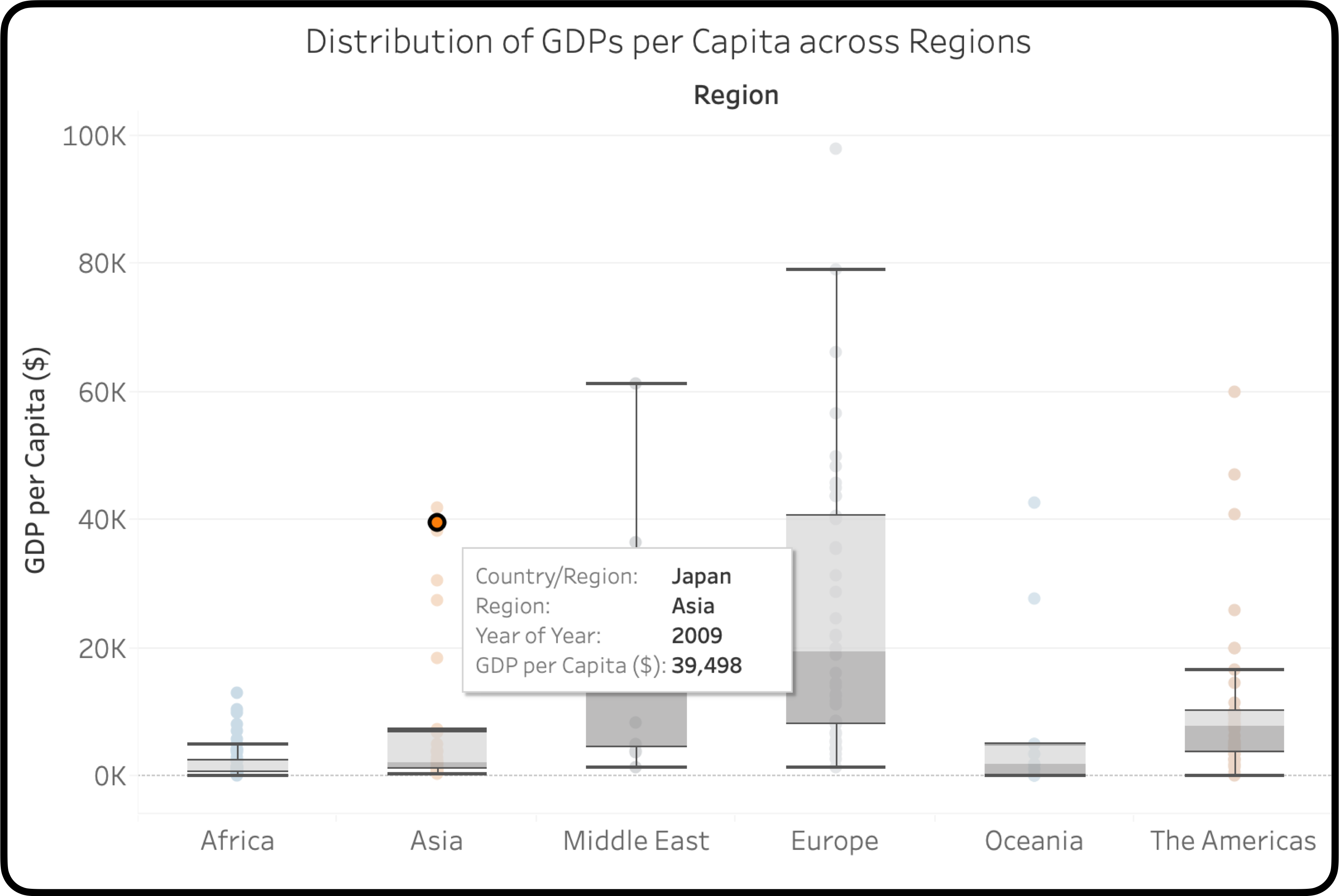
นอกจากนี้แล้ว เนื่องจาก Box Plot ยังแสดงข้อมูลแยกเป็นรายการได้ เครื่องมือทำ Data Visualization ในปัจจุบัน (ผมใช้ Tableau ในการสร้างแผนภาพในบทความนี้) ก็เพิ่มความสามารถให้กับ Box Plot ไปอีกขั้น คือ เราสามารถเอาเมาส์ไปวางบนรายการแต่ละรายการ เพื่อดูข้อมูลเพิ่มเติมได้ เช่น ในกรณีนี้ เราสามารถดูได้ว่า ค่าสุดโต่งในประเทศแถบเอเชีย เป็นของประเทศอะไรบ้าง (เช่น ญี่ปุ่น)
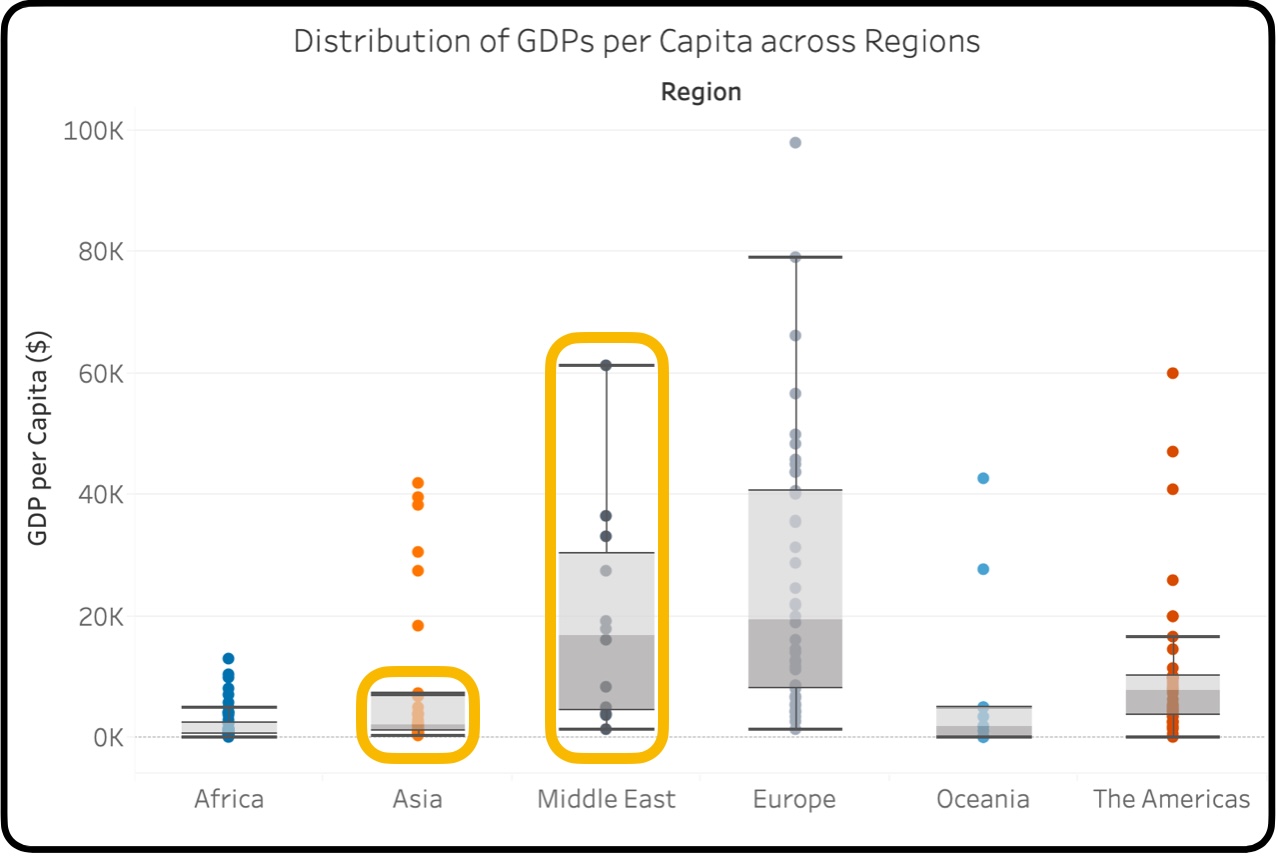
จากการเปรียบเทียบระหว่าง Box Plots เรายังทราบอีกด้วยว่า ค่า GDPs per Capita ระหว่างสองทวีปนี้ มีความแปรปรวน (Variance) ที่ต่างกันมาก ประเทศในแถบเอเชียเกือบทั้งหมด มีฐานะที่ใกล้เคียงกัน ส่วนประเทศในแถบตะวันออกกลาง บางประเทศก็ร่ำรวยมาก บางประเทศก็ไม่ได้ร่ำรวยเหมือนเพื่อนบ้าน
ในทางกลับกัน ถ้าเราจะใช้ Histogram แสดงการกระจายตัวของข้อมูล ถึง 6 ชุดย่อย เพื่อเปรียบเทียบกันใน Chart เดียว เราจะต้องสร้าง Histogram ซ้อนกันถึง 6 อันด้วยกัน ซึ่งอาจะทำให้ดูเปรียบเทียบยาก ส่วนหนึ่งเพราะไม่มีตำแหน่งสำคัญทางสถิติ เช่น Q1, Q3, Median ที่ถูกคำนวณไว้แล้ว และยังมีที่ว่างเหลือจำนวนมาก (เพราะข้อมูลเบ้ขวามาก)
ข้อสังเกตส่งท้าย
แผนภาพ Box Plot สามารถมอบข้อสังเกตเชิงสถิติที่น่าสนใจได้มากกมาย และสามารถสังเกตได้ง่ายกว่า Histograms ในหลาย ๆ มิติ นอกจากนี้ยังประหยัดพื้นที่ มีความยืดหยุ่นในการนำเสนอ และยังสามารถเปรียบเทียบการกระจายตัวระหว่างประเภทข้อมูลเชิงคุณภาพได้อีกด้วย
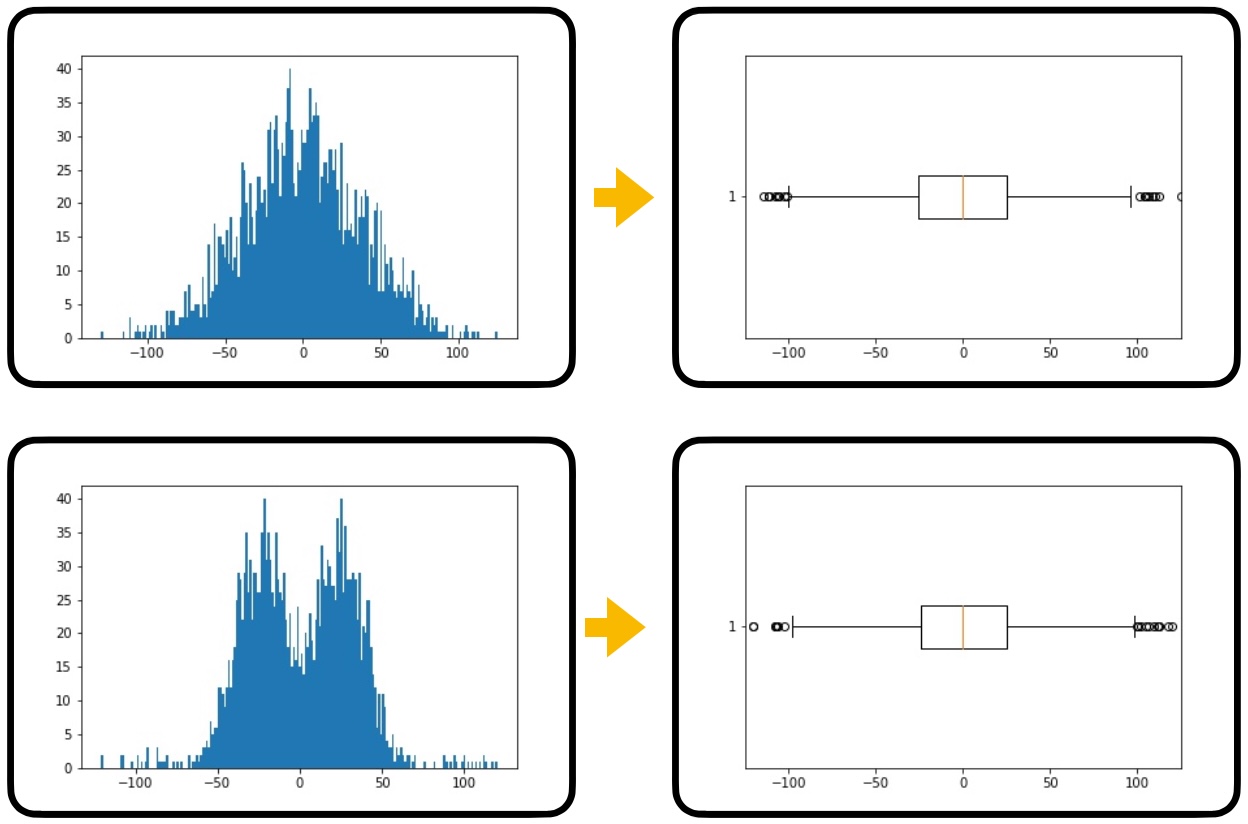
อย่างไรก็ตาม ในฐานะนักวิเคราะห์ข้อมูล เราควรตระหนักถึงจุดแข็งข้อหนึ่งของ Histogram ที่เหนือกว่า Box Plot นั่นคือความสามารถตรวจพบการกระจายตัวของข้อมูลได้ลึกกว่า เช่น สามารถแยกแยะการกระจายตัวแบบ 1 ยอด (Unimodal) ออกจาก 2 ยอด (Bimodal) ได้ ในขณะที่ข้อมูลสองชุดนี้ ให้ Box Plots ที่อาจมีหน้าตาเหมือนกันจนแยกไม่ออก ดังตัวอย่างด้านล่าง
ผู้อ่านที่อ่านมาถึงจุดนี้ ผมก็หวังว่าผู้อ่านที่ไม่เคยใช้งาน Box Plot ในการวิเคราะห์ข้อมูลมาก่อน ก็อาจจะเริ่มให้ความสนใจและเห็นประโยชน์ของแผนภาพนี้ และเลือกใช้ Box Plot ในสถานการณ์และบริบทที่เหมาะสมครับ ?
เนื้อหาโดย ปพจน์ ธรรมเจริญพร
ตรวจทานและปรับปรุงโดย นนทวิทย์ ชีวเรืองโรจน์

Former-Editor-in-Chief at BigData.go.th and Senior Data Scientist at Government Big Data Institute (GBDi )













