
สถานการณ์การแพร่ระบาดของเชื้อไวรัสโคโรนาสายพันธุ์ใหม่ที่ทำให้เกิดโรคโควิด-19 ไม่เพียงแค่ส่งผลกระทบโดยตรงต่อการใช้ชีวิตของคนทั่วโลก แต่ยังส่งผลให้เศรษฐกิจชะลอตัวลงอย่างหลีกเลี่ยงไม่ได้ สร้างแรงสั่นสะเทือนต่อบริษัทยักษ์ใหญ่เป็นจำนวนไม่น้อย แต่ในทางกลับกัน Platform Streaming ชื่อดังอย่างเน็ตฟลิกซ์ (Netflix) กลับมียอด สมาชิกเพิ่มขึ้นถึง 15.77 ล้านคน และมีรายได้รวมเพิ่มขึ้นถึง 27.6% เมื่อเทียบกับช่วงเดียวกันของปีที่แล้ว
“More than 80% of what people watch comes from our recommendation.”
Netflix
นั่นเป็นเพราะเน็ตฟลิกซ์ได้มีการใช้เทคนิคทางด้านวิทยาศาสตร์ข้อมูล (Data Science) เข้ามาเกี่ยวข้อง โดยเน็ตฟลิกซ์ได้กล่าวว่า “More than 80% of what people watch comes from our recommendation.” ซึ่งถือว่าเป็นตัวเลขที่สูงมาก ๆ บทความนี้จะอธิบายเกี่ยวกับการใช้ Big Data ของเน็ตฟลิกซ์ ที่ทำให้เน็ตฟลิกซ์กลายเป็นระบบ streaming เบอร์ 1 ของโลกในยุคปัจจุบัน
ในปี พ.ศ.2549 ซึ่งบริษัทได้เริ่มเปิดตัวในสหรัฐอเมริกานั้น เน็ตฟลิกซ์มีจำนวนสมาชิกทั้งสิ้นประมาณ 6 ล้านคน ก่อนจะเพิ่มจำนวนเป็นกว่า 100 ล้านในปี พ.ศ.2560 และให้บริการในกว่า 190 ประเทศ ถ้าคิดเป็นค่าเฉลี่ยแล้วเน็ตฟลิกซ์จะมีสมาชิกหน้าใหม่ปีละ 8.5 ล้าน ซึ่งเป็นการเติบโตที่รวดเร็วมาก และผมเองก็เป็นหนึ่งในลูกค้าของเน็ตฟลิกซ์เหมือนกัน
ผมไม่รู้ว่าเพื่อน ๆ เป็นแบบผมหรือเปล่า ที่น้อยครั้งมากที่จะมานั่งหาชื่อหนังที่จะดูโดยการพิมพ์ชื่อหนังเอาเองในช่องค้นหา เพราะโดยส่วนใหญ่แล้ว ถ้าผมอยากจะดูหนังอะไรสักเรื่องก็มักจะเลือกดูจากลิสต์หนังที่ทางเน็ตฟลิกซ์แนะนำมาให้ในหน้า Home ซึ่งทุกครั้งก็มักจะได้หนัง หรือ ซีรี่ย์ ที่สนุก ถูกใจจากลิสต์หนังพวกนั้นนี่แหละ
การที่จะแนะนำหนังให้ถูกใจลูกค้าไม่ใช่เรื่องง่ายเพราะ ถึงแม้จะมีทฤษฎีที่บอกว่า คนที่มีลักษณะทางประชากรคล้าย ๆ กันจะชอบอะไรคล้าย ๆ กัน แต่นั่นก็ไม่เสมอไป เพราะแต่ละคนก็จะมีความ Unique หรือ เอกลักษณ์รสนิยมของแต่ละบุคคล ด้วยเหตุนี้เน็ตฟลิกซ์เลยวางระบบ Personalize ที่ Unique ของแต่ละสมาชิกซึ่งแต่ละ Profile ของเน็ตฟลิกซ์จะเห็นอะไรที่แตกต่างกัน และ แน่นอนว่าผมไม่ได้กำลังพูดถึงแต่ลิสต์ของหนังที่แตกต่างกัน สิ่งที่แตกต่างกันยังมี
- การจัดลำดับ (Ranking) การเรียงหนังของแต่ละสมาชิกจะแตกต่างกัน โดยที่จะวางหนังที่คิดว่าสมาชิกนี้จะชอบที่สุดไว้ทางด้านซ้าย
- การวางโครงสร้าง (Structure) ของหน้าจอ จากบนลงล่าง จะมี Section ของหนังที่แตกต่างกัน
- การปรับงานศิลป์ให้ถูกจริตส่วนบุคคล (Personalized Artwork) กล่าวคือ แม้แต่ Artwork ก็ มีการ Personalize เคยสังเกตไหมว่าหน้าปกของหนังที่เราดู จะมีความแตกต่างกันบางครั้ง และ หน้าปกติใน profile ของเพื่อนมันแตกต่างกัน นั่นแหละ เพราะ Netflix มองว่าหน้าปกของหนังส่งผลต่อการตัดสินใจกับการดูของลูกค้า และ ลูกค้าแต่ละคนชอบปกหนังแตกต่างกัน ดังนั้นเน็ตฟลิกซ์พยายามเลือก Artwork ของปกหนังที่คิดว่าลูกค้าจะชอบที่สุด
- “เนื้อหาคัดสรรสำหรับคุณ” ข้อความที่เด้งขึ้นมาใน การแจ้งเตือนของเน็ตฟลิกซ์ก็เป็นการวิเคราะห์จาก Big Data ของหนังที่สมาชิกคนนั้นเคยดู และเพื่อเลือกหนังที่คาดว่าจะถูกใจสมาชิกคนนั้น ๆ
- Trending Now ของประเทศ นั้น ๆ เพื่อแสดงให้เห็นว่า Community หรือ สังคมนั้น ๆ กำลังนิยมรับชมอะไรกันอยู่บ้าง

จุดมุ่งหมายของระบบ Personalization หรือ Recommender System ของเน็ตฟลิกซ์คือเพื่อเพิ่มความพึงพอใจของสมาชิก โดยการช่วยสมาชิกค้นหาหนังที่ตัวจะชอบ ซึ่งระบบนี้มันซับซ้อนกว่าที่เราคิด เพราะการที่จะวางโครงสร้างของแพลตฟอร์มให้สามารถเก็บข้อมูล สร้างระบบ Machine learning และทำการ Deploy ได้นั้นไม่ใช่เรื่องง่าย และหนึ่งในอุปสรรคที่ใหญ่คือเรื่องของเวลา
อุปสรรคที่ใหญ่ของการพัฒนาระบบ Personalization หรือ Recommender System คือเรื่องของเวลา
เวลาทำให้อะไรหลาย ๆ อย่างไม่แน่นอน ยกตัวอย่างเช่น พฤติกรรรมการดูหนังของสมาชิก ดังนั้นการวางระบบ Personalize ให้ปรับตามการเปลี่ยนแปลงต่าง ๆ บนแพลตฟอร์มของเน็ตฟลิกซ์ถือเป็นโจทย์ที่ใหญ่ เน็ตฟลิกซ์ได้วางระบบที่จะมีการ Train โมเดลในออฟไลน์ ตามมาด้วย A/B Testing บนออนไลน์ การทำ A/B Testing เป็นกระบวนการที่ทดสอบว่า สมาชิก จะชอบ การแนะนำหนังแบบไหน Art work แบบไหน มากที่สุด เพื่อนำมาปรับปรุงตัวโมเดลเรื่อย ๆ หลังจากใช้งานจริง

เน็ตฟลิกซ์ให้ความสำคัญกับความเชื่อถือได้ (Reliability) ของโมเดล ขณะที่ Offline Model ต้อง Train อย่างเชื่อถือได้นั้น Online Model ก็ต้อง Perform อย่างเชื่อถือได้เช่นกัน การฝึกซ้ำ (Retraining) ของโมเดลต้องทำได้โดยอัตโนมัติและสามารถ Train ซ้ำได้เรื่อย ๆ
โมเดลในฝั่งออฟไลน์
แน่นอนว่าเวลาอาจทำให้ข้อมูลมีการเปลี่ยนแปลงโดยฉับพลัน หรืออาจมีปัญหาทางเทคนิคในขั้นตอนเก็บข้อมูล ซึ่งสองปัญหานี้จะส่งผลกับ Performance ของโมเดลเป็นแน่ ดังนั้นระบบในการตรวจจับปัญหาเป็นสิ่งที่จำเป็นเพื่อป้องกันไม่ให้โมเดลที่มี Performance ต่ำถูกเลือกมาใช้บนแพลตฟอร์ม หนึ่งในระบบนี้ของเน็ตฟลิกซ์ใช้ Anomaly Detection เพื่อตรวจจับความผิดปกติในชุดข้อมูลที่นำมาใช้พัฒนาโมเดล
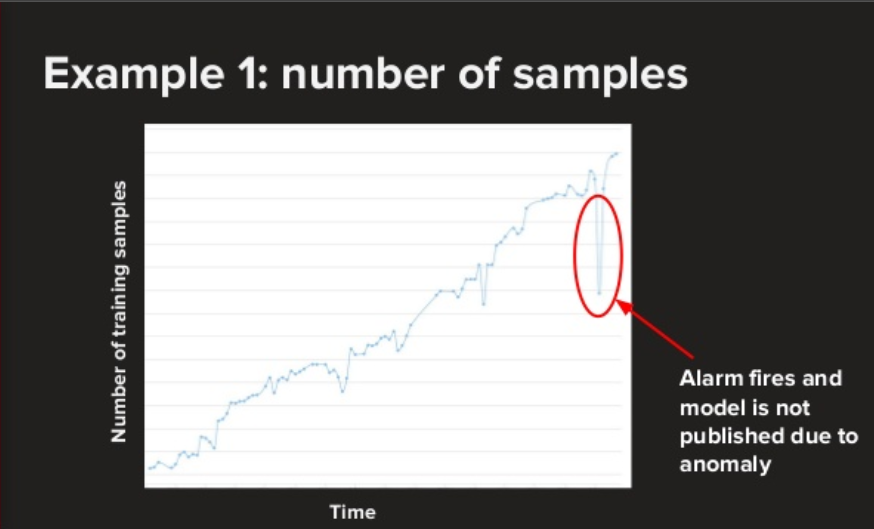
จากภาพจะเห็นได้ชัดว่า จำนวนตัวอย่างที่ใช้ Train ตกลงจนผิดปกติในบริเวณที่วงสีแดงไว้ เมื่อเกิดเหตุเช่นนี้ระบบ Anomaly Detection ของเน็ตฟลิกซ์จะส่งสัญญาณเตือนและหยุดการเผยแพร่ (Publish) ไว้ก่อน นอกจากตัวอย่างนี้แล้วยังมีตัวอย่างอื่นอีกมากมายในส่วนของการ Training ในฝั่งออฟไลน์ เช่น การ Train โมเดลจากการสุ่มที่หลากหลาย เพื่อป้องกันการ Overfit
โมเดลในฝั่งออนไลน์
ในฝั่งของด้านออนไลน์นั้น การตรวจสอบความผิดพลาดเป็นส่วนสำคัญ เพราะมันคือสิ่งที่ลูกค้าจะเห็นแล้วเน็ตฟลิกซ์ได้ทำการเช็คค่าที่ควรจะคงที่ ยกตัวอย่างเช่น ค่าความน่าจะเป็น (Probability) ที่ไม่ควรมากกว่า 1 หรือในกรณีที่ Output ของโมเดลเป็น NaN หรือ infinity ซึ่งกรณีพวกนี้จะเกิดขึ้นได้โดยการมี Unexpected Change, Bad Assumption หรือ Engineering Issue ดังนั้นจึงควรต้องมีการตั้ง เงื่อนไขเพื่อป้องกันการนำโมเดลที่มีข้อบกพร่องไปใช้กับลูกค้า
หลังจากนั้นส่วนหลักจะเป็นการเก็บผลลัพธ์ดูว่าตัวโมเดลที่ทางเน็ตฟลิกซ์ได้ Deploy ไปนั้นดีแค่ไหนโดยการดูว่าสิ่งที่แนะนำไป สมาชิกถูกใจหรือเปล่า เมื่อเก็บผลมาได้แล้วก็จะมา Evaluate ตัวโมเดลกันซึ่งหากโมเดลปัจจุบันไม่สามารถทำงานได้ดี จะได้ดำเนินการแก้ไข เช่นการดึงโมเดลตัวเก่ามาใช้ไปพลาง แล้วค่อยมาหาสาเหตุว่าทำไมโมเดลถึงมี Performance ที่ต่ำลง อาจเป็นเพราะข้อมูลที่ใช้ Train มีการเปลี่ยนแปลง หรือข้อมูลที่ใช้ Train มีอายุที่เก่าเกินไปสำหรับพฤติกรรมการดูในปัจจุบัน จากตัวอย่างนี้จะเห็นได้ชัดว่าเน็ตฟลิกซ์ได้มีการวางแผนที่รอบคอบในการป้องกันความผิดพลาดเชิงเทคนิคต่าง ๆ ที่อาจเกิดขึ้นเมื่อไรก็ได้
การใช้ข้อมูลทำให้เน็ตฟลิกซ์ทราบว่าควรผลิต Content หรือออก Promotion อะไร
การใช้ข้อมูลให้เกิดผลประโยชน์มากที่สุด เป็นสิ่งที่เน็ตฟลิกซ์กำลังทำ และ ทำได้ดีอีกด้วย การใช้ข้อมูลของเน็ตฟลิกซ์ไม่ได้แค่สร้างความพึงพอใจให้กับสมาชิก แต่ยังสามารถทราบได้ว่าควรจะสร้างเนื้อหา (Content) หนังอะไร หรือออกโปรโมชันต่าง ๆ ที่เกี่ยวข้องกับแพลตฟอร์ม แน่นอนว่าตอนนี้หลาย ๆ บริษัท หลาย ๆ วงการเริ่มใช้ข้อมูลในการประกอบการตัดสินใจต่าง ๆ ถ้าเพื่อน ๆ ยังไม่สามารถใช้ข้อมูลให้เกิดประโยชน์มากที่สุดโดยเร็ว อาจเสียเปรียบให้กับคู่แข่งที่เล็งเห็นการใช้ข้อมูลให้เกิดประโยชน์ก็เป็นได้
แหล่งที่มา: https://www.slideshare.net/justinbasilico/making-netflix-machine-learning-algorithms-reliable








