

ทุกวันนี้ Large Language Models (LLMs) ถูกนำมาใช้กันอย่างแพร่หลายมากขึ้นในปัจจุบัน หลายคนถือว่า LLMs ถูกผนวกรวมเป็นส่วนหนึ่งของชีวิตและการทำงานของเราอย่างขาดไม่ได้ แต่อย่างไรก็ตาม การประยุกต์ใช้งาน LLMs ก็ยังพบปัญหาและอุปสรรคบางอย่างอยู่ เช่น ปัญหาของการสร้างคำตอบที่ไม่ถูกต้องขึ้นมา (Hallucination) หรือปัญหาของชุดความรู้ที่ไม่อัปเดต ทำให้มีคนที่พยายามคิดค้นและพัฒนากระบวนการที่จะมาช่วยแก้ปัญหาตรงจุดนี้ ซึ่งวิธีที่จะมาช่วยแก้ปัญหาดังกล่าว เรียกว่า Retrieval-Augmented Generation (RAG)
RAG คืออะไร
Retrieval-Augmented Generation (RAG) คือ เทคนิคที่จะมาช่วยแก้ปัญหาต่าง ๆ ที่เป็นข้อจำกัดของ LLMs ในปัจจุบัน เพื่อให้ LLMs มีความถูกต้องและความน่าเชื่อถือมากยิ่งขึ้น โดยมีกระบวนการในการผนวกชุดความรู้จากแหล่งข้อมูลภายนอก (External Source) มาใช้ประกอบในกระบวนการสร้างข้อความผลลัพธ์ ซึ่งการใช้ RAG จะช่วยเพิ่มความถูกต้องและความน่าเชื่อถือของผลลัพธ์ที่ได้จาก LLMs โดยเฉพาะงานที่ต้องใช้ความรู้ที่เฉพาะเจาะจงมาก ๆ รวมถึงยังมีข้อดีที่ทำให้ผลลัพธ์ของ LLMs สามารถตอบคำถามจากการอ้างอิงชุดความรู้ที่มีการอัปเดตให้เป็นปัจจุบันได้โดยไม่ต้องทำการฝึกฝนหรือ Fine-tuning LLMs ใหม่เรื่อย ๆ โดย RAG นั้นประกอบไปกระบวนหลัก 3 ขั้นตอน ได้แก่ 1.) การสืบค้นเนื้อหาที่เกี่ยวข้อง (Retrieve) 2.) การเพิ่มเนื้อหาเข้าไปใน Prompt (Augment) และ 3.) การสร้างข้อความผลลัพธ์ (Generate) ซึ่งมีรายละเอียดของกระบวนการดังต่อไปนี้
RAG Workflow
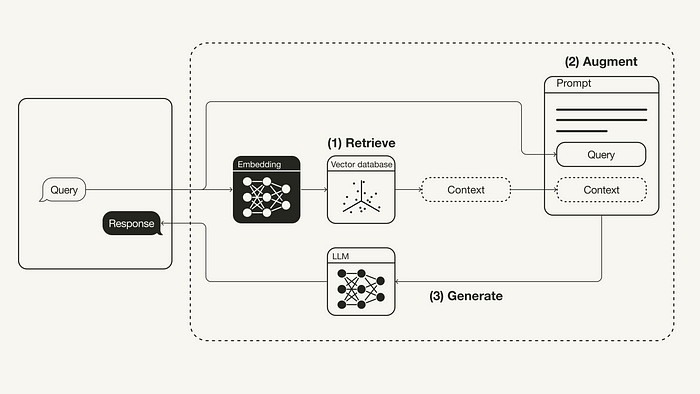
- Retrieve: ข้อความค้นหา (Query) ของผู้ใช้ จะถูกนำไปใช้ในการสืบค้นเนื้อหาที่เกี่ยวข้องจากแหล่งข้อมูลภายนอก (External Knowledge Source) ในขั้นตอนนี้ query ของผู้ใช้จะถูกแปลงให้กลายเป็น vector ผ่าน embedding model เพื่อนำไปเปรียบเทียบเพื่อค้นหา vector ที่มีความคล้ายมากที่สุดใน vector database
- Augment: query ของผู้ใช้ และเนื้อหาเพิ่มเติมที่ได้มาจากขั้นตอนการ retrieve จะถูกนำไปใส่ใน template ของ prompt
- Generate: สุดท้าย prompt ที่ได้จากการดึงข้อมูลเนื้อหาเสริมมาประกอบจะถูกป้อนเป็น input ให้แก่ LLM ต่อไป
ข้อจำกัดของ RAG ทั่วไป
ถึงแม้การใช้ RAG ใน LLMs จะช่วยให้ผลลัพธ์ที่ได้มีความถูกต้องมากขึ้น โดยการดึงข้อมูลสนับสนุนที่เกี่ยวข้องมาเป็นบริบทเพิ่มเติมสำหรับสร้างคำตอบที่เฉพาะเจาะจงขึ้น แต่อย่างไรก็ตาม บางกรณีการดึงข้อมูลที่ไม่เกี่ยวข้องออกมาใช้ อาจจะด้วยเหตุผลที่ว่าในแหล่งข้อมูลภายนอกที่ใช้อ้างอิงไม่มีเนื้อหาที่เกี่ยวข้องอยู่เลย หรืออาจจะเป็นที่ อัลกอริทึมของการสืบค้น (Retrieve) ไม่ดีเพียงพอ สิ่งเหล่านี้ก็มีผลทำให้ผลลัพธ์ที่ได้จาก LLMs แทนที่จะดีขึ้นกลับแย่ลงกว่าเดิมก็เป็นได้ เนื่องจาก RAG อาจทำให้ไปลดความสามารถในการตอบคำถามแบบ general ที่มีอยู่เดิมของ LLMs ที่ใช้ ด้วยเหตุนี้ Self-RAG จึงถูกพัฒนาขึ้นมาเพื่อมาช่วยปรับปรุงคุณภาพและความถูกต้องของผลลัพธ์ที่ได้จาก LLMs และไม่ทำให้ความสามารถที่มีอยู่เดิมของ LLMs หายไป ผ่านแนวคิด On-demand Retrieval และ Self-reflection
Self-RAG
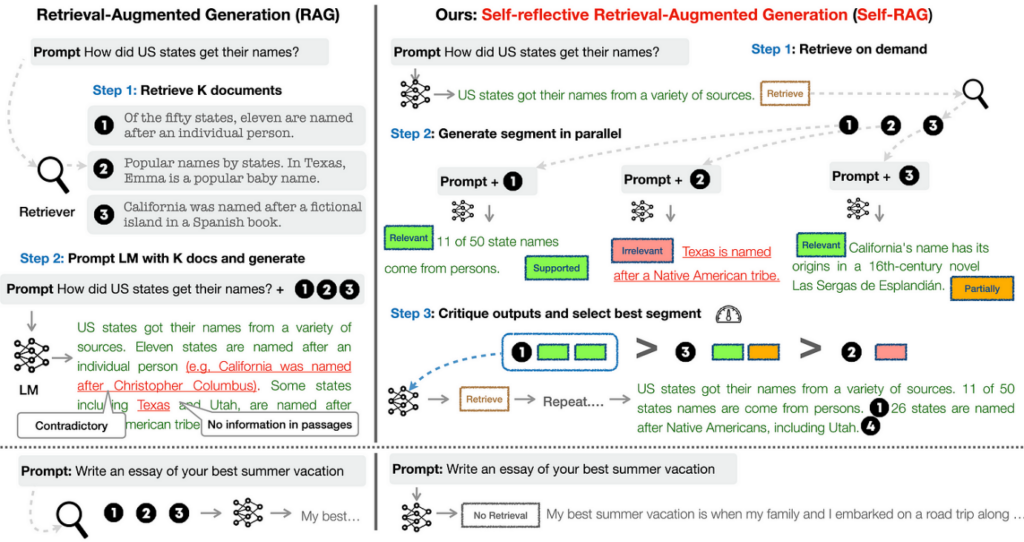
Self-RAG (Self-Reflective Retrieval-Augmented Generation) เป็น Framework เช่นเดียวกับ RAG ที่มีการเพิ่มส่วนของการพิจารณาไตร่ตรองผลลัพธ์ของตนเอง (Self-reflection) เพื่อตัดสินใจว่าจะทำการสืบค้นข้อมูลเพิ่มเติมหรือไม่ (On-demand Retrieval) หรือจะข้ามการสืบค้นและใช้ผลลัพธ์ที่ได้จาก LLMs เลย ด้วยวิธีการนี้จะช่วยปรับปรุงผลลัพธ์จาก LLMs ให้มีคุณภาพและตรงตามความเป็นจริงมากยิ่งขึ้น โดย LLMs ที่ประยุกต์ใช้วิธีการนี้จะถูกฝึกฝนให้มีการสร้าง special token ที่ชื่อว่า “Reflection Token” ซึ่งเป็นผลที่ได้จากการพิจารณาว่า ควรดำเนินการอย่างไรกับผลลัพธ์ที่สร้างมาจาก LLMs เพื่อให้สามารถควบคุม และปรับการทำงานให้เหมาะสมเพิ่มเติม ผ่านการพิจารณา Reflection Token ที่ได้
Reflection Token สามารถแบ่งได้เป็น 2 ประเภทหลัก ได้แก่ “Retrieval Token” และ “Critique Token” โดย Retrieval Token จะเป็น Token ที่แสดงความจำเป็นของการสืบค้น หรือการตัดสินใจว่าจะทำการสืบค้นหรือ Retrieve ข้อมูลมาใช้เป็นเนื้อหาเพิ่มเติมใน prompt หรือไม่ ส่วน Critique Token จะเป็น Token ที่แสดงผลการวิเคราะห์คุณภาพของข้อความที่ถูกสร้างขึ้นมา เช่น ดูเนื้อหาของข้อความผลลัพธ์ที่ได้จาก LLMs ว่ามีความเกี่ยวข้องกับคำถามมากน้อยขนาดไหน ซึ่ง Critique Token ประกอบไปด้วย Token ย่อย 3 กลุ่ม ได้แก่ IsREL, IsSup, IsUse Tokens ดังแสดงในตารางด้านล่าง

การทำงานของ Self-RAG แบ่งเป็น 3 ขั้นตอนหลัก ได้แก่ 1) ดึงข้อมูล (Retrieve) 2) สร้าง (Generate) และ 3) วิจารณ์ (Critique) โดยมีรายละเอียดแต่ละขั้นดังต่อไปนี้
ขั้นตอนที่ 1 Retrieve on demand

จากภาพจะเห็นว่า หลังจากที่เราให้ input prompt กับ LLM ซึ่งโดยปกติ LLM จะให้ผลลัพธ์ออกมาเป็นข้อความที่ตอบคำถามที่เราใส่เข้าไปเท่านั้น แต่ในครั้งนี้ LLM จะถูกฝึกฝนมาให้สามารถทำการสร้าง Reflection Token ต่อท้ายข้อความได้ ซึ่ง Reflection Token ในตัวอย่างด้านบนนี้จะเป็นประเภท Retrieval Token ซึ่งจะเป็น token ที่บอกว่าการ retrieve ข้อมูลเพื่อใช้เป็นเนื้อหามา support เพิ่มน่าจะมีประโยชน์หรือไม่ ซึ่งถ้า Retrieval Token มีค่าเป็น yes โมเดลสำหรับทำการสืบค้น (Retriever Model) จะถูกเรียกเพื่อไปทำการสืบค้นเนื้อหาที่เกี่ยวข้องในฐานข้อมูลเป็นลำดับถัดไป
ขั้นตอนที่ 2 Generate segment in parallel
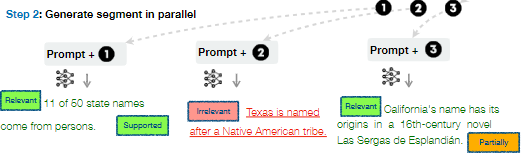
หลังจากที่ Retriever Model ทำการสืบค้นเนื้อหาหรือข้อความที่มีความเกี่ยวข้องขึ้นมา k อันดับแรก (Top k) ข้อความเหล่านั้นจะถูกนำไปใช้ประกอบรวมเพื่อเป็นบริบท (Context) ให้กับ prompt ตั้งต้น แล้วใส่เป็น input ให้กับ LLM เพื่อสร้างข้อความผลลัพธ์ออกมา ซึ่งผลลัพธ์ที่ได้จาก LLM ในรอบนี้จะมี Critique Token กำกับมาเพิ่มด้วยดังภาพ โดยเป็นการวัดคุณภาพของเนื้อหาที่ถูกสร้างจาก input context ที่ต่างกัน เพื่อวัดความเกี่ยวข้องของคำตอบที่ได้และความครบถ้วนหรือความครอบคลุมของคำตอบที่ได้ จากตัวอย่างจะเห็นว่าการใช้ context หมายเลข 1 จะได้ผลลัพธ์ที่เกี่ยวข้องกับคำถาม และครอบคลุมคำถามมากที่สุด
ขั้นตอนที่ 3 Critique output and select best segment

ขั้นตอนสุดท้ายเป็นการนำผลลัพธ์ที่ได้จากขั้นตอนที่ 2 นั่นก็คือ ข้อความที่มี Critique Token กำกับของทุก output ที่สร้างมาจาก LLM ที่ได้จากการใส่ input context ที่ต่างกัน มาทำการเปรียบเทียบเพื่อเลือกผลลัพธ์ที่ดีที่สุดมาใช้ ซึ่งจากในตัวอย่างคือผลลัพธ์ที่ได้จากการใช้ context หมายเลข 1 จากนั้นผลลัพธ์ที่ถูกเลือกจะถูกนำมาใส่ LLM เพื่อทำการสร้างข้อความและ Retrieval Token อีกครั้ง เพื่อพิจารณาว่าควรจะมีการสร้างเนื้อหาต่อหรือไม่ ซึ่งจะทำเช่นนี้ซ้ำไปเรื่อย ๆ จนกว่าผลของ Retrieval Token จะมีค่าเป็น No ก็คือไม่จำเป็นต้องมีการไป Retrieve ข้อมูลเพิ่มอีกแล้ว ข้อความผลลัพธ์ทั้งหมดก็จะสิ้นสุดเพียงแค่นี้
โดยสรุป Self-RAG ถือเป็นวิธีการหนึ่งที่น่าสนใจในการนำมาประยุกต์ใช้เพื่อช่วยปรับปรุงผลลัพธ์ของ LLM ให้ดีขึ้น และช่วยแก้ข้อจำกัดของการใช้ RAG แบบธรรมดาที่ไม่ได้มีการพิจารณาประโยชน์ของการนำข้อมูลจากการสืบค้นมาใช้ อย่างไรก็ตาม ผลลัพธ์ที่ดีขึ้นจากวิธีการนี้ ยังคงต้องแลกมาด้วยประสิทธิภาพและความซับซ้อนของกระบวนการที่มีขั้นตอนเยอะขึ้นด้วยนั่นเอง
บทความโดย กัญญาวีร์ พรสว่างดี
ทบทวนและปรับปรุงโดย อิสระพงศ์ เอกสินชล
เอกสารอ้างอิง
- https://arxiv.org/pdf/2310.11511.pdf
- https://selfrag.github.io/
- https://medium.com/emalpha/innovations-in-retrieval-augmented-generation-8e6e70f95629
- https://blogs.nvidia.com/blog/what-is-retrieval-augmented-generation/
Project Manager & Data Scientist
Big Data Institute (Public Organization), BDI




Senior Project Manager & Data Scientist at Big Data Institute (Public Organization), BDI








