
ในยุคปัจจุบัน ข้อมูลที่เราสามารถนำมาใช้ประโยชน์ได้มีอยู่ปริมาณมหาศาลจากหลากหลายแหล่งที่มา ไม่ว่าจะเป็นข้อมูลที่ถูกเก็บภายในองค์กร ข้อมูลที่ถูกเก็บจากเซนเซอร์ หรือข้อมูลที่มาจากอินเทอร์เน็ต ในบรรดาข้อมูลหลากหลายรูปแบบเหล่านี้ ข้อมูลที่มีลักษณะเป็นข้อความถือเป็นข้อมูลชนิดหนึ่งที่มีอยู่เป็นจำนวนมาก โดยเฉพาะข้อมูลจากสื่อสังคมออนไลน์ต่างๆ ไม่ว่าจะเป็นเว็บไซต์หรือโซเชียลมีเดีย ถ้าหากเราสามารถนำข้อมูลประเภทนี้มาวิเคราะห์เพื่อใช้งานจะสามารถก่อให้เกิดประโยชน์ได้อย่างมหาศาล
จุดสำคัญหนึ่งที่ทำให้ข้อมูลชนิดข้อความแตกต่างจากข้อมูลที่มีโครงสร้างอย่างชัดเจน (เช่น ข้อมูลที่ถูกเก็บในฐานข้อมูล) นั้น คือข้อมูลในรูปแบบข้อความมีรูปแบบและความยาวที่หลากหลาย ส่งผลให้ข้อมูลชนิดข้อความถูกนำมาวิเคราะห์ได้ยากกว่ามาก ดังนั้นความสามารถในการสกัดเอาข้อมูลที่สำคัญออกมาจากจากข้อความ (Text Mining) ได้จึงเป็นสิ่งที่สำคัญและเป็นประโยชน์อย่างมาก ในบทความนี้เราจะพูดถึงเทคนิคพื้นฐานเทคนิคหนึ่งที่ใช้ในการวิเคราะห์ค้นหาคำสำคัญของข้อมูลในลักษณะของข้อความที่ชื่อว่า Term Frequency – Inverse Document Frequency (TF-IDF).
Term Frequency – Inverse Document Frequency เป็นเทคนิคที่พิจารณาองค์ประกอบของคำภายในประโยค (และเอกสาร) เป็นหลักโดยจะไม่นำลำดับของคำภายในเอกสารมาใช้วิเคราะห์ประกอบด้วย
เทคนิคนี้มีอยู่ 2 องค์ประกอบด้วยกันคือ Term Frequency (TF) และ Inverse document Frequency (IDF) ซึ่งมีที่มาจากสองไอเดียหลักๆ ต่อไปนี้
* การคำนวณค่าของทั้ง TF และ IDF นั้น มีหลายรูปแบบ สิ่งที่เลือกมานำเสนอ ณ ที่นี้จะเป็นรูปแบบพื้นฐานของทั้งสองค่า (แต่การคำนวณในรูปแบบอื่นๆนั้นก็จะมีลักษณะคล้ายคลึงกัน)
Term-Frequency (TF)
ไอเดียแรกคือ “ถ้าหากคำคำไหนถูกพูดถึงอยู่บ่อยๆ ในเอกสารนั้นๆ จะมีความเป็นไปได้สูงว่าคำนั้นมีความเกี่ยวข้องกับใจความสำคัญของเอกสารนั้นๆ มาก” เช่น ถ้าหากเราเลือกที่จะพิจารณาบทความเกี่ยวกับกาแฟ เราอาจจะเห็นคำว่า “กาแฟ” และ “ชง” หลายครั้งภายในบทความนั้น ค่าของ Term Frequency เป็นค่าที่บอกความถี่ของคำแต่ละคำที่ปรากฏในเอกสารเอกสารหนึ่ง โดยคิดคำนวณจากการนำจำนวนครั้งที่คำนั้นๆ ปรากฏในเอกสารมาหารด้วยจำนวนคำทั้งหมดในเอกสาร

เพื่อแสดงการตัวอย่างการคำนวณค่า TF (รวมถึง ค่า IDF และ TF-IDF ในตัวอย่างต่อๆไป) เราจะใช้เอกสาร 2 เอกสารด้านล่างซึ่งแต่ละเอกสารจะมีเพียงประโยคเดียวเท่านั้น
- เอกสารที่ 1: A nose print of a dog is unique the same way fingerprints of a human being are unique.
- เอกสารที่ 2: A human nose has five million scent receptors, while a dog nose has up to three hundred million receptors.
เนื่องจากเอกสารที่ 1 ประกอบด้วยคำทั้งหมด 18 คำ ดังนั้นเราสามารถคำนวณค่า Term Frequency ของคำแต่ละคำได้ดังต่อไปนี้
| คำ | จำนวนคำ | Term-Frequency (TF) |
|---|---|---|
| a | 3 | 3/18 |
| nose | 1 | 1/18 |
| 1 | 1/18 | |
| of | 2 | 2/18 |
| dog | 1 | 1/18 |
| is | 1 | 1/18 |
| unique | 2 | 2/18 |
| the | 1 | 1/18 |
| same | 1 | 1/18 |
| way | 1 | 1/18 |
| fingerprints | 1 | 1/18 |
| human | 1 | 1/18 |
| being | 1 | 1/18 |
| are | 1 | 1/18 |
สำหรับเอกสารที่ 2 (ประกอบด้วยคำทั้งหมด 19 คำ) นั้น เราก็สามารถทำการคำนวณค่า Term Frequency ได้แบบเดียวกัน
อย่างไรก็ตาม การที่ใช้คำที่ปรากฏบ่อยๆ เพียงอย่างเดียวเพื่อหาใจความสำคัญของข้อความนั้นอาจยังไม่ดีพอ ยกตัวอย่างเช่นในกรณีที่เรามีหลายเอกสารในหมวดหมู่เดียวกัน เราต้องการคำที่สามารถแยกแยะเอกสารแต่ละชิ้นออกจากกันได้ด้วย (เช่นในกรณีที่เราต้องการหาใจความสำคัญของบทความเกี่ยวกับปลาทะเล เราคงไม่ต้องการให้คำสำคัญที่สุดของทุกบทความที่หามาได้เป็นคำว่า “ปลา”,”ทะเล” หรือ ”ว่าย” ไปทั้งหมด) ดังนั้นคำที่ถูกเลือกมาว่าเป็นคำที่มีความสำคัญที่สุดต่อความหมายของบทความนั้นควรจะเป็นคำที่ปรากฏอยู่ในเอกสารจำนวนไม่มากในบรรดาเอกสารทั้งหมดที่เรานำมาวิเคราะห์ ความต้องการในจุดนี้ทำให้ไอเดียของ Invert Document Frequency (IDF) ถูกนำมาใช้ในลำดับถัดมา
Inverse Document Frequency (IDF)
IDF เป็นการคำนวณค่าน้ำหนัก (weight) ความสำคัญของแต่ละคำโดยจะคำที่พบเจอได้บ่อยๆ (ในหลายๆเอกสาร) จะมีค่า IDF ต่ำ ซึ่งบ่งบอกว่าคำเหล่านั้นจะไม่สามารถดึงเอาจุดเด่นของเอกสารที่คำเหล่านั้นปรากฏอยู่ออกมาได้ดี ค่า IDF สามารถคำนวณได้ด้วยสมการ

สำหรับตัวอย่างการคำนวณค่า IDF นั้น เราจะใช้ตัวอย่างเอกสารชุดเดียวกับตัวอย่างการคำนวณ ค่า TF ด้านบน
เมื่อพิจารณาเอกสารที่ 1 เราพบว่าคำว่า a, nose, dog, human ปรากฏอยู่ในเอกสารที่ 2 ด้วย ดังนั้นเราจึงสามารถคำนวณค่า IDF ได้ดังต่อไปนี้
| [latexpage]คำ | จำนวนเอกสารที่ปรากฏ | Inverse Document Frequency (IDF) |
|---|---|---|
| a | 2 | $\log{(\frac{2}{2})} = 0$ |
| nose | 2 | $\log{(\frac{2}{2})} = 0$ |
| 1 | $\log{(\frac{2}{1})} \approx 0.3$ | |
| of | 1 | $\log{(\frac{2}{1})} \approx 0.3$ |
| dog | 2 | $\log{(\frac{2}{2})} = 0$ |
| is | 1 | $\log{(\frac{2}{1})} \approx 0.3$ |
| unique | 1 | $\log{(\frac{2}{1})} \approx 0.3$ |
| the | 1 | $\log{(\frac{2}{1})} \approx 0.3$ |
| same | 1 | $\log{(\frac{2}{1})} \approx 0.3$ |
| way | 1 | $\log{(\frac{2}{1})} \approx 0.3$ |
| fingerprints | 1 | $\log{(\frac{2}{1})} \approx 0.3$ |
| human | 2 | $\log{(\frac{2}{2})} = 0$ |
| being | 1 | $\log{(\frac{2}{1})} \approx 0.3$ |
| are | 1 | $\log{(\frac{2}{1})} \approx 0.3$ |
เช่นเดียวกับตัวอย่างด้านบน ค่า IDF ของคำในเอกสารที่ 2 ก็สามารถทำการคำนวณได้ด้วยวิธีเดียวกัน
คำนวณค่า TF-IDF
เมื่อนำการคำนวณทั้งสองส่วนมารวมกัน เราจะได้การคำนวณ TF-IDF ดังต่อไปนี้
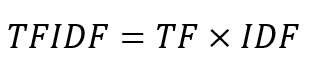
เพราะฉะนั้นค่า TF-IDF ของแต่ละคำในเอกสารที่ 1 ถูกคำนวณได้ดังต่อไปนี้ได้ดังต่อไปนี้
| [latexpage]คำ | TF | IDF | TF-IDF = TF$\times$IDF |
|---|---|---|---|
| a | 3/18 | 0 | 0 |
| nose | 1/18 | 0 | 0 |
| 1/18 | 0.3 | 0.0167 | |
| of | 2/18 | 0.3 | 0.333 |
| dog | 1/18 | 0 | 0 |
| is | 1/18 | 0.3 | 0.0167 |
| unique | 2/18 | 0.3 | 0.333 |
| the | 1/18 | 0.3 | 0.0167 |
| same | 1/18 | 0.3 | 0.0167 |
| way | 1/18 | 0.3 | 0.0167 |
| fingerprints | 1/18 | 0.3 | 0.167 |
| human | 1/18 | 0 | 0 |
| being | 1/18 | 0.3 | 0.0167 |
| are | 1/18 | 0.3 | 0.0167 |
และ ของเอกสารที่ 2 ถูกคำนวณได้ดังต่อไปนี้ได้ดังต่อไปนี้
| [latexpage]คำ | TF | IDF | TF-IDF = TF$\times$IDF |
|---|---|---|---|
| a | 2/19 | 0 | 0 |
| human | 1/19 | 0 | 0 |
| nose | 2/19 | 0 | 0 |
| has | 2/19 | 0.3 | 0.0316 |
| five | 1/19 | 0.3 | 0.0158 |
| million | 2/19 | 0.3 | 0.0316 |
| scent | 1/19 | 0.3 | 0.0158 |
| receptors | 2/19 | 0.3 | 0.0316 |
| while | 1/19 | 0.3 | 0.0158 |
| dog | 1/19 | 0 | 0 |
| up | 1/19 | 0.3 | 0.0158 |
| to | 1/19 | 0.3 | 0.0158 |
| three | 1/19 | 0.3 | 0.0158 |
| hundred | 1/19 | 0.3 | 0.0158 |
จากผลลัพธ์ที่ได้จะเห็นว่าคำที่ปรากฏอยู่ในทั้งสองเอกสาร ถึงแม้ว่าจะมีค่า TF ที่สูง เมื่อนำมาคิดค่า TF-IDF แล้วนั้นถูก weight ให้ต่ำลง (ในกรณีนี้ถูกเปลี่ยนเป็น 0) เนื่องจากคำเหล่านี้ไม่สามารถที่จะช่วยแยกแยะใจความสำคัญของข้อความของทั้งสองเอกสารออกจากกันได้ดีเพราะปรากฏอยู่ในทุกเอกสารนั่นเอง คำที่มีค่า TF-IDF สูงของแต่ละเอกสารนั้นจะเป็นคำที่มีความสำคัญสูง (ถูกกล่าวถึงบ่อยที่สุดและไม่ได้ปรากฏอยู่หลายเอกสารเกินไป) และมีแนวโน้มที่จะเป็นใจความสำคัญของเอกสาร
ในตัวอย่างนี้ เราอาจจะเห็นว่ามีความบางคำที่มีค่า TF-IDF สูงแต่ไม่ได้บ่งบอกถึงลักษณะของข้อความในเอกสารเช่นคำว่า of, has, หรือ million ปนอยู่ด้วย อันที่จริงแล้วคำเหล่านี้ถูกจัดว่าเป็น “stop words” ซึ่งเป็นคำที่ปรากฏอยู่ทั่วไปในภาษาอังกฤษและมักไม่สื่อความหมายถึงนัยสำคัญของข้อความ โดยปกติแล้ว คำเหล่านี้มักถูกกรองออกก่อนที่จะมีการนำข้อความมาทำการประมวลผลทางภาษา อย่างไรก็ดีโดยปกติแล้วนั้นต่อให้คำเหล่านี้จะไม่ถูกกรองออกก่อน เนื่องด้วยเรามักจะพบคำเหล่านี้ในเอกสารต่างๆอยู่เสมอ เมื่อนำคำจากเอกสารต่างๆมาคำนวณหาค่า TF-IDF แล้ว คำเหล่านี้ส่วนมากจะถูกค่า IDF ปรับ ให้มีค่าต่ำลงมากจนไม่ปรากฏเป็นคำสำคัญของเอกสารอยู่ดี สาเหตุที่เรายังเห็นคำเหล่านี้มีค่า TF-IDF ที่สูงในตัวอย่างนี้นั้นเกิดมาจากเราทำการพิจารณาเอกสารทั้งหมดเพียงแค่ 2 เอกสาร ซึ่งแต่ละเอกสารมีเพียงแค่ประโยคเดียวเท่านั้น
ในบทความต่อไปเราจะมาทำการเขียนโปรแกรมอย่างง่ายๆเพื่อลองใช้งาน TF-IDF กันดูครับ








