ในยุคของการวิเคราะห์ข้อมูลขนาดใหญ่ในปัจจุบัน การประมวลผลภาษาธรรมชาติ (natural language processing) ก็เป็นแขนงหนึ่งที่มีการใช้งานมากมาย ไม่ว่าจะเป็นการพัฒนาระบบแนะนำ (recommendation system) เครื่องมือที่ถูกพัฒนาขึ้นมาเพื่อช่วยตอบคำถามอัตโนมัติ (chatbot) หรือการแปลภาษาโดยอัตโนมัติ (machine translation) ซึ่งในการพัฒนาระบบเหล่านี้ก็จะต้องใช้ข้อมูลในลักษณะของข้อความจำนวนมหาศาล ซึ่งเรียกกันว่า คลังข้อความ หรือ corpus
คลังข้อความ (corpus) จะถูกจัดเก็บในรูปแบบข้อมูลเชิงโครงสร้างตามบริบทของหัวข้อเรื่องของคลังข้อความนั้น ๆ อาจเป็นภาษาเดียวหรือหลายภาษาก็ได้ สำหรับคลังข้อความที่มีประโยชน์ต่อการวิจัยและพัฒนาโมเดลทางด้านการประมวลผลภาษา จะมีการกำกับทางภาษาศาสตร์ เช่น ชนิดของคำในข้อความ (คำนาม คำกริยา หรือคำวิเศษณ์) เป็นต้น
ตัวอย่างคลังข้อความที่รู้จักกันเป็นอย่างดี อาทิ IMDb Movie Reviews ซึ่งเป็นคลังข้อความที่รวบรวมความเห็นภาพยนตร์พร้อมมีการกำกับแต่ละความเห็นว่าเป็นเชิงบวกหรือเชิงลบ และ GLUE (General Language Understanding Evaluation benchmark) ซึ่งเป็นคลังข้อความทดสอบทางด้านการเข้าใจภาษาธรรมชาติในภาษาอังกฤษ หากสนใจเพิ่มเติมสามารถเข้าไปดูได้ที่นี่ อย่างไรก็ตาม หากท่านต้องการโมเดลด้านการประมวลผลภาษาไทย ท่านก็ควรใช้คลังข้อความภาษาไทย ซึ่งผู้เขียนได้รวบรวมไว้ในตามตารางที่ 1
ตัวอย่างคลังข้อความภาษาไทยในปัจจุบัน
| ชื่อคลังข้อความ | รายละเอียด | ผู้พัฒนา |
|---|---|---|
| Thai National Corpus | คลังคำศัพท์พร้อมค่าความถี่จากการประมวลผลข้อมูลจำนวน 33 ล้านคำ | [1] |
| Thai Textbook Corpus | คลังข้อมูลหนังสือเรียนวิชาภาษาไทยในระดับชั้นเริ่มเรียนจนถึงมัธยมศึกษาปีที่ 6 จากหลักสูตรปีพ.ศ. 2503 – 2544 | [1] |
| Volubilis dictionary | คลังคำศัพท์ไทย-อังกฤษ-ฝรั่งเศส ประกอบด้วยคำศัพท์ ชนิดของคำ และการอ่านออกเสียง | [2] |
| Lexitron 2.0 | คลังคำศัพท์ไทย-อังกฤษ ประกอบด้วยคำศัพท์ ชนิดของคำ คำแปล คำเหมือน และประโยคตัวอย่างการใช้งาน | [3] |
| BEST 2010 | คลังข้อความภาษาไทยที่มีการกำกับขอบเขตของคำจากข้อมูลรวมจำนวน 5 ล้านคำ | [3] |
| Thai Plagiarism | ชุดข้อมูลเอกสารที่มีการคัดลอก ซึ่งเป็นการจำลองการสร้างข้อความที่มีการคัดลอกด้วยคน โดยใช้บทความวิกิพีเดียภาษาไทยและเว็บเพจเป็นฐานข้อมูล | [3] |
| Thai WIKI QA | คลังข้อมูลที่ใช้ในการแข่งขันพัฒนาโปรแกรมถามตอบจากคลังข้อมูลวิกิพีเดีย ประกอบด้วย คำถามที่เป็นข้อเท็จจริง คำถามตอบรับหรือปฏิเสธ และคลังข้อมูลวิกิพีเดียภาษาไทยที่ใช้ในการสร้างคู่คำถาม | [3] |
| ชุดข้อมูลคู่ประโยคภาษาอังกฤษ-ไทย กว่า 1 ล้านคู่ประโยค | ชุดข้อมูลคู่ประโยคนี้ ได้รวบรวมจากหลายข้อมูลแหล่ง อาทิ ประโยคจากบทสนทนา ข้อมูลจากเว็บไซต์ข่าวหรือองค์กรที่มีเนื้อหาในสองภาษา บทความวิกิพีเดีย และเอกสารราชการ | [4] |
ผู้พัฒนา: [1] คณะอักษรศาสตร์ จุฬาลงกรณ์มหาวิทยาลัย [2] Belisan Volubilis [3] ศูนย์เทคโนโลยีอิเล็กทรอนิกส์และคอมพิวเตอร์แห่งชาติ (เนคเทค) [4] สถาบันวิจัยปัญญาประดิษฐ์ประเทศไทย
เนื่องจากแต่ละคลังข้อความถูกพัฒนามาจากข้อมูลตั้งต้นที่ต่างกัน ทำให้แต่ละคลังข้อความเหมาะกับโมเดลการประมวลผลภาษาธรรมชาติที่ต่างกันด้วย เช่น หากท่านต้องการพัฒนาโมเดลการแปลภาษา (machine translation) ท่านควรใช้ชุดข้อมูลคู่ประโยคภาษาอังกฤษ-ไทย กว่า 1 ล้านคู่ประโยค ร่วมกับข้อมูลพจนานุกรม Volubilis dictionary และ Lexitron 2.0 เป็นต้น
แนะนำคลังข้อความภาษาไทย LST20 Corpus

LST20 Corpus เป็นคลังข้อมูลภาษาไทยพัฒนาโดยเนคเทคตัวล่าสุดที่เปิดให้นำไปใช้งานได้ฟรี สามารถเข้าไปดาวน์โหลดได้ที่เว็บไซต์ AI FOR THAI (ท่านจำเป็นต้องสมัครสมาชิกก่อน) ซึ่งคลังข้อความนี้มีการกำกับด้วยข้อมูลทางภาษา 5 ระดับ ได้แก่
- ขอบเขตของคำ (word boundaries) จำนวน 3 ล้านกว่าคำ สำหรับแก้โจทย์ การตัดคำ (word segmentation)
- ชนิดของคำ (part of speech) ซึ่งแบ่งเป็น คำนาม คำกริยา คำวิเศษณ์ คำสันธาน และอื่น ๆ รวม 16 ประเภท สำหรับแก้โจทย์ การระบุประเภทของคำ (part-of-speech tagging)
- ขอบเขตและชนิดของชื่อเฉพาะ (named entities) จำนวน 280,000 ชื่อเฉพาะ ซึ่งมีการแบ่งเป็น ชื่อบุคคล ชื่อองค์กร ชื่อสถานที่ และอื่น ๆ รวม 10 ประเภท สำหรับแก้โจทย์ การระบุประเภทเฉพาะของคำ (name entity recognition)
- ขอบเขตของประโยคย่อย (clause boundaries) จำนวนเกือบ 250,000 ประโยคย่อย สำหรับแก้โจทย์ การตัดประโยคย่อย (clause segmentation)
- ขอบเขตประโยคใหญ่ (sentence boundaries) จำนวนกว่า 70,000 ประโยคใหญ่ สำหรับแก้โจทย์ การตัดประโยคใหญ่ (sentence segmentation)
เมื่อทำการดาวน์โหลดไฟล์ข้อมูลมาแล้ว ข้อมูลจะถูกแบ่งเป็น 3 โฟลเดอร์ (train, test, eval สำหรับ training, testing และ evaluation) พร้อมแก่การนำไปพัฒนาและวัดผลโมเดลอยู่แล้ว จากรูปด้านล่างเป็นหนึ่งในตัวอย่างข้อมูลในรูปแบบของ CoNLL-2003 format ที่มี 4 คอลัมน์ คือ 1. คำ 2. ชนิดของคำ 3. ชนิดของชื่อเฉพาะ 4. ขอบเขตของประโยคย่อย โดยที่แต่ละแถวจะถูกแบ่งด้วยการเว้นวรรคใหญ่ (tab) ใช้การเว้นบรรทัดสำหรับการแบ่งประโยคย่อย ทั้งนี้หากประโยคย่อยมีการเว้นวรรค ทางเนคเทคใช้ “_” แทนการเว้นวรรคทั่วไป
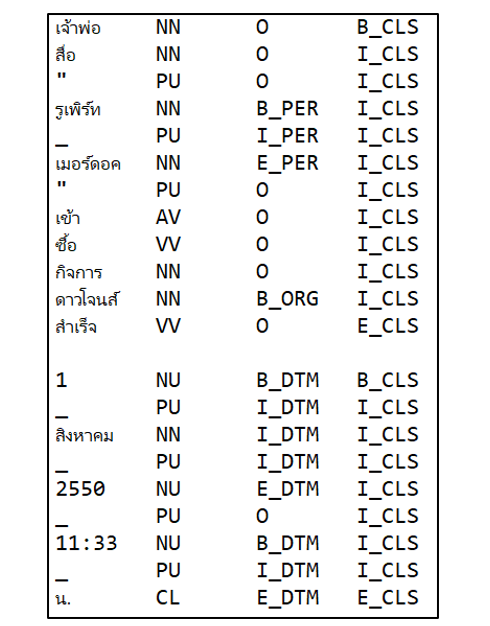
รูปที่ 3 เป็นตัวอย่างข้อความ ซึ่งประกอบไปด้วย 2 ประโยคย่อย โดยประโยคแรก เริ่มต้นด้วยคำว่า “เจ้าพ่อ” ซึ่งเป็นคำนาม (NN) แต่ไม่ใช่ชื่อเฉพาะ (O) และเป็นคำขึ้นต้นประโยคย่อย (B_CLS) มีการกล่าวถึงชื่อเฉพาะบุคคล (B_PER, I_PER, E_PER) ด้วยวลี “รูเพิร์ท เมอร์ดอค” ปิดท้ายด้วยคำว่า “สำเร็จ” ซึ่งเป็นคำกริยา (VV) แต่ไม่ใช่ชื่อเฉพาะ (O) และเป็นคำปิดท้ายประโยคย่อย (E_CLS) สำหรับประโยคที่สองนั้นมีการกล่าวถึงระยะเวลาเจาะจงอยู่ 2 แห่งคือ “1 สิงคาคม 2550” และ “11:33 น.” สำหรับการแปลความของประโยคทั้งหมด สามารถอ่านเพิ่มเติมได้จาก Guideline ของ LST20 Corpus
สำหรับท่านที่ต้องการใช้ python ในการวิเคราะห์และพัฒนาโมเดลต่อยอดจากคลังข้อมูลดังกล่าว ผู้เขียนได้สร้าง code สำหรับการใช้งานเบื้องต้นได้ผ่านทาง Google Colab ของผู้เขียน
เนื้อหาโดย ธนกร ทำอิ่นแก้ว
ตรวจทานและปรับปรุงโดย ดร. นนทวิทย์ ชีวเรืองโรจน์














