
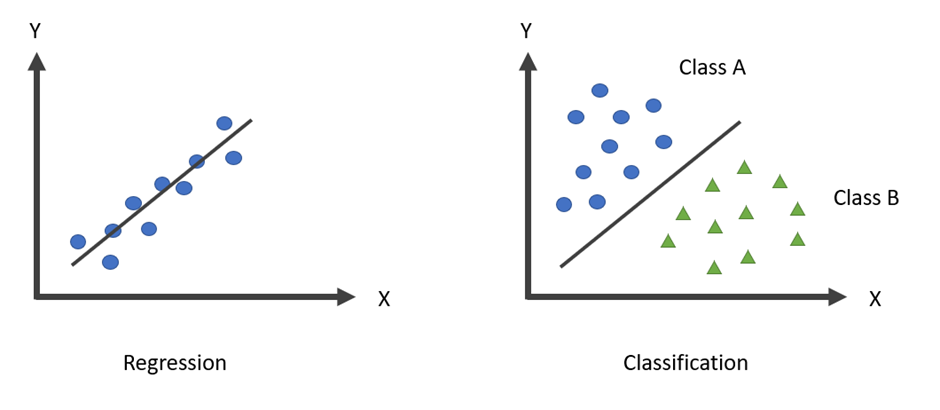
หลาย ๆ ท่าน คงได้ยินแนวทางในการสร้างโมเดลด้วยวิธีการมากมาย แต่หนึ่งในโมเดลพื้นฐานที่ช่วยให้เราสามารถวิเคราะห์ข้อมูลหรือทำนายข้อมูลได้ก็คือ Linear Regression (ตัวแบบการถดถอยเชิงเส้น) ซึ่งจะหมายถึงการหารูปแบบความสัมพันธ์ของตัวแปรต้น (Predictor, Independent Variable, X) และตัวแปรตาม (Response, Dependent Variable, Y) ที่เราสนใจออกมาเป็นสมการทางคณิตศาสตร์ ซึ่งอาจนำมาใช้ในการทำนายข้อมูลหรือใช้วิเคราะห์หาปัจจัยที่สำคัญที่ทำให้เกิดการเปลี่ยนแปลงกับตัวแปรตามได้ โดยความสามารถของโมเดลนี้ สามารถทำได้ทั้งการแก้ไขปัญหาเชิง Regression และ Classification ภายใต้การแจกแจงในรูปแบบที่หลาย เช่น Binomial, Poisson, Inverse Gaussian หรือแม้แต่การแจกแจงแบบปกติ (Normal) เองก็ตาม โดยสามารถแบ่งประเภทของ Regression ออกตามตารางด้านล่างนี้
| ประเภทของ Regression | ลักษณะของตัวแปรตาม | ลักษณะของตัวแปรต้น |
|---|---|---|
| Simple Linear Regression | ข้อมูลเชิงปริมาณที่เป็นค่าต่อเนื่อง 1 ตัว | ข้อมูลเชิงปริมาณที่มีค่าต่อเนื่องหรือ ข้อมูลที่อยู่ในลักษณะของ binary 1 ตัว |
| Multiple Linear Regression | ข้อมูลเชิงปริมาณที่เป็นค่าต่อเนื่อง 1 ตัว | ข้อมูลเชิงปริมาณที่มีค่าต่อเนื่องหรือ ข้อมูลที่อยู่ในลักษณะของ binary รวมกันตั้งแต่ 2 ตัวขึ้นไป |
| Logistic Regression | ข้อมูลที่อยู่ในลักษณะของ binary | ข้อมูลเชิงปริมาณที่มีค่าต่อเนื่องหรือ ข้อมูลที่อยู่ในลักษณะของ binary รวมกันตั้งแต่ 2 ตัวขึ้นไป |
| Ordinal Regression | ข้อมูลเชิงคุณภาพที่มีการเรียงลำดับ | ข้อมูลเชิงคุณภาพที่ไม่มีการเรียงลำดับ หรือ ข้อมูลที่อยู่ในลักษณะของ binary ตั้งแต่ 1 ตัวขึ้นไป |
| Multinomial Regression | ข้อมูลเชิงคุณภาพที่ไม่มีการเรียงลำดับ | ข้อมูลเชิงปริมาณที่มีค่าต่อเนื่องหรือ ข้อมูลที่อยู่ในลักษณะของ binary รวมกันตั้งแต่ 2 ตัวขึ้นไป |
| Discriminant Analysis | ข้อมูลเชิงคุณภาพที่ไม่มีการเรียงลำดับ | ข้อมูลเชิงปริมาณที่มีค่าต่อเนื่อง ตั้งแต่ 1 ตัวขึ้นไป |
เมื่อทราบประเภทของ Linear Regression กันแล้ว ต่อมาเราก็จะมาดูสมการอย่างง่ายของ Linear Regression กัน โดยในที่นี้จะขอยกตัวอย่างจาก Simple Linear Regression นั่นก็คือ
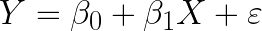
หรือเขียนในรูปของตัวประมาณได้ว่า
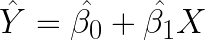
เมื่อขึ้นชื่อว่าเป็นการประมาณการหรือเป็นโมเดลแล้วนั้น ก็ย่อมความมีความคาดเคลื่อนที่เกิดขึ้น เนื่องจากLinear Regression ไม่สามารถลากเส้นตรงผ่านได้ครบทุกจุดได้ และ ความคาดเคลื่อนที่เกิดขึ้นนี้จะเรียกว่า “Residual”
ซึ่งหากเรามองดีๆ ก็จะพบว่า สมการเหล่านี้มีความคล้ายคลึงกับสมการเชิงเส้นเลย
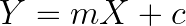
นั่นหมายความว่า โมเดลก็จะมีคุณสมบัติความเป็นเชิงเส้นอยู่ด้วย ดังนั้นถ้าต้องการให้ผลลัพธ์ของโมเดลจะออกมาดีก็ต้องมีข้อมูลที่ดี เช่น มีคุณสมบติความเป็นเชิงเส้น และวิธีการเทรนโมเดลที่ดีด้วย
คำถามคือ แล้วเราจะรู้ได้อย่างไรว่าเราเตรียมข้อมูลดีแล้วหรือยัง? เราก็จำเป็นจะต้องมีเครื่องมือในการตรวจสอบอยู่เสมอ เพื่อปรับปรุงให้ข้อมูลของเราเหมาะสมกับโมเดล และสามารถสรุปผลลัพธ์ของโมเดลออกมาได้อย่างถูกต้องได้ดังนี้
1. การตรวจสอบความเป็นเชิงเส้น (Linearity Assumption)
การตรวจสอบความเป็นเชิงเส้น (Linearity Assumption) ข้อมูลตัวแปรต้น (X) และตัวแปรตาม (Y) ต้องมีความสัมพันธ์เชิงเส้น ไม่เช่นนั้นอาจทำให้เกิดการทำนายด้วย Linear Regression ที่ไม่เที่ยงตรงได้ ซึ่งเบื้องต้นสามารถตรวจได้ 2 วิธี
1.1. Plot กราฟจากข้อมูลตัวแปรตาม (Y) และตัวแปรต้น (X) เพื่อดูความสัมพันธ์เชิงเส้น
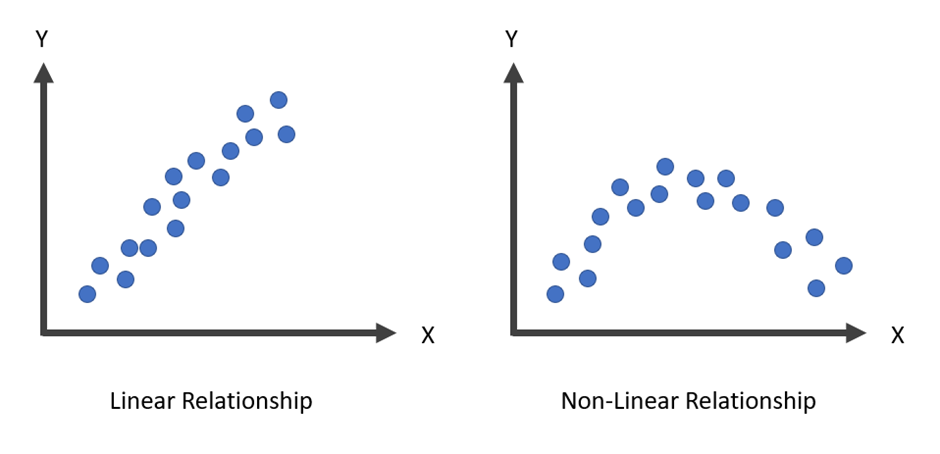
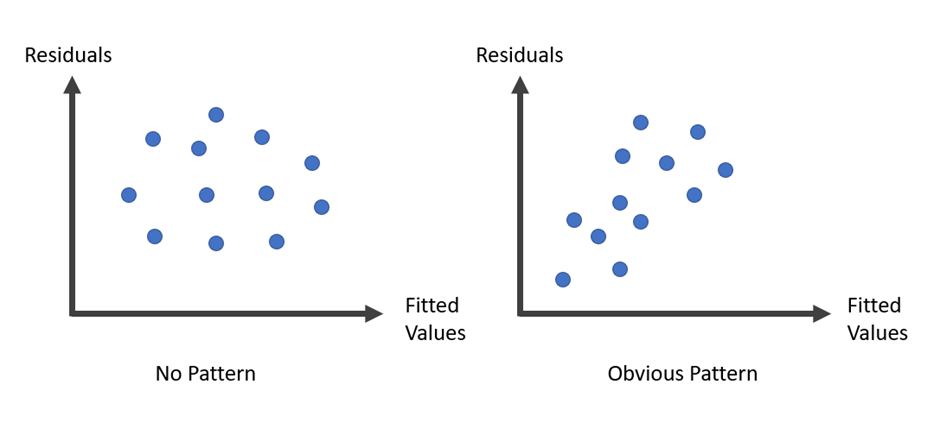
1.2. Plot กราฟจากค่าความคาดเคลื่อนของตัวแปรตาม (Residual) เทียบกับตัวแปรตามจากข้อมูลจริง โดยจะต้องไม่พบ pattern ของข้อมูลที่เด่นชัด ว่ากันง่าย ๆ ก็คือ ความคาดเคลื่อนของโมเดลไม่ควรจะมีแนวโน้มอะไรเลย เนื่องจากความคาดเคลื่อนของแต่ละจุดไม่มีความสันพันธ์กัน
โดยในการแก้ไขปัญหาดังกล่าว ให้ลองแปลงข้อมูลเป็นในรูปแบบต่าง ๆ เช่น logarithm, หรือ เพิ่มลดเลขยกกำลัง หากเป็นการแปลงข้อมูลที่เป็นตัวแปรตาม ให้วิธี box-cox transformation ในการหาวิธีการแปลงที่เหมาะสม โดยสามารถทำได้โดยเลือกค่าประมาณ lambda ที่ให้ค่า log-likelihood สูงสุดจากกราฟ box-cox แล้วนำไปเทียบกับตารางแปรผล box-cox เพื่อหาวิธีการแปลงค่าตัวแปรตามที่เหมาะสม
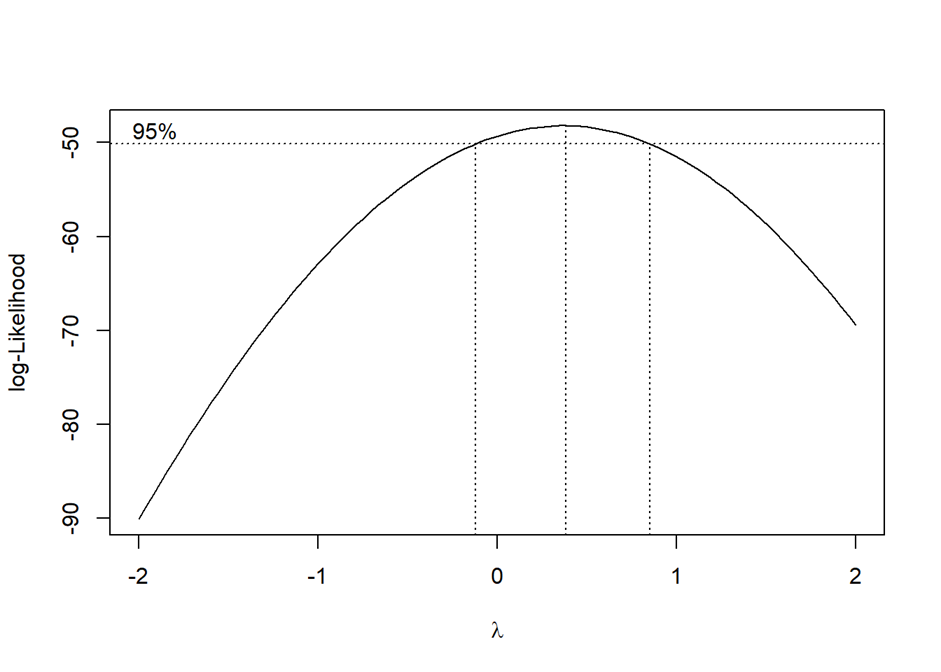
(แหล่งที่มาจาก RPubs)
| Lambda value (λ) | Transformed data (Y’) |
|---|---|
| -3 | 1/Y3 |
| -2 | 1/Y2 |
| -1 | 1/Y |
| -0.5 | 1/√(Y) |
| 0 | ln(Y) |
| 0.5 | √(Y) |
| 1 | Y |
| 2 | Y2 |
| 3 | Y3 |
2. การตรวจสอบการแจกแจงในรูปแบบปกติ (Normality Assumption)
ตรวจสอบการแจกแจงในรูปแบบปกติ (Normality Assumption) หากไม่มีคุณสมบัตินี้จะส่งผลให้ช่วงความเชื่อมั่นของข้อมูลมีความผิดพลาดได้ ซึ่งสามารถตรวจสอบได้ 2 วิธี
2.1. Plot quantile ของการแจกแจงของ residual เทียบกับการแจกแจงแบบปกติ แล้วจุดข้อมูลบนกราฟจะต้องไม่อยู่ห่างจากเส้น 45 องศา
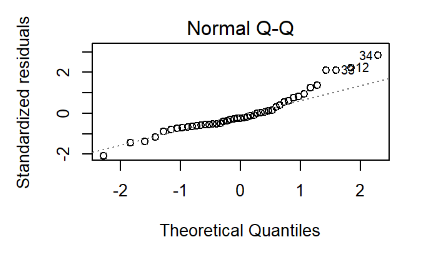
(แหล่งที่มาจาก RPubs)
2.2. ทดสอบสมมุติฐานบนโมเดลด้วย Shapiro-Wilk ซึ่งเป็นการทดสอบสมมุติฐานว่ากลุ่มข้อมูลตัวอย่างมาจากประชากรที่มีการแจกแจงแบบปกติหรือไม่ โดยมีสมมุติฐานว่างคือประชากรมีการแจกแจงแบบปกติ ซึ่งหลังการทดสอบจะต้องได้ข้อสรุปว่าไม่สามารถปฏิเสธสมมุติฐานว่างได้
โดยในการแก้ไขปัญหาดังกล่าว ให้ลองแปลงข้อมูลเป็นในรูปแบบต่าง ๆ เช่น logarithm, หรือ เพิ่มลดเลขยกกำลัง หากเป็นการแปลงข้อมูลที่เป็นตัวแปรตาม ให้วิธี box-cox transformation ในการหาวิธีการแปลงที่เหมาะสม โดยสามารถทำได้โดยเลือกค่าประมาณ lambda ที่ให้ค่า log-likelihood สูงสุดจากกราฟ box-cox แล้วนำไปเทียบกับตารางแปรผล box-cox เพื่อหาวิธีการแปลงค่าตัวแปรตามที่เหมาะสม หรือเลือกตัดข้อมูลที่ ไม่ได้เกาะกลุ่มแต่ส่งผลต่อโมเดล (influential point)
3. การตรวจสอบความแปรปรวนข้อมูลคงที่ (Constant Variance Assumption)
การตรวจสอบความแปรปรวนข้อมูลคงที่ (Constant Variance Assumption) หากไม่มีคุณสมบัตินี้จะทำให้ตัวประมาณในโมเดลและความคาดเคลื่อนมาตรฐานของข้อมูล มีการแจกแจงที่ไม่เป็นปกติ ซึ่งสามารถตรวจได้ 2 วิธี
3.1. Plot กราฟจากค่าความคาดเคลื่อนของตัวแปรตาม (Residual) เทียบกับตัวแปรตามจากข้อมูลจริง โดยจะต้องไม่พบ pattern เด่นชัด
3.2. ทดสอบสมมุติฐานบนโมเดลด้วย Breusch-Pagan ซึ่งเป็นการทดสอบสมมุติฐานว่าความแปรปรวนของค่าคลาดเคลื่อนคงที่หรือไม่ โดยมีสมมุติฐานว่างคือความแปรปรวนของค่าคลาดเคลื่อนมีความคงที่ ซึ่งหลังการทดสอบจะต้องได้ข้อสรุปว่าไม่สามารถปฏิเสธสมมุติฐานว่างได้
โดยในการแก้ไขให้เลือกใช้ Weighted Regression ซึ่งเป็นส่วนขยายของ Linear Regression Model ที่อนุญาตให้โมเดลให้ความสำคัญของแต่ละ record ในชุดข้อมูลไม่เท่ากัน โดยเราจะให้น้ำหนักสูงกับ record ที่มีความแปรปรวนของความคลาดเคลื่อน (Error Variance) ต่ำ และทำเช่นเดียวกันในกรณีตรงกันข้าม
4. การตรวจสอบความเป็นอิสระต่อกัน (Independence Assumption)
การตรวจสอบความเป็นอิสระต่อกัน (Independence Assumption) ระหว่างตัวแปรต้นหากไม่มีคุณสมบัตินี้จะส่งผลให้ช่วงความเชื่อมั่นของข้อมูลมีความผิดพลาดได้ ซึ่งสามารถตรวจได้ 3 วิธี
4.1. Plot กราฟจากค่าความคาดเคลื่อนของตัวแปรตาม (Residual) เทียบกับ เวลา แล้วไม่พบ pattern ของข้อมูล
4.2. กรณีข้อมูลเป็นอนุกรมเวลา ให้ทดสอบสมมุติฐานบนโมเดลด้วย Durbin-Watson ซึ่งเป็นการทดสอบสมมุติฐานว่าความคาดเคลื่อนมีการเกิดความสัมพันธ์ในตัวเอง (Autocorrelation) หรือไม่ โดยมีสมมุติฐานว่างคือ ไม่พบความสัมพันธ์ในตัวเองในชั้นแรก (First-Order Autocorrelation) ซึ่งหลังการทดสอบจะต้องได้ข้อสรุปว่าไม่สามารถปฏิเสธสมมุติฐานว่างได้
4.3. กรณีข้อมูลเป็นข้อมูลภาคตัดขวาง (Cross-sectional Data) ให้ทดสอบสมมุติฐานบนโมเดลด้วย Run Test ซึ่งเป็นการทดสอบสมมุติฐานว่าข้อมูลที่ได้จากตัวอย่างนั้นเกิดจากการสุ่มอย่างแท้จริงหรือไม่ โดยมีสมมุติฐานว่างคือ ข้อมูลเกิดจากการสุ่ม ซึ่งหลังการทดสอบจะต้องได้ข้อสรุปว่าไม่สามารถปฏิเสธสมมุติฐานว่างได้
โดยในการแก้ไขปัญหาดังกล่าวมีได้หลายวิธีดังนี้
- ตัดตัวแปรต้นโดยปรึกษาผู้เชี่ยวชาญข้อมูลที่เกี่ยวข้อง (Domain Expert)
- ตัดตัวแปรต้นที่มีความพันธ์กับตัวแปรต้นอีกตัวออก เนื่องจากทั้งสองมีความสัมพันธ์กันสูง โดยสามารถดูจากค่า VIF (Variance Inflation Factor) ของตัวแปรต้นตัวนั้นๆ ที่มีค่ามากกว่า 10 ก็สามารถตัดออกได้ โดยเลือกตัดค่าที่สูงที่สุดก่อน จากนั้นทำการคำนวณ VIF ใหม่เพื่อหาตัวแปรต้นที่ยังคงมีความสัมพันธ์กันสูงอยู่จนกระทั่ง ไม่พบตัวแปรที่มีค่า VIF เกินกว่า 10
- ใช้ Ridge Regression ซึ่งเป็นการปรับแต่งโมเดล Regression เพื่อให้โมเดลมีความเสถียรกับข้อมูลที่มีความสัมพันธ์กันเองมากยิ่งขึ้น
- ทำการลดมิติของข้อมูลด้วยวิธี PCA (Principal component analysis) โดยข้อมูลที่มีความสัมพันธ์กันสูงจะถูกยุบรวมอยู่ในมิติเดียวกัน
สู่ Linear Regression ที่มีประสิทธิภาพ
ทั้ง 4 คุณสมบัติข้างต้นนั้น เมื่อทำการตรวจสอบและแก้ไขอย่างถูกวิธีแล้วก็จะช่วยทำให้โมเดลของเรา ให้ผลลัพธ์ที่ถูกต้องแม่นยำมากยิ่งขึ้น นอกจากนี้ก็ยังทำให้เราสามารถแปลความหรือวิเคราะห์ความสัมพันธ์ของข้อมูลได้อย่างเหมาะสม สอดคล้องกับธรรมชาติหรือพฤติกรรมของข้อมูลอีกด้วย
อ้างอิง
Understanding Diagnostic Plots for Linear Regression Analysis
Box-Cox Transformation: Definition, Examples
Shapiro-Wilk Test: Definition, How to Run it in SPSS
Breusch-Pagan-Godfrey Test: Definition
Durbin Watson Statistic Definition
What is Run Test in Statistics – A Simple Explanation with Step by Step Examples
ปัญหาต่างๆในการทำ Regression Analysis
เนื้อหาโดย ไชยณรงค์ ทุมาภา
ตรวจทานและปรับปรุงโดย ปพจน์ ธรรมเจริญพร





Former-Editor-in-Chief at BigData.go.th and Senior Data Scientist at Government Big Data Institute (GBDi )









